如果不归一化,各维特征的跨度差距很大,目标函数就会是“扁”的,图中椭圆表示目标函数的等高线,两个坐标轴代表两个特征。
在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路。 归一化后,那么目标函数就变“圆”了,每一步梯度的方向都基本指向最小值,可以大踏步地前进,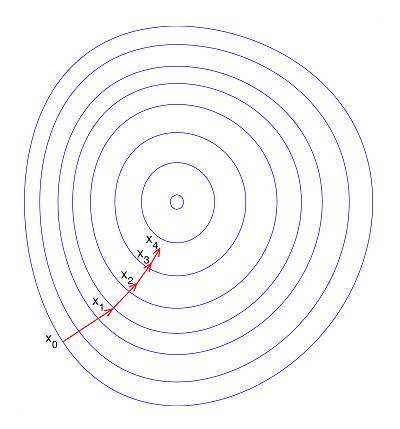 每一步梯度的方向基本都指向最小值,可以大踏步的前进。
每一步梯度的方向基本都指向最小值,可以大踏步的前进。
a="from.US.NY"
print('-'.join(a.split('.')[:2]))mm_ids = (123,456,789)
sql = "id in (%s) " % ','.join([str(x) for x in mm_ids])
print(sql)
from-US
id in (123,456,789) import pandas as pd
import numpy as np
pd.set_option('display.max_column',20)
pd.set_option('display.width',200)
np.set_printoptions(suppress=True)# 列表构造 DataFrame
ll = []
for i in np.arange(29):ll.append(result[result["Y"] == i].mean().values)
df_y_mean = pd.DataFrame(ll, columns=result.columns).T# 索引过滤
df_y_mean = df_y_mean[df_y_mean.index!='Y']# 像素
plt.rcParams['figure.dpi'] = 250
df_y_mean.plot(kind='bar', x='index', y=np.arange(29), subplots=True, figsize=(50, 320), grid=True, title="Event_Distribution",rot=90, fontsize=2)# 过滤空值 和 零值
df = df.dropna(subset=['lat','lng'], axis=0, how='any')
df = df[(df.lat!=0)&(df.lng!=0)]# 分组 标准差 分散值 线形图
grouped = df.groupby("mm_id",as_index=True)
grouped_gps = grouped[['mm_id','lat','lng']]
grouped_gps_std = grouped_gps.agg('std')
grouped_gps_std['disperse'] = grouped_gps_std['lat'] + grouped_gps_std['lng']
plt.figure()
grouped_gps_std.sort_values(by='disperse',ascending=True).set_index(np.arange(0,len(grouped_gps_std))).loc[:,'disperse'].plot(subplots=True,figsize=(10,5),grid=True,title="mm_id_gps_disperse")
plt.savefig("id_gps_disperse.png",dpi = 1000)# 快速构建 DataFrame
df=pd.DataFrame({'A':['foo','bar','foo','bar','foo','bar','yyy','xxx'],'B':['one','one','two','three','two','two','one','three'],'C':np.random.randn(8),'D':np.random.randn(8)})
# 将字符串类型的 dict list tuple 转化成原型
df_origin['action_num_map_dict'] = df_origin['action_num_map'].map(lambda x: ast.literal_eval(x))# 字典 构造 DataFrame
df_event = pd.DataFrame(list(df_origin.action_num_map_dict)).fillna(value=0)
df = pd.concat([df_origin.mm_id,df_event],axis=1) #默认按index粘连
df = df.set_index("mm_id",drop=True)# 列表成员 所在的位置
jb = [index for index,item in enumerate(df.columns.map(lambda x: x.split('.')[0]=='live')) if item==True] #包含'live'的column所在位置# 筛选特定列
df = df.loc[:,df.columns.map(lambda x: x.split('.')[0]=='live')]# 按行求和 按列求和
df = df[df.sum(1)!=0]
df = df.loc[:,df.sum()!=0]# 黏连
result = pd.merge(df,pd.DataFrame(labels,columns=['Y'],index=df.index),left_index=True,right_index=True)
snatch_or_lists = pd.merge(snatch,lists,on='momo_id',how='outer',suffixes=("_snatch","_lists"))# 列 类型转换
df_origin['action_num_map'] = df_origin['action_num_map'].apply(_to_dict)# if条件 列表推导
abnormal_id = [item for item in df_snatch['mm_id'] if item not in df_profile['mm_id']]# 在一个里面不在另一个里面
ids = snatch[~snatch.mm_id.isin(mm_id_profile)]
ids = lists[~lists.mm_id.isin(mm_id_profile)]# 两列 联合 求并集
def foo(d):xx = set(d.roomid_snatch)yy = set(d.roomid_lists) return len([item for item in xx.union(yy) if item])
hongbao_rooms = snatch_or_lists.groupby('mm_id').apply(foo)
hongbao_rooms = pd.DataFrame(hongbao_rooms,columns=['hb_rooms'])# 纵向堆叠 分组统计 进入的总房间数量
all = pd.concat([snatch[['mm_id','roomid']],lists[['mm_id','roomid']],shared[['mm_id','roomid']],profile[['mm_id','roomid']]],ignore_index=True).groupby('mm_id').nunique()# 列 重命名
all = all.rename(columns={"roomid": "all_nums"})# 分组统计 序列 转 dataframe
df = DataFrame({'key1':['a','a','b','b','a'],'key2':['one','one','one','two','one']}
)
print(df)
df['key2'].groupby(df['key1']).nunique().to_frame() key1 key2
0 a one
1 a one
2 b one
3 b two
4 a one
Out[20]:
key2
key1
a 1
b 2# 分组 去重统计 列命名
exit_rooms = exit['roomid'].groupby(exit['mm_id']).nunique().to_frame().rename(columns={'roomid':'exit_nums'})# 分组 按时间排序
df = snatch.groupby(['mm_id'],sort=False).apply(lambda df: df.sort_values(by='access_timestamp', ascending=True))# 保留首次出现
df_1st = df.drop_duplicates(["mm_id", "roomid"], keep='first')# 字符串时间 标准格式时间
start_date = datetime.strptime(end_date, '%Y%m%d') - timedelta(days=30)
start_date = datetime.strftime(start_date, '%Y%m%d')# 时间戳 转 字符串日期
df_month['day'] = df_month['timestamp'].apply(lambda x: datetime.fromtimestamp(x).strftime('%Y%m%d'))# 循环读取文件 黏连
pieces = []
columns = ['mm_id','timestamp','types']
