说明 假设我们拿到了一批数据(已经存储在neo4j中),如何通过图的方式实现其价值呢?
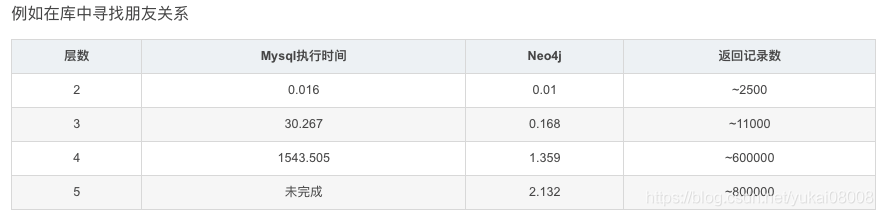
实现价值的途径 事实性质的查询。数据库本身的价值就是查询,所以建立了某种图库(或者说关系库)之后,那么第一个应用就是查事实。例如xx查、xx宝,在有了大量的股权关系后,你就可以查感兴趣的目标。但是这种价值一般来说附加值相对低,属于寡头垄断的行业,没什么意思。
模式的查询与目标问题的关联(强规则)。在这个简单查数据的基础之上,进行一些带有特定模式的
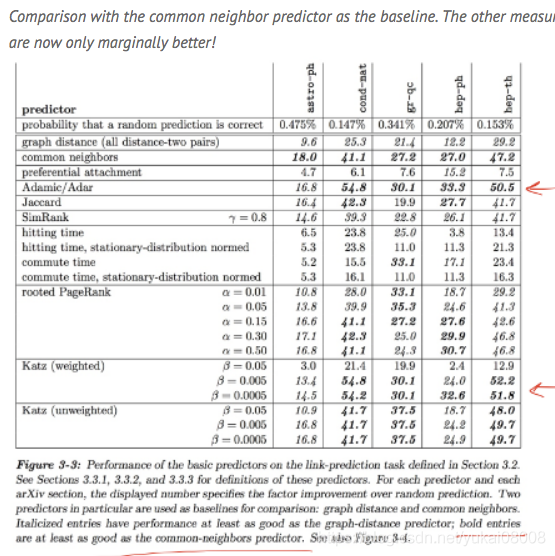
需要考虑的问题 0 图的重新构造 关于图的边计算方法有很多种,可以参考社交网络中的Link Prediction, 文章主要是参考What will Facebook friendships look like tomorrow?这篇文章的。
图距离 Graph Distance :一个最直接的预测方法就是计算两个结点间的距离,然后根据距离的大小来预测,两个结点越近那么就越容易在未来建立联系。 指数衰减距离 Katz (Exponentially Damped Path Counts):我们还可以考虑用x,y之间存在的路径的数量来衡量它们的距离。然而,路径有长有短,一般认为,那些很长的路径其实是没什么说服力的,于是引入指数衰减机制随着路径长度进行衰减。 命中时间(Hitting Time)从x出发,在附近随机的跳转,如果到达y,则记录下这次到达y的所需跳转次数。最后我们用 总跳转次数/到达y的次数 来表示距离。 模拟PageRank(Rooted PageRank)如果y是一个非常有影响力的人,那么很多人都能在非常少的跳转次数下到达y,为了减轻这效应,我们增加一个随机”reset”以及继续游走的机制。【这个MCMC非常相似】 共有邻居(Common Neighbors)当两个用户有着很多个相同的邻居,我们就认为这两个用户很有可能建立联系。 杰卡德相关(Jaccard’s Coefficient)然而Common Neighbors有一个很大的问题,假设有一个人有非常多的邻居,那么所有人都会倾向于预测跟他产生互动,为此,我们还要把他们邻居的数量考虑进去,于是我们认为,如果两个人共同邻居的数量在他们所有好友数量中占比越大,就认为可能建立联系。 