作者:谢超4444 | 来源:互联网 | 2023-08-15 07:13
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Pandas在当前行日期之前和之前扩展平均值相关的知识,希望对你有一定的参考价值。
我有一个Pandas数据帧如下
df = pd.DataFrame([['John', '1/1/2017','10'],
['John', '2/2/2017','15'],
['John', '2/2/2017','20'],
['John', '3/3/2017','30'],
['Sue', '1/1/2017','10'],
['Sue', '2/2/2017','15'],
['Sue', '3/2/2017','20'],
['Sue', '3/3/2017','7'],
['Sue', '4/4/2017','20']
],
columns=['Customer', 'Deposit_Date','DPD'])
。在下面的屏幕截图中计算Previous Mean列的最佳方法是什么?
该列是该客户的DPD年初至今的平均值。即包括所有DPD,但不包括与当前存款日期匹配的行。如果之前没有记录,那么它为null或0。
屏幕截图: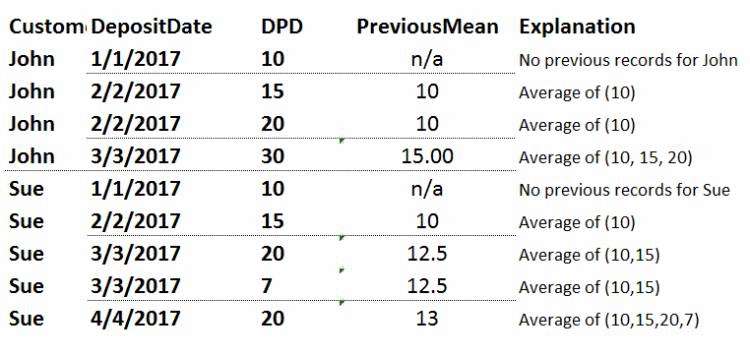
笔记:
- 数据按客户名称分组,并在存款日期上进行扩展
- 在每个组中,仅使用前一行中的值计算扩展均值。
- 在每个新客户的开头,均值为0或者为零,因为没有先前的记录可以形成均值
- 数据框按客户名称和Deposit_Date排序
答案
这是从平均计算中排除重复天数的一种方法:
# create helper series which is NaN for repeated days, DPD otherwise
s = df.groupby(['Customer Name', 'Deposit_Date']).cumcount() == 1
df['DPD2'] = np.where(s, np.nan, df['DPD'])
# apply pd.expanding_mean
df['CumMean'] = df.groupby(['Customer Name'])['DPD2'].apply(lambda x: pd.expanding_mean(x))
# drop helper series
df = df.drop('DPD2', 1)
print(df)
Customer Name Deposit_Date DPD CumMean
0 John 01/01/2017 10 10.0
1 John 01/01/2017 10 10.0
2 John 02/02/2017 20 15.0
3 John 03/03/2017 30 20.0
4 Sue 01/01/2017 10 10.0
5 Sue 01/01/2017 10 10.0
6 Sue 02/02/2017 20 15.0
7 Sue 03/03/2017 30 20.0
另一答案
而不是分组和扩展均值,过滤条件上的数据帧,并计算DPD的平均值:
Customer ==当前行的Customer
Deposit_Date <当前行的Deposit_Date
使用df.apply对数据帧中的所有行执行此操作:
df['PreviousMean'] = df.apply(
lambda x: df[(df.Customer == x.Customer) & (df.Deposit_Date axis=1)
输出:
Customer Deposit_Date DPD PreviousMean
0 John 2017-01-01 10 NaN
1 John 2017-02-02 15 10.0
2 John 2017-02-02 20 10.0
3 John 2017-03-03 30 15.0
4 Sue 2017-01-01 10 NaN
5 Sue 2017-02-02 15 10.0
6 Sue 2017-03-02 20 12.5
7 Sue 2017-03-03 7 15.0
8 Sue 2017-04-04 20 13.0
另一答案
好的,这是我迄今为止提出的最佳解决方案。
诀窍是首先在客户和存款日期级别创建一个包含移位平均值的聚合表。要计算此平均值,您必须先计算总和和计数。
s=df.groupby(['Customer Name','Deposit_Date'],as_index=False)[['DPD']].agg(['count','sum'])
s.columns = [' '.join(col) for col in s.columns]
s.reset_index(inplace=True)
s['DPD_CumSum']=s.groupby(['Customer Name'])[['DPD sum']].cumsum()
s['DPD_CumCount']=s.groupby(['Customer Name'])[['DPD count']].cumsum()
s['DPD_CumMean']=s['DPD_CumSum']/ s['DPD_CumCount']
s['DPD_PrevMean']=s.groupby(['Customer Name'])['DPD_CumMean'].shift(1)
df=df.merge(s[['Customer Name','Deposit_Date','DPD_PrevMean']],how='left',on=['Customer Name','Deposit_Date'])
另一答案
在这里找到了一个很好的解决方法:https://medium.com/jbennetcodes/how-to-get-rid-of-loops-and-use-window-functions-in-pandas-or-spark-sql-907f274850e4





 京公网安备 11010802041100号
京公网安备 11010802041100号