本文由哈佛大学的YiheHuang在2020年发表于数据库顶会VIDB的一篇关于多核场景下内存事务数据库的优化手段的研究,获得当年的VLDB2020BestP
本文由哈佛大学的Yihe Huang在2020年发表于数据库顶会VIDB的一篇关于多核场景下内存事务数据库的优化手段的研究, 获得当年的 VLDB 2020 Best Paper Award。
摘要 乐观并发控制(OCC, Optimistic Concurrency Control)作为一种并发控制技术,可以让内存事务数据库没有写冲突(contention)或者冲突较少场景中,表现出很高的性能。然而写冲突会让性能明显下降,近期提出的一些并发控制设计,比如hybrid OCC/locking system和MVCC的变种,声称比最好的OCC系统性能还要好。我们选取了一些并发控制设计,并在不同的冲突程度、workload(包括TPC-C)对它们的性能进行评估,发现是一些与并发控制无关的因素导致到先前研究中OCC系统的性能下降情况。当这些因素都得到很好的实现后,OCC性能并不会在高冲突(high-contention)的TPC-C测试中出现崩溃。同时,我们提出了两种可以让OCC和MVCC在高冲突场景下性能得到大幅提升的技术,commit time updates 和 timestamp splitting,虽然这两种技术不是第一次出现,但是我们把它们成功应用在新的场景下,而且有新发现:当把两者结合的时候,MVCC有3.4倍的TPC-C性能提升,OCC有3.6倍的TPC-C性能提升。
1. 介绍 多核内存事务的系统的性能优化是当前的一个热门课题,已经有大量的相关研究被发表(读者可以查看原文获取 )。基于OCC的技术在通过共享内存带宽和避免不必要的内存写入的手段,可以在low-contention的场景获得很好的性能,然后在high-contention的场景中,大量的事务由于冲突而频繁abort,最坏的情况下,会出现contention collapse
这些优化技术需要面向workload针对性地设置参数,但是我们实际运用过程中,也没有花费太大的功夫。这些优化技术对TicToc、MVCC、OCC有帮助。虽然我们不是第一次提出这些技术的人,但是我们的变种是新的,我们首次把他们运用到TicToc和MVCC上。
2. 背景 STOv2基于STOv1[6]做了一些重构,具有良好的basic factor,并且支持插件式的并发控制方法。我们专注于三种并发控制方法的比较:1. OSTO, OCC的变种;2. TSTO, TicToc OCC变种;3. MSTO,MVCC的变种。
图1描述了STO的系统架构。STO同时使用了hash table和Masstree[7], hash table可用于实现主键索引、不需要有序性的索引,Masstrue用于实现二级索引、需要有序性的索引、支持范围查询。事务都是使用C++程序实现,访问事务型的数据结构,数据结构和STOv2的核心库保证了事务的线性一致性。事务以"one-shot"的方式执行:事务不需要和用户交互,因为在事务开始的时候,事务的参数都已知。我们不支持持久化和网络通信,因为和本文的主要关注点无关。
2.1 OSTO OSTO是一种OCC的变种(遵循Silo[8]的OCC协议)。在excution time,事务逻辑生成read set和write set;在commit time通过三个阶段来实现事务serializability:
阶段一 给write set中的记录加锁,加锁失败则abort事务。选择事务时间戳,标记serialization point阶段二 校验read set中的记录,如果有被其他事务修改过或者加锁,则abort事务阶段三 给write set中的记录增加新版本,更新写时间戳,释放锁OSTO在实现的时候,尽量避免memory contention,比如以一种scalable的方式选择事务时间戳,避免持有全局状态字段的引用。使用Read-copy-update(RCU)技术[9]来进行内存回收,可以让事务继续安全访问已经被逻辑删除的记录,可以大大地降低读写冲突。RCU需要一种可以识别什么时候被逻辑删除对象可以被安全释放的技术。
图2列出了三种变量。为了标记对象删除,有个事务跑在一个线程th上,将那些对象记录在一个列表上,记录他们的free timestamp为
然而这些是以内存开销为代价的,增大了内存分配、垃圾回收、处理器cache的压力,内存原子操作在MSTO中会比在OSTO中使用得更加频繁。
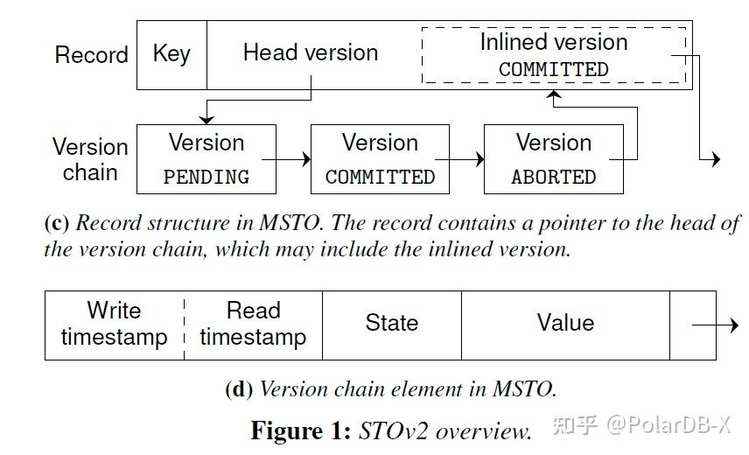
MSTO使用索引将主键映射到记录,引出一个叫version chain(上面C图所示)的跳转层。一条记录由一个key和可以指向连表中头版本的指针。每个版本包含:写时间戳、读时间戳、一个状态、以及记录的数据和链表中的指针。写时间时间戳代表着事务时间戳,读时间戳表示该记录最近被读取某个已提交事务读取,该事务的时间戳。提交链表:
在每个case中单独修改一个factor,该factor实现选自之前的系统,可以看出high-contention的TPC-C的workload中,四个基本要素能有20%的性能影响,有两个要素导致崩溃。在TSTO和MSTO也有类似的结果,其中内存分配器对MSTO性能影响更大(多版本消耗占用更多内存)。
下图所示,通过实验和代码分析,比较了8个系统的7个要素(STOv2为基准):
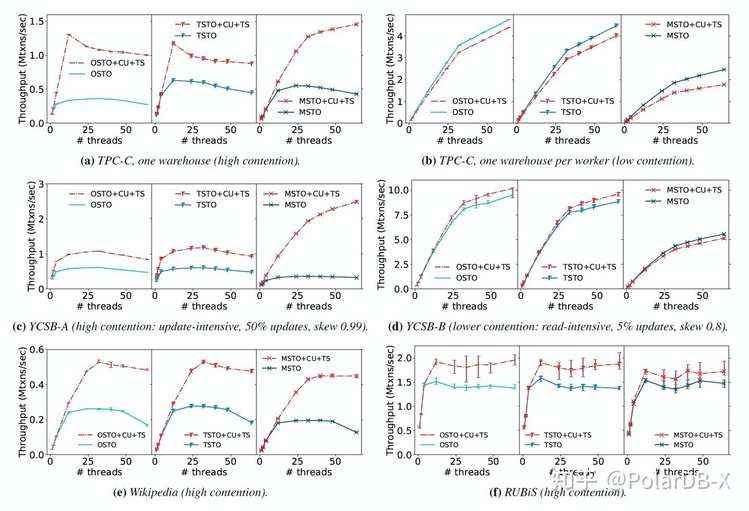
5. 并发控制评估 针对发现的对性能有很大影响的一些基本要素,我们都在STOv2进行了很好地实现,通过修改它的并发控制策略,来评估不同并发控制策略的表现。 先前的研究工作表明,在high-contention的TPC-C负载中OCC的性能发生了崩溃,而在本次性能评估中并没有发现这个现象。在high-contention的TPC-C负载中,即使在64线程下,OSTO的吞吐量大约是MSTO的60%。没有任何一个系统是可扩展的,也有没有崩溃的。在low-contention的情况下,OSTO的吞吐量大约是MSTO的2倍。评估结果如下图所示:
6. 在high-contention下的优化 我们的commit-time update(CU) 和 timestamp splitting(TS)优化技术可以减少很多来自workload的冲突。在我们的性能评估中,在各个系统,各种workload下,这两个优化都能让性能提升,有的case显示有大幅提升。他们还展示了协同作用,在一些workload下,TS使CU更加高效。由于这两个优化技术需要根据workload来调整,因此需要事务的编程者付出一些努力。CU和TS也减少了一些并发控制协议无法免去的冲突,比单独只有并发控制协议的情况下的性能有较大提升。
6.1 Commit-time updates OCC和MVCC系统中有很大一部分读写集合是read-modify-write操作,比如自增操作,读取一个旧的值,然后写入一个新的值。然而这么操作会导致不必要的冲突,我们通过盲写(写集合中标记下,表示事务提交的时候需要被自增一下),来避免记录进入事务的读集合,从而可以减少很多冲突。 STOv2中的commit-time update特性将特定的read-modify-write操作表示成各种盲写操作。updates表示对一个记录类型的操作,写集合中,可以是一个值,也可以是一个updater。每个updater都表示基于一条记录和参数所进行的操作,不能访问其他记录,而一个事务可以产生多个updater。如过下图所示,是一个操作stock记录的updater:
OCC和TicToc的updater可以在commit时候的第三个阶段,也就是相关记录已经被锁住的时候,被调用。而在MVCC中,updater被加入到版本链表中作为独立的实体,被称为delta version。当版本链表中存在delta version的时候,进行读取操作的时候,需要先进行flattening操作,得到最终的值。
6.2 Timestamp splitting 很多数据库记录有多个访问模式不同的片段组成。比如一条记录有很多列,有的列被频繁访问,而有的则不怎么被访问,或者他们具有不同的访问模式。Schema变更中的row splitting和vertical partitioning使用这种模式来减少数据库的IO开销,被频繁访问的字段会被缓存到内存里。timestamp splitting优化使用这些模式可以避免很多冲突。 timestamp splitting将一条记录拆分成几个子集,每个子集一个时间戳。当修改记录中的列的时候,只修改覆盖到了这些列的时间戳。如下图所示,频繁和不频繁访问的列都有自己的时间戳:
OSTO和MSTO通过上图的方式来实现timestamp splitting,然而MSTO则选用了更重量级的实现方式:将不同访问模式的列拆分到不同的表中,我们之后会想办法通过更轻量级的方式在MSTO上实现timestamp splitting。
7. 优化点的评估 我们进行了在TPC-C, YCSB, Wikipedia 和 RUBiS的流量负载下对优化后的STOv2进行了评估。
7.1 一起使用的效果 如下图所示,在high-contention的几种workload下,commit-time updates(CU)和timestamp splitting(TS)的结合都能让三种并发控制技术性能都有提升。在high-contention的TPC-C负载下,CU+TS的结合对三种CC技术可以有2到3.9倍的提升。在low-contention的TPC-C情况下,CU+TS对OSTO和TSTO产生了大约10%的性能开销,而对MSTO产生了约30%的性能开销,这是由于对长的delta version连表具有很大的垃圾回收的开销,可以在low-contention的情况下关闭MVCC系统的commit-time update(CU)优化。
7.2 分开使用的效果 下图,展示了两个优化点分别使用的效果:
可以发现的case下单独使用CU或者TS, 性能会下降,而同时使用CU和TS的时候又能使性能产生数倍的提升。那是因为很多被频繁更新的字段,只有那些不被频繁更新的字段使用了不同的时间戳的时候,才能通过使用CU来更新。