频率权重的共同邻居(Adamic/Adar ,Frequency-Weighted Common Neighbors)。这个方法同样是对Common Neighbors的改进,当我们计算两个相同邻居的数量的时候,其实每个邻居的“重要程度”都是不一样的,我们认为这个邻居的邻居数量越少,就越凸显它作为“中间人”的重要性,毕竟一共只认识那么少人,却恰好是x,y的好朋友。 朋友的朋友测度(Friendes-mearsure)既然两个人有相同的好友可以表达他们间的距离,那么我们可以把这一个思想推广,我们认为,他们的好友之间很有可能互为好友。我们就计算他们好友之间互为好友的数量作为评价标准。 偏好联系(Preferential Attachment)如果两个用户拥有的好友数量越多,那么就越有可能更愿意去建立联系。也就是“富人越富”原则,基于这思想,用他们两个用户的好友数量的乘积作为评分。 0.1 直接距离 上面的1~4类关系属于直接距离,所以我们构建图的时候不是使用原始的数据(例如A-Invest->B),而是通过一些方法构建比较科学的「边」。在不同场景下可能适用不同的边。
0.2 间接距离 上面的5~9类属于间接联系,使用间接联系多少已经是在推断了(A-B并无“实边”)。综合起来看「频率权重的共同邻居」效果比较好(我比较喜欢简称这种间接为FWCN)
1 机器。使用我的局域网台式机 2 数据。50000+企业的60000+边的关系,存储在Neo4j中。 局域网台式机(14年的老机器了,很期待明年上AMD 5900/5950 12核/16核+128G 内存+ 3080显卡):
1 图的模式查询 这部分很灵活,可以针对全体图数据库查询,也可以对子图进行查询。通常来说,子图才是最好的基础单元。
六度分离(六度区隔)理论(Six Degrees of Separation):“你和任何一个陌生人之间所间隔的人不会超过五个,也就是说,最多通过五个人你就能够认识任何一个陌生人。”根据这个理论,你和世界上的任何一个人之间只隔着五个人,不管对方在哪个国家,属哪类人种,是哪种肤色。
图的模式查询和业务比较相关,我这里随便先来两个
