极牛技术实践分享活动极牛技术实践分享系列活动是极牛联合顶级VC、技术专家,为企业、技术人提供的一种系统的线上技术分享活动。每期不同的技术主题,和行业专家深度探讨,专注解决技术实践难
极牛技术实践分享活动
极牛技术实践分享系列活动是极牛联合顶级VC、技术专家,为企业、技术人提供的一种系统的线上技术分享活动。
每期不同的技术主题,和行业专家深度探讨,专注解决技术实践难点,推动技术创新,每两周的周三20点正式开课。欢迎各个机构、企业、行业专家、技术人报名参加。
本期大纲
Redux +React是怎么一个运行机制;
如何使用这套框架来构建我们的网站;
在使用这套框架的过程中我们可能会踩到哪些坑,我们的性能会受到哪些影响。
嘉宾介绍
刘华清,GrowingIO核心工程师,负责GrowingIO整个前端工程的搭建。
北邮研究生,毕业后在微软 Office 部门工作 2 年,参与开发了 Office App 的整套 Ecosystem,以及 Office Word 的 Web 版本的相关 feature。对于前后端开发、软件工程、数据分析有自己较深刻的理解。
本期分享中刘老师提供了非常详细的资料,介绍了什么是React+Redux,作者从为什么要使用它到如何去使用它,以及再到解决实际问题所给出的方案。并且可以洞悉在开发中例如网站为何越来越慢等问题的症结所在,同时可以很清晰明了的理解React+Redux所具有的优势,以提高数据层计算的效率同时可以更智能化的避免不必要的Component渲染。
首先我们来看一下,什么是『Redux + React』。我们都知道前端的发展最近几年非常迅速,每一年都会有很多新技术出现。比如最近几年的 AngularJS,Vue,React+Redux。
这技术其中最核心的一个概念是数据绑定,记得没错的话最早提出数据绑定的应该是微软的WPF 技术,后来微软的一个工程师把双向概念应用到前端开发,并写出了Knockout 双向绑定框架。当时从jQuery转到使用数据绑定的概念的时候,感觉真的不可思议,太好用了。
后来就不断有更多的框架地采用数据绑定的概念,然后使得前端开发会越来越容易,整个的框架也有越来越清晰。
这里『Redux + React』也同样使用了数据绑定的概念,但它用的是单向数据绑定。
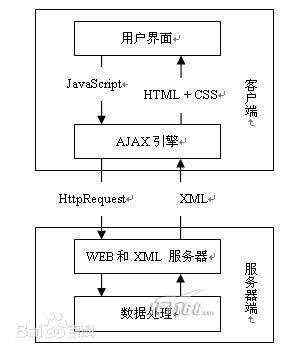
React是View层的框架,他负责将数据翻译成Dom;
Redux是可预测的数据存储层,他负责接收View 层发送过来的动作指令来进行数据的更新,当数据更新之后,React会负责将数据反应到页面中。这里的 Action、State、Reducer 都是Redux中的概念,分别代表动作指令,数据存储状态,对数据更新的代码。
所以我们可以看到,用户在点击了 View 层之后,View层会触发一些 Action 给Redux,Redux处理Action并更新数据之后,数据再被View层映射为Dom。既然已经知道[ Redux + React ] 是什么了,那我们就要考虑一下为什么我们选择[ Redux + React ],而不是选择 jQuery,AngularJS 或者 Vue 等框架。
[ Redux + React ] 两个非常核心的概念:
通过 [ Redux + React ] 来实现组件化;
实现单向数据流。
组件化方面,因为在 GrowingIO我们做的是一个企业级的应用,所以我们非常需要组件化的功能来将我们的业务模块化。所以在这一点上React很好地满足我们的需求,因为它有很丰富的组件库,也有Facebook的支持,而 jQuery就不在考虑范围之内了。
单向数据流方面,在我们使用的过程中,我们意识到单向数据流能让我们很清晰地把握系统中的数据流向,而不会产生太多的副作用。相较于双向绑定,由于数据的更改是由框架自动完成的,可能更多时候我们没有办法非常有信心的把控数据的更改。所以最终我们选择了[ Redux + React ]来完成我们的业务。AngularJs和Vue也就没再考虑。
既然决定开始使用[ Redux + React ],我们就在互联网上搜集了一些[ Redux + React ]最佳实践,在所谓的最佳实践中他们提到,要将所有的数据放在 Redux 层中,View层只做渲染和Action的调用。因为之前对单向数据流没有太多的经验,对 Redux 也只是 API 层面的了解,所以我们就按照这套最佳实践开始开发了。
整个开发过程还是比较顺利的,上图是我们开发出来的网站。因为这个过程中大家对数据放在哪,数据和页面该怎么交互,都非常清晰,所以开发过程还算比较顺利。但渐渐的当我们的网站越来越大的时候,我们遇到了一些性能和组件复用的问题。