for days in range_days(start_date, end_date):path = '/name1/name2/information_scan_%s.csv' %daysframe = pd.read_csv(path)frame['day'] = dayspieces.append(frame)
df = pd.concat(pieces,ignore_index=True)
# 均匀切分 分组统计
df_month = pd.DataFrame({'days': random.sample(range(0,30),10)})['days'] # 序列
factor = pd.cut(df_month,3)
def get_stats(group):return {'min':group.min(),'max':group.max(),'count':group.count(),'mean':group.mean()}
grouped = df_month.groupby(factor)
print(grouped.apply(get_stats))
grouped.apply(get_stats).unstack()
days
(1.974, 10.667] count 3.000000max 5.000000mean 3.666667min 2.000000
(10.667, 19.333] count 4.000000max 17.000000mean 14.750000min 12.000000
(19.333, 28.0] count 3.000000max 28.000000mean 26.000000min 23.000000
Name: days, dtype: float64count max mean min
days
(1.974, 10.667] 3.0 5.0 3.666667 2.0
(10.667, 19.333] 4.0 17.0 14.750000 12.0
(19.333, 28.0] 3.0 28.0 26.000000 23.0# 透视表
df_day = pd.pivot_table(df_day,index='mm_id',columns='day',aggfunc=len)# 分位点 统计
df_day.describe(percentiles=[0.25,0.75,0.85,0.90,0.95,0.99])# 字典
feature['event_summary'] = feature['event_summary'].apply(lambda x: {k: int(v) for k, v in x.items()})# Hash Trick 降维
h = FeatureHasher(n_features=50)
f = h.transform(feature['event_summary'].values)
df = pd.DataFrame(f.toarray(), index=feature.index, columns=np.arange(0, 50))
feature = pd.concat([feature, df], axis=1)# 缺失值 填补
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
imp.fit(feature['country'].values.reshape(-1,1))
feature.loc[:, 'country'] = imp.transform(feature['country'].values.reshape(-1, 1))# 独热码
df = pd.get_dummies(feature['gender'], prefix='gender_')# 二值化
binarizer = preprocessing.Binarizer(threshold=10)
feature['version'] = binarizer.transform(feature.version.values.reshape(-1,1))# 随机过采样
ros = RandomOverSampler(random_state=9)
X_train, y_train = ros.fit_sample(X_train, y_train)# 评估
precision = precision_score(y.values, y_pred, average='binary')
recall = recall_score(y.values, y_pred, average='binary')# 二值化
trainset['labels'] = trainset.SALE_ACTION_y.map(lambda x: np.sign(x))# 加权投票
lr = LogisticRegression(class_weight='balanced')
rf = RandomForestClassifier(oob_score=True, random_state=9)
gbm = GradientBoostingClassifier(random_state=9)
eclf3 = VotingClassifier(estimators=[('logistic regression', lr), ('randomForest classifier', rf), ('gbdt', gbm)],voting = 'soft', weights = [20, 95, 40])
eclf3 = eclf3.fit(X_train, y_train)
y_pred = eclf3.predict(X_test.values)# 日期
feature = pd.DataFrame({'register_time': ['20181212','20181112']})
feature['register_time'] = pd.to_datetime(feature['register_time'], errors='coerce')
feature['days'] = datetime.now() - feature['register_time']
feature['days'] = feature['days'].map(lambda x: x.days)
feature
Out[38]:
register_time days
0 2018-12-12 30
1 2018-11-12 60events = df.columns.map(lambda x: '.'.join(x.split('.')[:2]))
df.columns = eventscolumn_once=[]
column_all=list(df.columns)
for i in column_all:if column_all.count(i)==1:column_once.append(i)df_tmp = pd.DataFrame(index=df.index)
for item in set(df.columns):if item not in column_once:df_tmp=pd.concat([df_tmp,df[item].sum(1).to_frame(item)], axis=1)else:df_tmp=pd.concat([df_tmp, df[item]], axis=1)# Redis 写入
REDIS_HOST = '200.0.0.1'
REDIS_PORT = 4321
key = 'test1'
client = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)def update_redis(conn, key, data_set):origin_data = set()for member in conn.sscan_iter(key):origin_data.add(member)for member in (origin_data - data_set):conn.srem(key, member)time.sleep(0.01)for member in (data_set - origin_data):conn.sadd(key, member)time.sleep(0.01)# 分组 去重统计 转化
df = df.groupby('mm_id')['day'].nunique().to_frame().rename(columns={'day': 'days'})# 个数
df = df.groupby(['mm_id', 'day']).size()# 迭代器
df = pd.DataFrame(columns=['mm_id','timestamp','type'])
this, last = None, None
for index, row in df_origin_sort.iterrows():last = thisthis = rowif last is None:continueif (this.mm_id==last.mm_id) & (this.type=='downline') & (last.type=='online') & ((this.timestamp-last.timestamp) >= 4*3600):df = df.append([last,this],ignore_index=True)









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有