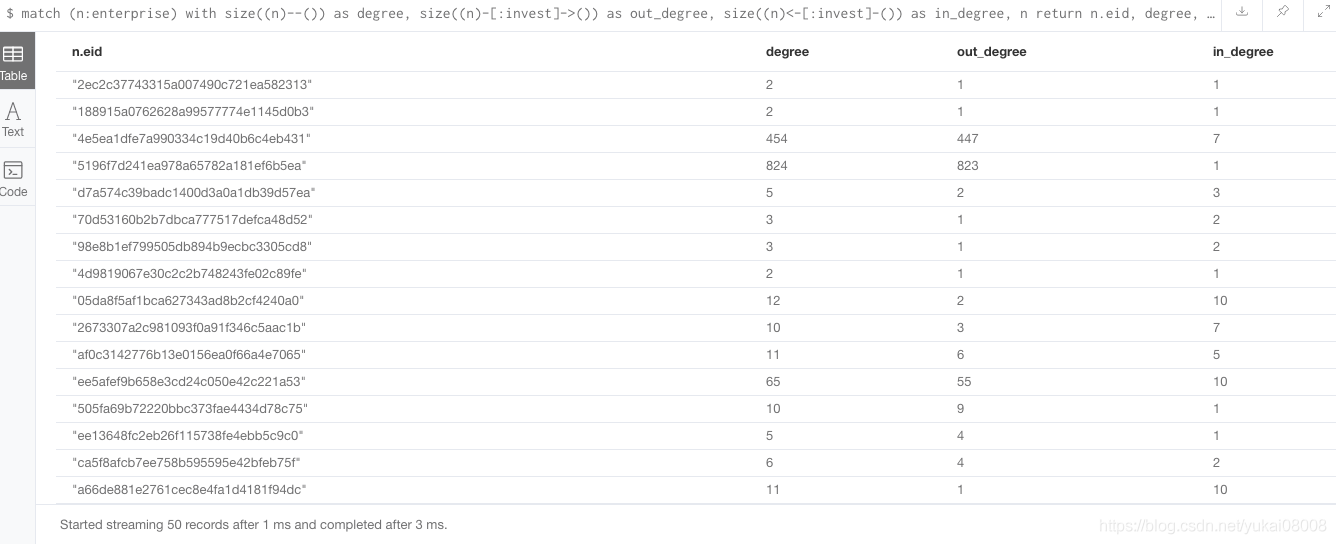
match ( n:enterprise) (( n) -- ( )) (( n) - [: invest]- > ( )) (( n) < - [: invest]- ( )) return n.eid, degree, out_degree, in_degree
2 聚类算法 2.1 按是否一次性计算 世界很小,图很大
2.1.1 All-in-Memory 在这个例子中,因为图的节点数和边数不超过10万,所以可以全图读入。
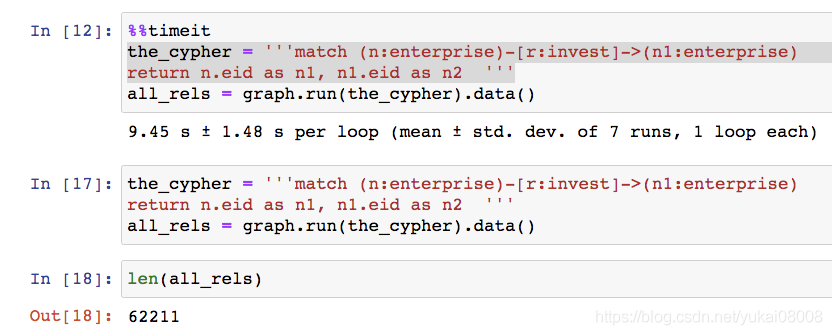
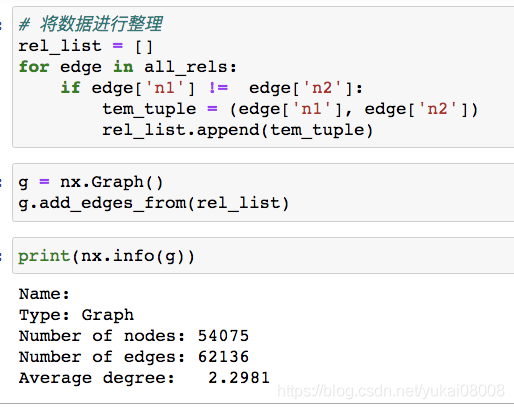
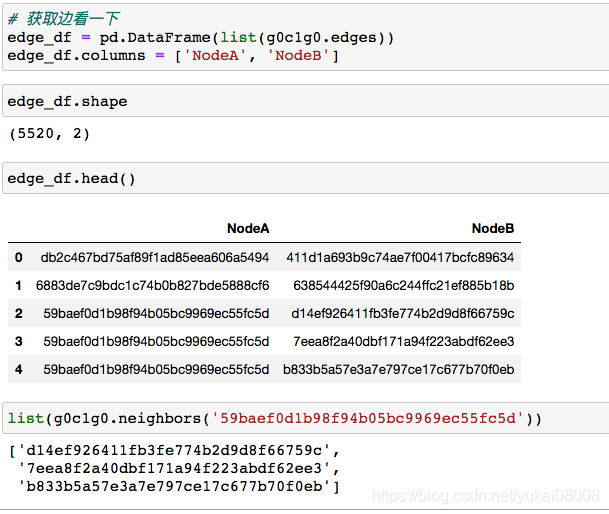
1 使用cypher语句读取所有的边 2 使用py2neo读进内存 3 使用networkx进行重新构建 获取所有边的cypher:
match ( n:enterprise) -[ r:invest] -> ( n1:enterprise) return n.eid, n1.eid
= &#39;&#39;&#39;match (n:enterprise)-[r:invest]->(n1:enterprise) = graph. run( the_cypher) . data( )
%%timeit魔法方法,给该步骤计算时间。
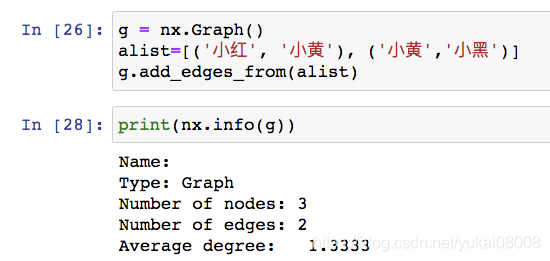
接下来就读入networkx包进行分析,networkx期望的格式如下:
2.1.2 Off-line 在实际应用中一定要考虑可以分批计算的离线算法:计算一批,存储一批,再计算一批。基本可以确定的是用动态规划的方法,具体怎么做我之后探索一下。
2.2 按聚类方法 先将数据读入
2.2.0 按连通性分割图 def get_conngraph ( C) : res = [ x for x in sorted ( nx. connected_components( C) , key= len , reverse= True ) ] return res= get_conngraph( g)