随着网站越来越慢,性能优化就被提上了日程。经过我们的调研,发现上图中所谓的最佳实践存在以下三个问题:
由于我们将所有的数据都放在 Store 中,Store中的数据越来越大;
React层的渲染次数越来越多,React 纯变成了傻瓜式的组件,完全根据外界数据做组件渲染,本身并没有存储任何状态;
由于将所有的状态都存储在Store中,那么任何一次用户的交互,都会触发 Action的调用,从而使得Store中的数据被更新,一旦数据格式被更新之后,React的渲染次数也会变多;
这里还有一个副作用,这是由于将所有的状态数据都存储在 Store中,那么当一个组件被应用在其他页面的时候,这个组件就不是内聚的,它很难被很容易地应用其他页面。
所以针对以上几个问题我们提出了三大类的性能提升方案:
减少Store中的更新次数。比如我们可以将更少的数据放在Store中;
避免不必要的组件渲染。也就是说当数据被更新之后,如果相应的组件内的数据没有被更新,那么这个组件内部就不要进行重复的计算;
提高数据层的计算效率。在进行数据层计算的时候,避免不必要的计算。

这里将Store中的数据迁移到React层,这样可以充分利用React组件化的能力,使得不必要的数据不要再放在Store中。根据我们的经验,数据可以分为两大类,一类是业务数据,一类是UI数据,这里我们建议将业务数据存储在Store中,而UI数据如果可能的话可以直接跟组件写在一起。
什么是UI数据呢?这里我们举个例子,假如有一个过滤器控件,这个过滤器在编辑的过程中的临时信息存储在自己的组件内部,像这种组件强相关的信息,不要再存储在Store中。
这里也列出了我们自己的一些控件,比如时间控件,过滤器控件,图表控件。在使用这个控件过程中,一些UI信息和临时状态,就不要再放在Store中了,而是存储为控件本身的状态。这样整个页面的交互,会使得Store的更新次数大大减少。

