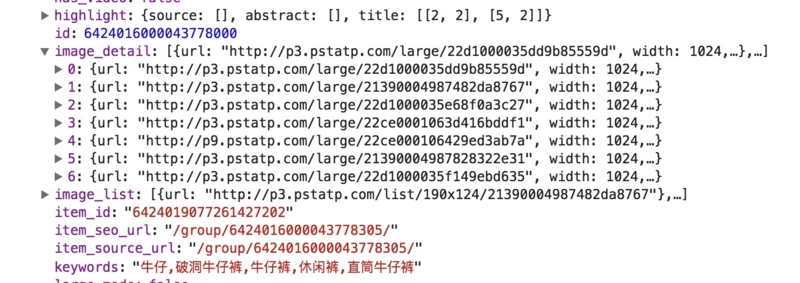
def get_images(json): if json.get('data'): for item in json.get('data'): title = item.get('title') images = item.get('image_detail') for image in images: yield { 'image': image.get('url'), 'title': title } Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
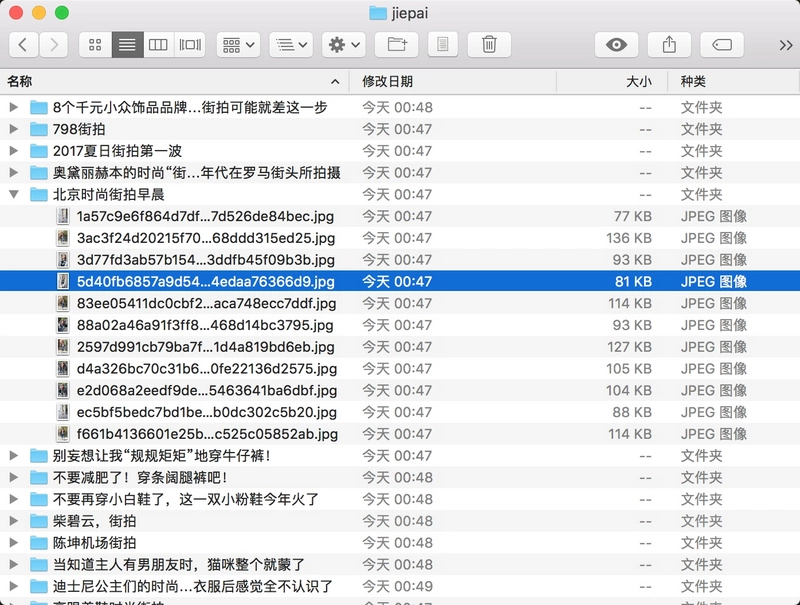
接下来我们实现一个保存图片的方法,item 就是刚才get_images() 方法返回的一个字典,在方法中我们首先根据 item 的 title 来创建文件夹,然后请求这个图片链接,获取图片的二进制数据,以二进制的形式写入文件,图片的名称可以使用其内容的 MD5 值,这样可以去除重复。
import os from hashlib import md5 def save_image(item): if not os.path.exists(item.get('title')): os.mkdir(item.get('title')) try: respOnse= requests.get(item.get('image')) if response.status_code == 200: file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(response.content) else: print('Already Downloaded', file_path) except requests.ConnectionError: print('Failed to Save Image')
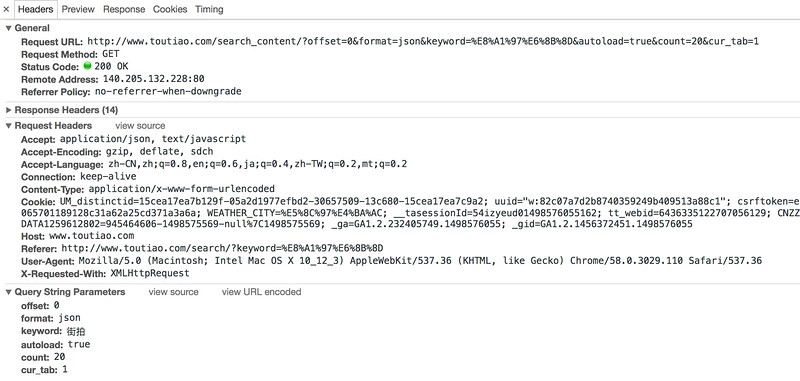
最后我们只需要构造一个 offset 数组,遍历 offset,提取图片链接,并将其下载即可。
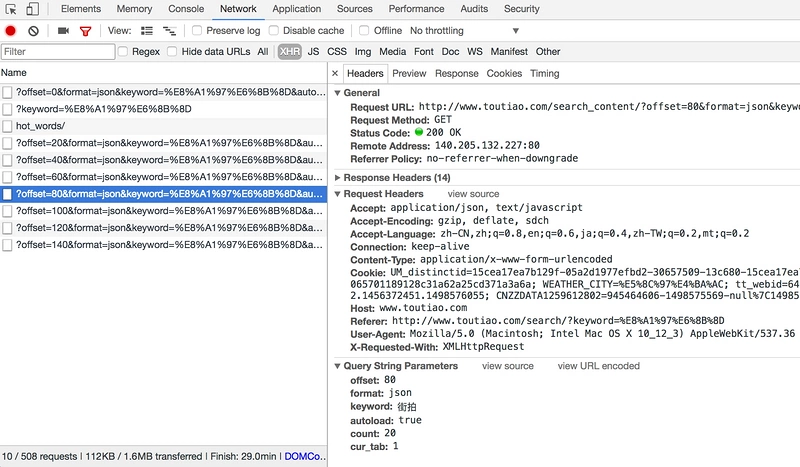
from multiprocessing.pool import Pool def main(offset): json = get_page(offset) for item in get_images(json): print(item) save_image(item) GROUP_START = 1 GROUP_END = 20 if __name__ == '__main__': pool = Pool() groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)]) pool.map(main, groups) pool.close() pool.join() Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎






 京公网安备 11010802041100号
京公网安备 11010802041100号