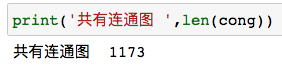
首先根据图本身边的连接性,可以把图分为若干个连通子图(连通图还是比较多的)。
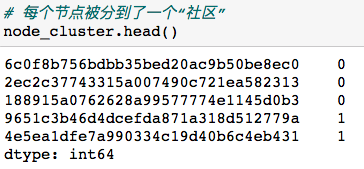
2.2.1 社区发现 根据已有的数据分为连通图相对是容易的,关键的一步是将连通的图再打散为若干个社区。从连通图再到社区的分割方法是不唯一的,这里只用常见(python调起来比较方便的方法)
= g_dict[ &#39;g0&#39; ] = community. best_partition( the_subg) = pd. Series( partition) = community. modularity( partition, the_subg) print ( &#39;Modularity is 模块度是用来判断分割的有效性的&#39; , mod) - - - is 0.8940344871302761
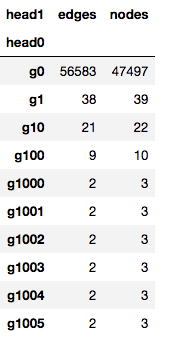
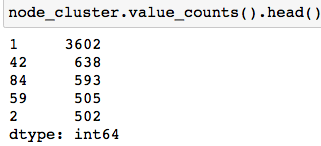
= g. subgraph( set ( node_cluster[ node_cluster== 1 ] . index) ) = get_conngraph( g0c1) = g. subgraph( g0c1g[ 0 ] ) print ( nx. info( g0c1g0) ) - - - : : Graph: 3602 : 5520 : 3.0650
如果图还是太大,那么可以迭代拆分,但拆分不会需要太多层级的(小世界)。
2.2.2 随机拆边 理论上可行,但是本次例子没有这样的需要。例如如果社区拆分不符合算法迭代指标(例如模块度)的要求,那么算法不可直接再拆分。但是从数据角度上,我们可以随机删掉10%或者20%的边,那么比较弱的关联就可能会被断开,从再次往下分。
3 分类算法 3.1 未见关系的推测 如果我们的数据中明确知道A认识B,那么我们可以通过查询获得这个事实结果。但有一种可能是A认识B,但是数据中并未显示,因此需要推断。