还有一种想法是假如Store 中的数据更新了,这块数据会辐射到很多组件,但如果某一个组件内部所需要的数据没有被更新,那么我们是否可以避免这个组件不必要的计算。
在继续往下探讨之前,我们先来了解一下React的一个组件,有哪些关键的节点来判断是否进行下一步的数据计算,大家可以看上图。
shouldComponnetUpdate:当新的数据进来之后,React组件会调用一个函数。shouldComponentUpdate来判断是否进行下一步的渲染,所以我们可以在这个函数中做一些基本的判断,来决定是否要进行下一步的计算;
render:render函数是最核心的将子组件和数据组装在一起的关键函数,由这个函数来生成Virtual Dom;
Virtual Dom:Virtual Dom在被生成之后,会和上一次Virtual Dom进行比较,从而发现需要更新的浏览器Dom,再进行浏览器Dom的更新。
在了解了以上的React组件判断是否进行下一步的计算的关键节点之后,我们就可以针对这几个关键字点做优化。
我们先从shouldComponentUpdate这个关键函数入手,在这个函数中我们判断数据是否发生了变化,如果没有发生变化我们就不更新。这里有两种判断思路,一种是使用深度比较,另外一种是使用浅度比较。
深度比较很容易懂,就是对数据建行非常细致的比较,但这样比较的本身就比较耗费性能;
另外一种是浅度比较,这种比较方法只需要比较数据的引用是否发生变化即可,这种比较方法效率高但对于数据的更新和类型有一些要求。
这种数据结构需要满足一旦数据被更新了,那么它的引用也随之更新;而数据没更新,那么它的引用也不发生变化。这让我想到 Facebook 的ImmutableJS。
这里最直接的想法,就是我们在数据层直接使用 ImmutableJs,来达到上面我们提到的数据更新的效果。我们针对这种数据更新做了一些实践,以及替代的解决方案,在下一页PPT里面,我会进行相应的介绍。
在讨论数据的管理策略之前,我们这里再回顾一下 [ Redux + React ] 的整个数据流。当 Reducer 更新完数据之后,它是如何判断这些数据是否需要更新React层呢?这里上图中被放大的一层 [React-Redux],它负责比较本次的状态和上次状态的引用是否发生变化,只有引用发生了变化,我们才进行下一步的React的渲染。
所以 [ Redux + React ] 这个框架本身就期望我们在数据层即 Store 中,能够在更新数据之后,将引用同步更改。所以下面我们看看如何才能在数据层正确的更新数据以达到我们想要的效果:
第一种比较原始的办法,就是在更新数据之前,将整个对象进行拷贝,然后更改对象的内容,这样能够保证对象的引用发生了变化。然而深度拷贝是非常昂贵的,这是我们之前数据层计算效率降低的一个很重要的原因,因为一开始的时候数据量很小,我们没有意识到这个问题的严重性。而且又是在创业公司,短平快的出产品,快速的验证市场,才是那会儿公司的当务之急,所以在那个阶段我们没有过多的考虑。
第二个办法就是我们希望能够达到 ImmutableJs的效果,我们只更改需要被更新的数据引用。一种办法是直接使用 ImmutableJs;另外一种是自己手动做这件事情,但这样太麻烦,幸运的是 React 给我们提供了一个 react-addon-update 插件,可以很容易的实现对原生 Object 进行操作并达到我们想要的 ImmutableJs 的效果。
下面我就分别简单介绍一下 ImmutableJs 和 react-addon-update 是如何帮助我们达到这种数据更新效果的。
ImmutableJs是一套Facebook提供的数据结构,这套数据结构的数据无法被直接修改,数据一旦被修改它的引用也会相应发生变化。他内部使用了非常高效的算法能够复用很多数据,所以对ImmutableJs的数据更改非常高效。

大家可以在上图中看到,图里面的数据已经变成ImmutableJs了。这样对它的更新,都会将他的引用发生变化,看起来似乎我们的问题解决了。但其实并不然,ImmutableJS还是有很多限制的,如果你的项目环境不能满足这些限制,也会带来相应的问题。
一个就是因为他是一套新的数据结构,所以在操作的这套数据结构这个时候你不能用原生的JS API,需要去查询它的API来完成操作,但用它的API很多,很杂,而JS语言本身没有静态类型检查,在使用时候非常容易出错,所以这里建议可能需要配合Typescript等支持语法检查的语言一起使用,这样能够编译阶段检查出来问题;
第二个问题跟第一个问题可能有一点相似,就是ImmutableJS所生成的对象和原生的对象在写代码的过程中很难区分,这里同样建议使用Typescript来配合;
第三个就是使用 ImmuableJS生成的数据结构,无法使用现有的各种JS库来操作,这会带来很大的不方便。
针对以上的这个问题我总结一下可能的解决方案,第一个是配合Typescript等有静态类型检查的语言一起使用,第二个是约定命名变量规则,第三个是只在某个模块内部使用ImmutableJS,对外依然使用 Plain Object。
在GrowingIO 内部,因为一开始我们用的是ES6,所以我们并没有大规模使用ImmutableJS,只是在某些模块内部使用了ImmutableJS,比如某些数据量比较大的Reducer。

