作者:知知亦不知_710 | 来源:互联网 | 2024-12-07 17:15
一、背景介绍
当处理较小的文件时,可以直接将其加载到内存中进行处理。然而,对于大文件,如果尝试一次性加载全部内容,将会遇到内存不足的问题。例如,对于一个4GB的文本文件,尝试一次性读取会导致程序崩溃,如下图所示:
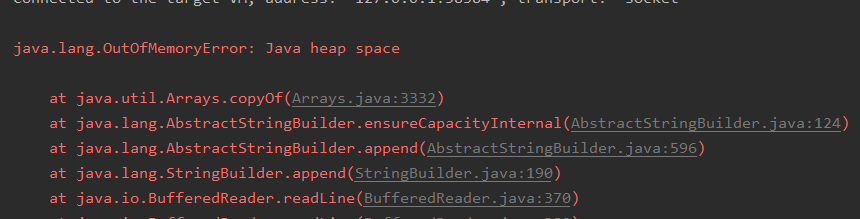
为了解决这一问题,我们需要采用分块读取的方法,逐步处理文件内容,避免内存溢出。
二、解决方案
2.1 单线程处理方案
单线程处理大文件时,可以使用缓冲流(BufferedInputStream)逐块读取文件内容,并在每次读取后立即进行词频统计。这种方式虽然简单,但效率较低,尤其是在处理非常大的文件时。下面是一个简单的实现示例:
public void singleThreadWordCount() throws IOException { BufferedInputStream in = new BufferedInputStream(new FileInputStream("word")); byte[] buf = new byte[4 * 1024]; int len = 0; Map total = new HashMap<>(); long start = System.currentTimeMillis(); while ((len = in.read(buf)) != -1) { byte[] bytes = Arrays.copyOfRange(buf, 0, len); String str = new String(bytes); StringTokenizer stringTokenizer = new StringTokenizer(str); while (stringTokenizer.hasMoreTokens()) { String strTemp = stringTokenizer.nextToken(); total.put(strTemp, total.getOrDefault(strTemp, 0) + 1); } } System.out.println(total.get("aabaa")); System.out.println("time: " + (System.currentTimeMillis() - start) + "ms"); }
上述代码展示了如何使用缓冲流逐块读取文件并进行词频统计。测试结果显示,单线程处理4GB文件的时间约为81740毫秒,统计到的词频次数为319783次。
2.2 多线程处理方案
为了提高处理大文件的效率,可以采用多线程的方式。通过将文件分成多个部分,每个部分由不同的线程独立处理,最后汇总各个线程的统计结果。这种方式可以显著提升处理速度。下面是一个多线程处理的示例:
public class MultiThreadWordCount { private static final ForkJoinPool pool = ForkJoinPool.commonPool(); public void run(String fileName, long chunkSize) throws ExecutionException, InterruptedException { File file = new File(fileName); long fileSize = file.length(); long position = 0; long start = System.currentTimeMillis(); ArrayList>> tasks = new ArrayList<>(); while (position > future = pool.submit(task); tasks.add(future); } HashMap totalMap = new HashMap<>(); for (Future> task : tasks) { HashMap map = task.get(); for (Map.Entry entry : map.entrySet()) { if (totalMap.containsKey(entry.getKey())) { totalMap.put(entry.getKey(), totalMap.get(entry.getKey()) + entry.getValue()); } else { totalMap.put(entry.getKey(), entry.getValue()); } } } System.out.println("time: " + (System.currentTimeMillis() - start) + "ms"); System.out.println(totalMap.get("aabaa")); } private static class CountTask implements Callable> { private final long start; private final long end; private final String fileName; public CountTask(String fileName, long start, long end) { this.start = start; this.end = end; this.fileName = fileName; } @Override public HashMap call() throws Exception { HashMap map = new HashMap<>(); FileChannel channel = new RandomAccessFile(this.fileName, "rw").getChannel(); MappedByteBuffer mbuf = channel.map(FileChannel.MapMode.READ_ONLY, this.start, this.end - this.start); String str = StandardCharsets.US_ASCII.decode(mbuf).toString(); StringTokenizer stringTokenizer = new StringTokenizer(str); while (stringTokenizer.hasMoreTokens()) { String strTemp = stringTokenizer.nextToken(); map.put(strTemp, map.getOrDefault(strTemp, 0) + 1); } return map; } } @Test public void testMultiThreadWordCount() throws ExecutionException, InterruptedException { MultiThreadWordCount counter = new MultiThreadWordCount(); counter.run("word", 1024 * 1024); } }
测试结果显示,多线程处理4GB文件的时间为115909毫秒,统计到的词频次数为320106次。尽管多线程处理的时间略长于单线程,但这主要是因为在合并各个线程的统计结果时存在一定的开销。通过调整分块大小,可以进一步优化性能。例如,将分块大小增加到20MB时,处理时间减少到26671毫秒,词频次数为320107次。
读者可以尝试调整分块大小,观察其对性能的影响。





 京公网安备 11010802041100号
京公网安备 11010802041100号