1 根据FWCN的算法通过for的方式计算结果 2 根据邻接矩阵的方式计算结果(计算主机上有32g内存,足够了) 当然我们要得到的结论是:A没有声称他认识B,但我们推断出了这样的结果。
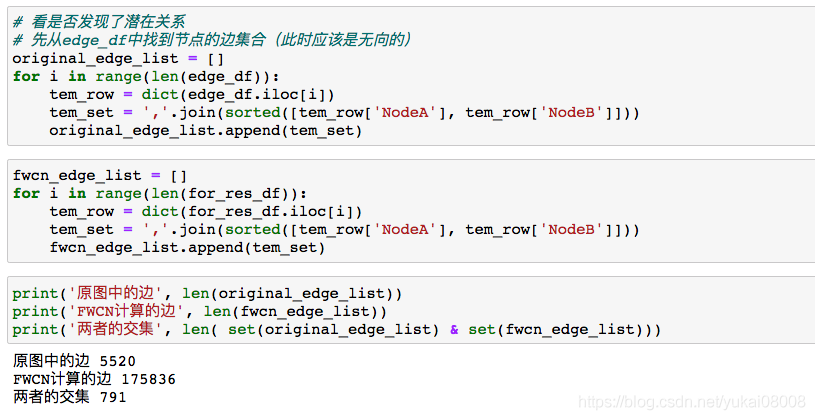
先看看对当前子图的边
假设要计算A和B之间的FWCN, 先找出A和B的共同朋友。然后计算这个朋友度的倒数作为权重,为了不发生溢出,所以使用了对数倒数替代倒数。
简单的来说,看A和B的关系怎么样,就挨个看看他们的朋友,多个朋友多条路。如果他们的朋友C本身就是社交狂,C的存在对于衡量A和B的关系就不大。如果朋友D是个比较内敛的人,总共就只有A和B两个朋友,那么对于衡量A和B的关系就是一个比较重要的权重。
def cal_FWCN ( g, A, B) : An = list ( nx. neighbors( g, A) ) Bn = list ( nx. neighbors( g, B) ) ABcn = list ( set ( An) & set ( Bn) ) w = 0 if len ( ABcn) : for cn in ABcn: tem_de = g. degree( cn) tem_w = np. log( tem_de) ** - 1 w += tem_wreturn w
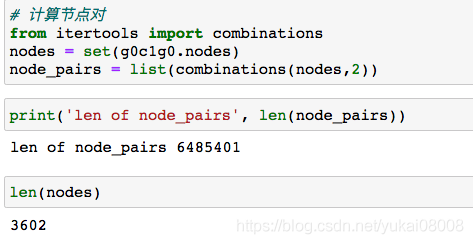
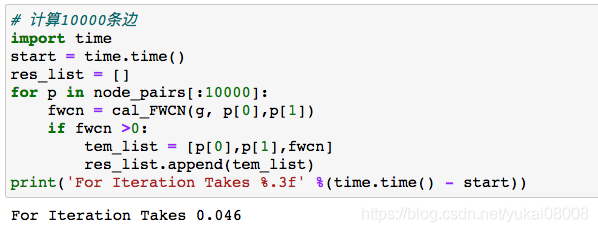
3.1.1 For循环计算 我们来看看需要计算的数量(看来产生了组合爆炸, 接近650万个可能边)
总共花了23秒,作为实验这个计算规模刚刚好。结果得到了17万条具有FWCN数值的边。
下面我们还要做两个测试,计算FWCN。虽然在这个例子中20多秒就算好了,但是如果节点是1万个的话可能就呵呵了。而且如果图的总规模是1亿个节点的话… (20s X 150 X 10000 = 3千万秒)
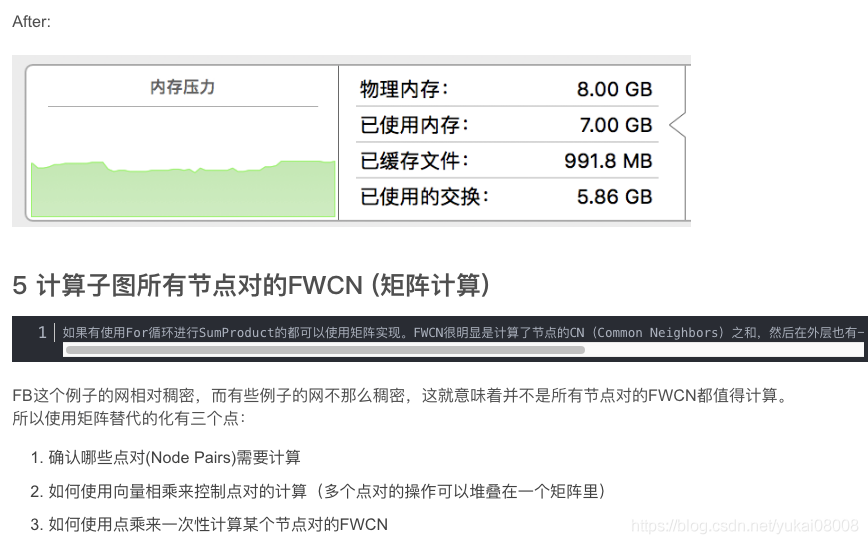
3.1.2 矩阵计算 矩阵计算本质上就是使用空间换时间,矩阵计算会使得单核满载。首先我们把图的关系表达为邻接矩阵,然后使用矩阵点乘替代for循环。特别注意:矩阵