8. 结论 我们研究了三种用于提升主存事务处理系统在high-contention情况下的吞吐量的方法:基本要素的提升、并发控制算法、high-contention优化。不好的基本要素的实现,系统会在high-contention的情况下发生崩溃,流量跌0。当基本要素实现良好的时候,两项针对high-contention场景的优化:commit-time updates和timestamp splitting的优化提升比修改并发控制算法更有效果。CU和TS同时使用可以在TPC-C场景下使基本的并发控制算法提升到3.6倍,然而不同的未经优化的并发控制算法之间的差距也最多只有2倍。
我们当前的方案还不是最优的,不过受到CU+TS的优化点的启发,未来有可能出现一种可自适应worklad的并发控制算法会出现。提升high-contention场景下的主存事务的性能,最好的方式是减少冲突,虽然我们当前的方法需要人工参与,但希望未来的研究可以让CU和TS可以自动运行。
最后,我们被OCC无论在low-contention或者high-contention的场景下都有很好的性能所震惊,即使MVCC以及其他并发控制技术可能在某些workload下有绝对的性能优势。
引用 [1] T. Wang and H. Kimura. Mostly-optimistic concurrency control for highly contended dynamic workloads on a thousand cores. PVLDB, 10(2):49–60, 2016.
[2] X. Yu, A. Pavlo, D. Sanchez, and S. Devadas. TicToc: Time traveling optimistic concurrency control. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD ’16, pages 1629–1642. ACM, 2016.
[3] K. Kim, T. Wang, R. Johnson, and I. Pandis. ERMIA: Fast memory-optimized database system for heterogeneous workloads. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD’16, pages 1675–1687. ACM, 2016.
[4] H. Lim, M. Kaminsky, and D. G. Andersen. Cicada: Dependably fast multi-core in-memory transactions. In Proceedings of the 2017 International Conference on Management of Data, SIGMOD ’17, pages 21–35. ACM, 2017.
[5] J. M. Faleiro and D. J. Abadi. Rethinking serializablemultiversion concurrency control. PVLDB, 8(11):1190–1201,2015.
[6] N. Herman, J. P. Inala, Y. Huang, L. Tsai, E. Kohler, B. Liskov, and L. Shrira. Type-aware transactions for faster concurrent code. In Proceedings of the 11th European
[7] Y. Mao, E. Kohler, and R. T. Morris. Cache craftiness for fast multicore key-value storage. In Proceedings of the 7th European Conference on Computer Systems, EuroSys ’12, pages 183–196. ACM, 2012.
[8] S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden. Speedy transactions in multicore in-memory databases. In Proceedings of the 24th ACM Symposium on Operating Systems Principles, SOSP ’13, pages 18–32. ACM, 2013.
[9]P. E. McKenney and S. Boyd-Wickizer. RCU usage in the Linux kernel: One decade later. Technical report, 2012.
来源:阿里云社区


















 京公网安备 11010802041100号
京公网安备 11010802041100号