

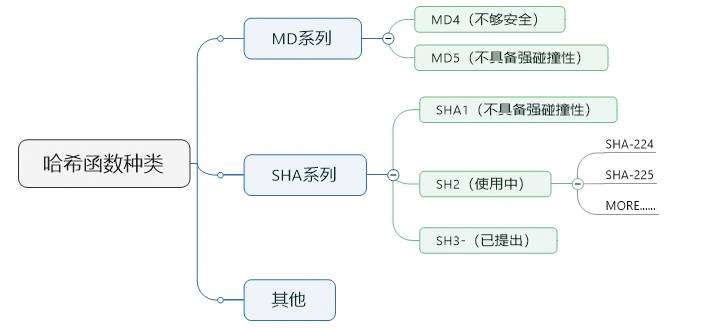
MD4(RFC 1320)是MIT的Ronald L.Rivest在1990年设计的,MD是Message Digest的缩写。其输出为128位。MD4已被证明不够安全。
MD5(RFC 1321)是Rivest于1991年对MD4的改进版本。它对输入仍以512位进行分组,其输出是128位。MD5比MD4更加安全,但过程更加复杂,计算速度要慢一点。MD5已被证明不具备“强抗碰撞性”。
SHA(Secure Hash Algorithm)并非一个算法,而是一个Hash函数族。NIST(National Institute of Standards and Technology)于1993年发布其首个实现。
目前知名的SHA-1算法在1995年面世,它的输出为长度160位的Hash值,抗穷举性更好。SHA-1设计时模仿了MD4算法,采用了类似原理。SHA-1已被证明不具备“强抗碰撞性”。
NIST还设计出了SHA-224、SHA-256、SHA-384和SHA-512算法(统称为SHA-2),跟SHA-1算法原理类似。
SHA-3相关算法也已被提出.

消息验证码基于对称加密,可以用于对消息完整性(integrity)进行保护。
基本过程为:对某个消息利用提前共享的对称密钥和Hash算法进行加密处理,得到HMAC值。该HMAC值持有方可以证明自己拥有共享的对称密钥,并且也可以利用HMAC确保消息内容未被篡改。
一般用于证明身份的场景
如Alice、Bob提前共享和HMCA的密钥和Hash算法,Alice需要知晓对方是否为Bob,可发送随机消息给Bob。Bob收到消息后进行计算,把消息HMAC值返回给Alice,Alice通过检验收到HMAC值的正确性可以知晓对方是否是Bob。注意这里并没有考虑中间人攻击的情况,假定信道是安全的。
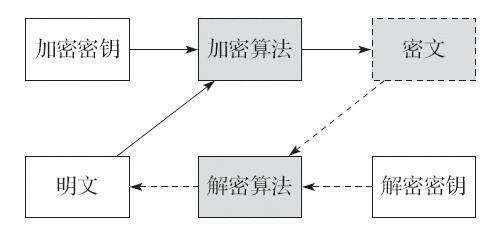
数字签名的全过程分两大部分,即签名与验证。一侧为签名,一侧为验证过程。
签名过程:发方将原文用哈希算法求得数字摘要,用签名私钥对数字摘要加密得数字签名,发方将原文与数字签名一起发送给接受方。
(Q: 为什么要将原文进行数字摘要之后,利用私钥和摘要,对原文进行签名,而不是直接用对原文进行签名?
A:原因有二:
一是因为非对称加密算法的加密速度,远小于对称加密速度。直接对原文进行签名,消耗较大;而是因为非对称加密,对加密信息的长度,有着严格的要求,只能用于少量数据的加密。比如,RSA加密算法,要求加密的数据不得大于53个字节。
)
验证过程: 收方验证签名,即用发方公钥解密数字签名,得出数字摘要;收方将原文采用同样哈希算法又得一新的数字摘要,将两个数字摘要进行比较,如果二者匹配,说明经数字签名的电子文件传输成功。
用于防止消息篡改的场景
Alice通过信道发给Bob一个文件(一份信息),Bob如何获知所收到的文件即为Alice发出的原始版本?
Alice可以先对文件内容进行摘要,然后用自己的私钥对摘要进行加密(签名),之后同时将文件和签名都发给Bob。
Bob收到文件和签名后,用Alice的公钥来解密签名,得到数字摘要,与收到文件进行摘要后的结果进行比对。
如果一致,说明该文件确实是Alice发过来的(别人无法拥有Alice的私钥),并且文件内容没有被修改过(摘要结果一致)
在非对称加密中,公钥可以通过证书机制来进行保护,但证书的生成、分发、撤销等过程并没有在X.509规范中进行定义。在实际工程中,安全地管理和分发证书可以遵循PKI(Public Key Infrastructure)体系来完成。PKI体系核心解决的是证书生命周期相关的认证和管理问题,在现代密码学应用领域处于十分基础和重要的地位。在HyperLedger-Fabric区块链系统中,就是用PKI体系来对证书进行管理的。
1,一种是由CA直接来生成证书(内含公钥)和对应的私钥发给用户;
2,另一种是由用户自己生成公钥和私钥,然后由CA来对公钥内容进行签名。
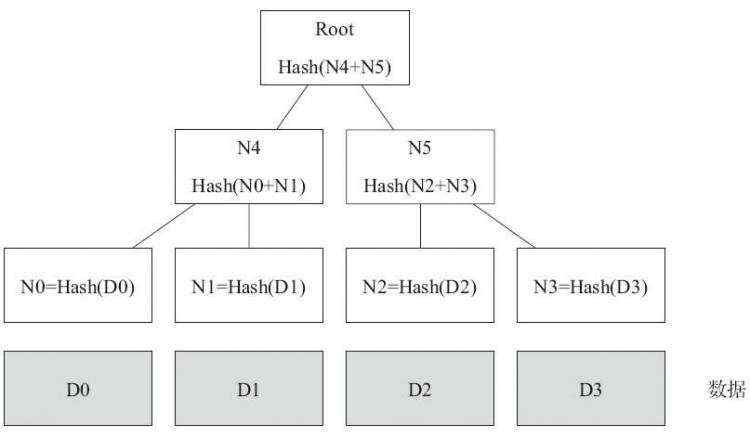
· 最下面的叶节点包含存储数据或其哈希值;
· 非叶子节点(包括中间节点和根节点)都是它的两个孩子节点内容的哈希值。
1.快速比较大量数据
2.快速定位修改

假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。
对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。
查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。
可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。

A和B两个用户。A需要把自己的数据给B处理。
有两种方式:
方式一:A把自己的数据进行加密,发送给B。B将数据解密后,对数据进行处理,然后得到目标结果Result。最后把处理后的结果发送给A。
方式二: A把自己的数据进行加密,发送给B。B直接对加密的数据,进行处理,然后得到处理的结果Result*.A收到Result*之后,通过私钥解密Result*,最终得到Result。
方式二用到的方法,就是同态加密。
在方式二的方式中,B完成了对A数据的处理目的,并且保证了A用户的隐私!








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 