对于1万个节点的子图, 其关系矩阵有1亿个元素,如果每个元素8字节,那么总共是800M大小。
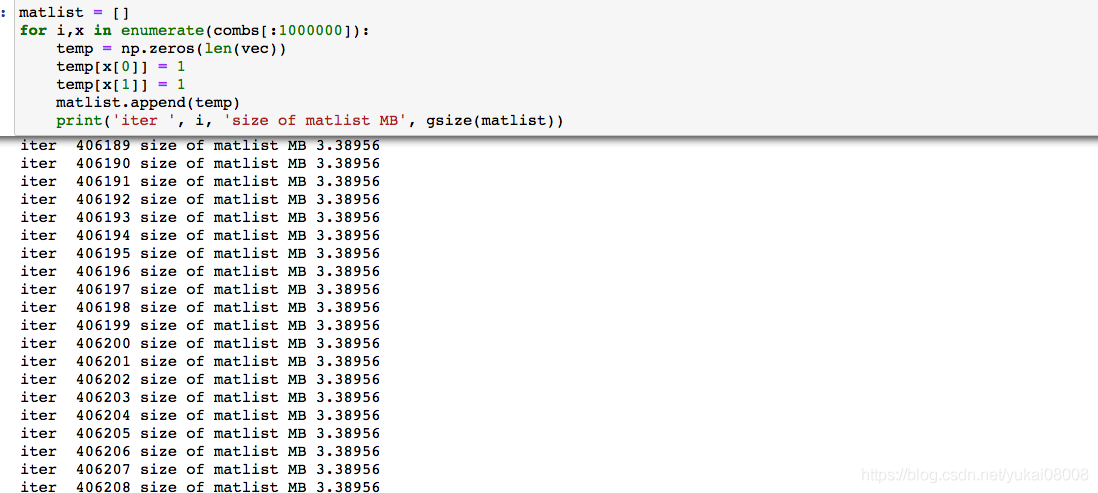
我之前犯了一个错误,用稀疏矩阵去作为选择向量。例如本例组合大约有650万种,每个组合为一个3600个元素的变量。这样点乘需要的格子数大约是234亿个,那么一次性的计算大约是187.2G的内存。
矩阵适合密集的计算,每个元素都要有实际意义。
另外我发现numpy的数据类型最好就是float的。实测情况是,当元素为int型,计算矩阵点乘的时间非常长,使用htop看到只有一个cpu核在工作;而为float型时计算非常快,所有的核都参与了计算。
矩阵计算的部分我需要进行一些修改, 不能直接蛮干(存在组合数)
for循环的方法中其实是蕴含这一步的,如果两个节点没有交集,那么就不去计算其邻居节点了。所以对于大量稀疏的关系,很快就跳过了。
另外,对于邻接矩阵的计算应该使用sparse方式(稀疏矩阵)。
–后补–
3.1.3 Cypher查询 如果我们使用cypher,第一步先用子图中的点进行匹配查询:
1 先筛选出具有共同朋友的关系 2 基于这些关系获取邻居节点的度 3 将数据返回来,再由python计算权值 本质上cypher也是在进行for循环计算,唯一可能有优势的是查询关系的速度,而对应的代价是传输数据的开销。
–后补–
3.2 未来建立关系的预测 本次例子中缺少时间变量,以后有机会再补。
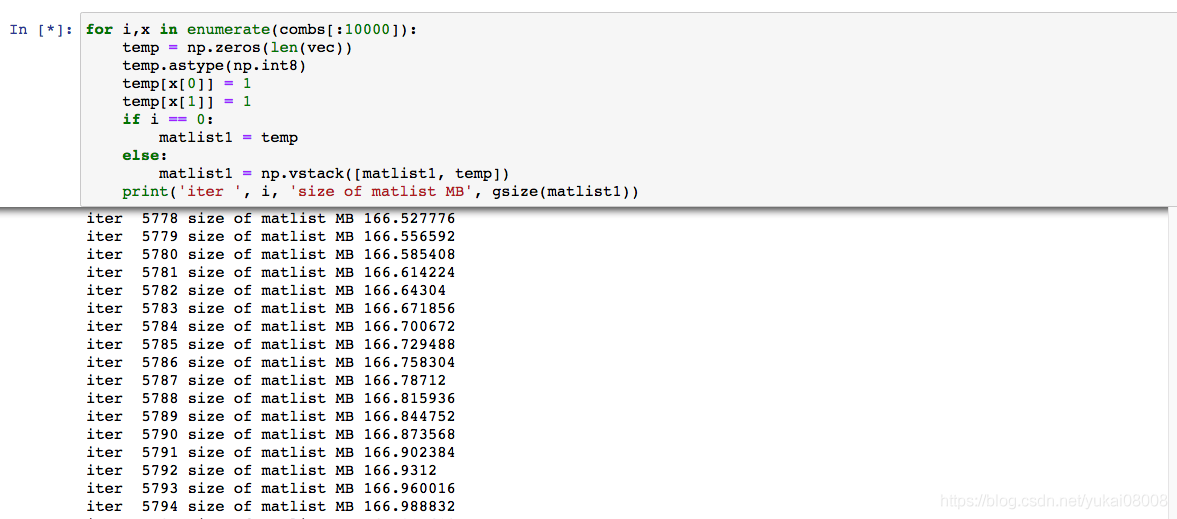
其他 这样的写法导致了内存的极速增加,每太理解原因。可以看到对于选择矩阵,叠加到40万行时其数据对象大小不过3.4M,但是内存直接飙到了10G。我猜是列表对象里面装了太多的numpy对象导致的。
使用np.hstack来进行纵向叠加,可以参考这篇文章。
解决方法:使用列表进行基本的向量元素拼接,变成一个矩阵后直接转换。
还有一个大坑…
没发现numpy的int类型点乘这么慢(感觉是计算机制是完全不同的),要转成浮点数算才快。以前没有注意过,大多数情况的确也是用浮点计算的。



















 京公网安备 11010802041100号
京公网安备 11010802041100号