欢迎关注”生信修炼手册”!
除了利用aCGH和snp芯片来检测CNV之外,也可以通过NGS数据来分析CNV, 比如全基因组和全外显子测序。针对全基因组CNV的检测,还针对开发了一种称之为CNV_seq的测序策略,指的是低深度全基因组测序,只需要5X的测序深度,就可以有效的检测CNV。
本文根据一篇2015年的综述来简单介绍下全基因组CNV分析的策略,文章标题如下
Whole-genome CNV analysis: advances in computational approaches
链接如下
https://www.frontiersin.org/articles/10.3389/fgene.2015.00138/full
根据软件的基本原理,可以分为以下4大类别,图示如下
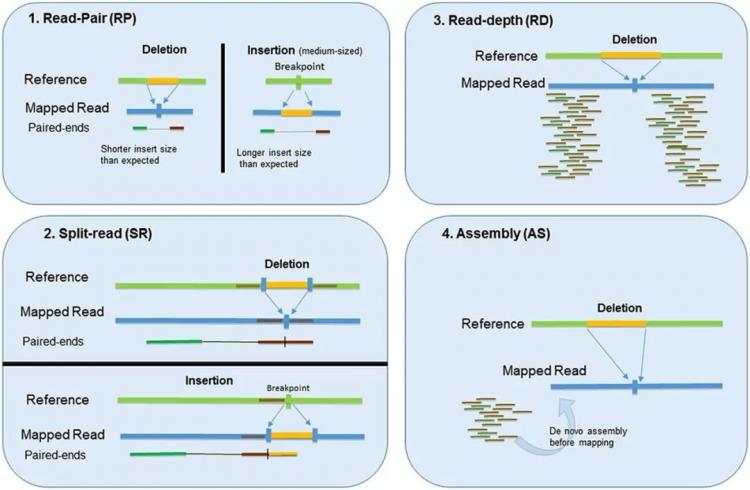
1. Read-Pair(RP)
RP是最早出现的算法,利用双端测序插入片段长度分布来检测CNV, 也称之为PEM,pair end mapping方法。双端测序插入片段长度分布如下图所示

当插入片段长度过长或者过短时,都代表着基因组发生了结构变异,如上图中的两个阈值,图示如下

以上两幅图来自文献Jan O. Korbel et al.Science 318, 420 (2007)
当计算出来的插入片段长度小于cutoff I时,说明相比reference, 实际检测样本中对应区域插入了部分碱基,相反地,如果计算出来的插入片段长度大于cutoff D时,说明相比reference, 实际检测样本对应区域插入了部分碱基。
受到测序读长的影响,该方法适用于检测中等长度的insertion和deletion, 对过小的插入不敏感,而且比较依赖比对的准确性,无法分析低复杂度的segmental duplication区域。
采用该策略的部分软件列表如下
BreakDancer
PEMer
Ulysses
2. Split-read(SR)
SR方法利用一端能够比对,另外一端比对不上的reads来识别CNV。另外一端比对不上,可能是存在CNV, 通过将单独的reads进行拆分,使其能够正确比对到参考基因组上,拆分的点就是CNV的断裂点。
只利用了单端reasd, 读长进一步受到限制,所以该方法只适用于检测小规模的插入和缺失,采用该策略的部分软件列表如下
Pindel
PRISM
SVseq2
Gustaf
3. Read-Depth(RD)
RD方法利用拷贝数和对应区域测序深度的相关性来进行分析,基本模型是缺失区域的测序深度相对低,而插入区域的测序深度相对高。该算法采用滑动窗口的方式,统计每个窗口内的测序深度分布,然后根据不同窗口测序深度的分布来预测CNV区域,图示如下

上图来自文献Genome Res. 2011. 21: 974-984
类似芯片中的log ratio值,在RD方法中,会根据区域对应的测序深度来判断对应的CNV数目。在该类方法中,滑动窗口的大小对结果影响较大,当窗口很大时,一些长度很短的small cnv信号就会被掩盖。
相比RP和SR两种方法,RD可以进行CNV分型,明确CNV的数目,RP和SR只能检测断点的位置, 而且RD可以检测大规模的CNV, 是目前较为主流的算法。采用该策略的部分软件列表如下
CNVnator
ERDS
ReadDepth
CNVrd2
4. Assembly(AS)
AS方法利用测序得到的短序列进行组装,将组装的contig与参考基因组进行比较,从而确定发生了结构变异的区域。组装的精确依赖测序读长和算法的准确度,而且组装对硬件资源的消耗特别大,并不是一个理想的CNV检测的算法,这里就不做过多的介绍了。
以上4种是最基本的算法理念,还有很多软件会综合其中的某几种算法来检测CNV, 比如speedseq中集成的lumpy软件,综合利用RP,SR, RD三种方式来检测CNV。
比对准确性是基于NGS的策略检测结果准确的前提,mapping的准确率和二代测序对基因组的覆盖度都会影响到CNV的检测结果,同时在计算测序深度时GC含量差异带来的PCR扩增偏移,也需要进行校正,通过设置对照样本,能够有效的减少系统误差的干扰,更好的进行CNV的检测。
综上所述,每种算法各有其优缺点,综合使用多种策略有助于提高检测结果的准确性和敏感性,同时设置对照样本,可以更加有效的分析拷贝数的变化。
·end·
—如果喜欢,快分享给你的朋友们吧—
扫描关注微信号,更多精彩内容等着你!









 京公网安备 11010802041100号
京公网安备 11010802041100号