那怎么样才能在这个ImmutableJS和克数据之间找到一种中间方案呢。这里我要介绍一下 react-addon-update插件。这个插件结束两参数,一个是要更新的对象,另外一个我们叫做 spec,代指你告诉这个函数该如何更新对象。
使用这个插件来替代ImmutableJS的好处很明显就是这个插件操作的是Plain Object,虽然在更新操作上会稍微慢一点点,但是由于他们的数据结构没有发生任何变化,这使得实际代码过程中的数据一直都是Plain Object。
同时也没达到我们想要的 ImmutableJS的效果,所以如果一些同学像我们一样,代码已经在使用ES6编写了,可以尝试下这个插件。这样你在更新数据的时候就可以避免克隆操作,同时又能够达到ImmutableJS数据结构的效果,真是一举两得啊。
所以这里我们总结一下,在使用[ Redux + React ]的过程中,我们想要提高他的性能的话,可以从这三方面入手:
减少Store的更新次数,这个主要通过组件化来解决,UI数据和临时数据不要再存放在Store中;
避免不必要的 Component渲染,假设数据层能够提供准确的数据更新,即数据更新了,数据引用也会发生变化,数据没有更新,那么它的引用就不发生变化,这样的话我们可以在shouldComponentUpdate 函数中进行智能的判断师傅要进行进一步的计算;
第三步提高数据层的计算效率,通过使用 ImmutableJS 或者 react-addon-update 来达到只更新想要更新的数据。
Q&A
Q1:redux+react相比较vue,angluar有何优势?
A1:再进行选型的时候,我主要考虑几个点,一个是社区是否够强大,另外一个是当工程量比较大的时候,这个框架是否能够满足工程的需要。
社区方面:react由Facebook支持,并且已经有阿里等国内大公司也在支持,vue稍微偏小众,angular过于封闭了。
工程方面:redux+react单向数据流,在企业级应用会使得工程难度降低很多相对于 vue 和 angular 的双向数据流。
所以虽然 redux + react 咋开发小程序的时候,不如 vue 和 angular 快,但对于复杂网页的企业级服务应用来说,还是非常适合的。
Q2:redux更大的挑战来自如何设计action,设计state树形结构,有何经验分享?
A2:我倾向于将 redux 中的 state 分为两类,一类是后端数据缓存,跟后端的数据库中的概念进行映射,这种的单独做 reducer;另一类是前端页面相关的信息单独做一个 reducer。这样可以使得操作数据非常快。而且引用React 去引用数据也清晰。
action 命名很重要,需要有严格的 Namespace 的概念。比如操作数据缓存类的 reducer 以 CONCEPT_ 开头,操作页面数据相关的以 PAGE_ 开头。可以根据业务场景进行合适的命名空间的分区。
Q3:关于UI数据,比如刚刚讲到的日历,如果不放在store里,那点击后的时间怎么告诉其它组件渲染对应的数据呢?
A3:日历这种控件,在选择过程中的临时数据存储为 component 的state,直到用户点击确认按钮,才调用 action,将最终的时间同步到 store 中。
Q4:redux是典型的函数式编程思想,什么样的技术团队适合使用?
A4:事实上,写 React 和写 Java 非常像,Redux + React 单向数据流使得大项目的工程难度降低非常多,很多 Junior 的工程师,只要代码写得还不错,稍微学习一下就可以很快上手。当然要求工程师对 HTML && CSS 比较熟悉,才能把界面画好。
Q5: 关于redux性能优化问题,有使用reselect插件吗?
A5:使用了。reselect 和 redux-react 默认同样都是基于引用进行比较的。所以大家在操作 reducer 中的数据的时候,要保证引用随着数据同时被更新,不需要更新的数据引用也不要更新。比如使用 react-addon-update 或者 ImmutableJs 来加速这种数据效果的更新。
Q6: 关于deepclone? Object.assign 效率低吗?
A6:Object.assign 效率不低,属于shallowClone,但是如果对象数据有多层的话,就需要手动去做这件事情,才能保证上面提到的引用数据效果。使用 react-addon-update 或者 ImmutableJs 的话,代码看起来会比较简洁。




![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)


 京公网安备 11010802041100号
京公网安备 11010802041100号