作者:mobiledu2502883463 | 来源:互联网 | 2023-08-14 22:11
竞赛信息竞赛是2018年于DataCastle举办的“达观杯”文本智能处理挑战赛竞赛地址:https:challenge.datacastle.cnv3cmptDetail.htm
竞赛信息
竞赛是2018年于DataCastle举办的“达观杯”文本智能处理挑战赛
竞赛地址:https://challenge.datacastle.cn/v3/cmptDetail.html?id=229
数据已经无法在官网上下载了,但是在kaggle上还有数据集,地址为:、
https://www.kaggle.com/datasets/mldatabase/datagrand-text-processing-challenge
本次竞赛的讲解为深度之眼公开课:https://www.bilibili.com/video/BV1fV411y76E/?spm_id_from=333.337.search-card.all.click&vd_source=ec0dfe3d40081b44c0160eacc0f39d0f
NLP文本分类的思路
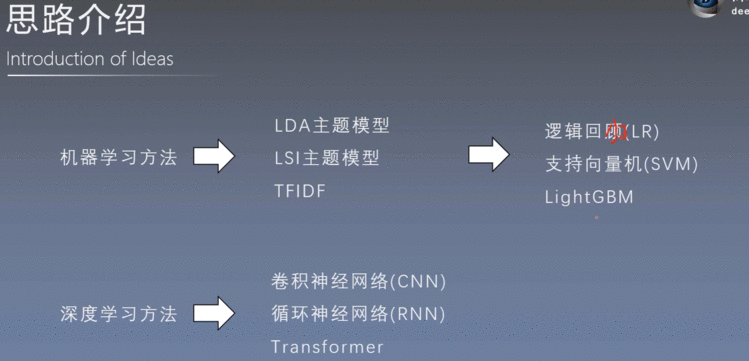
数据预处理
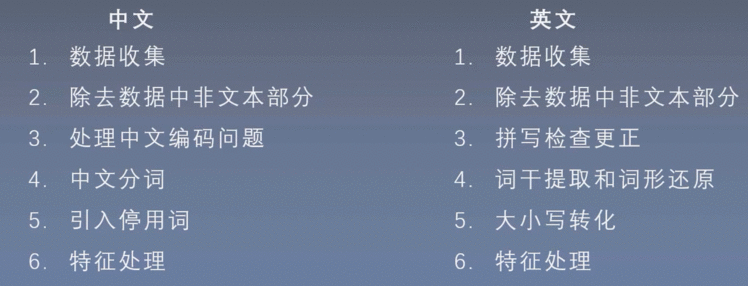
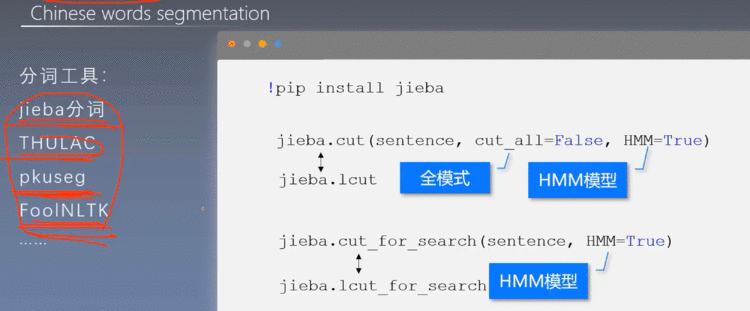
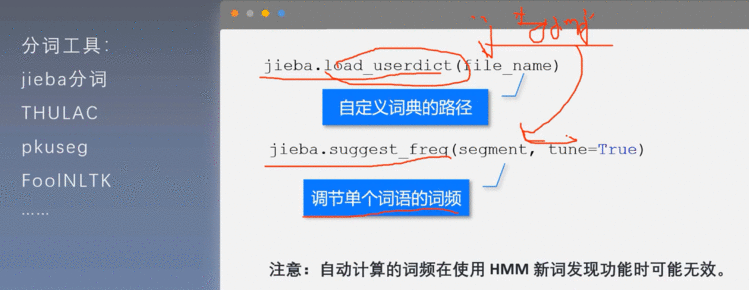
1、中文分词工具
2、引入停用词:是否需要去掉停用词需要根据模型进行考虑

数据分析
1、文本长度统计

2、词频统计
有很多仅出现一次

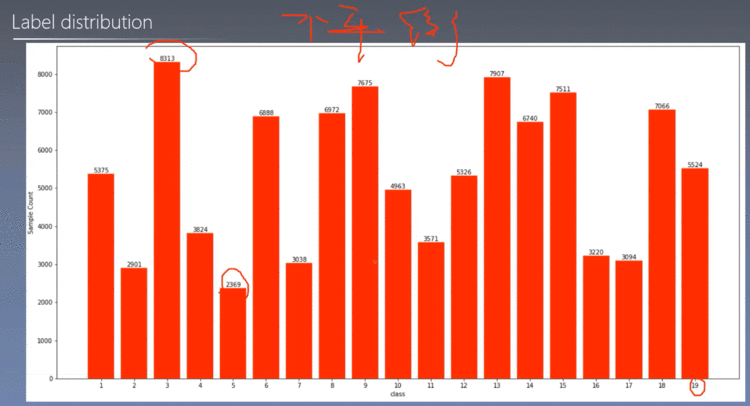
3、标签情况
标签分布不均匀
实践开始——传统机器学习
1、导入数据
装载到谷歌云盘(使用colab)

2、文本预处理
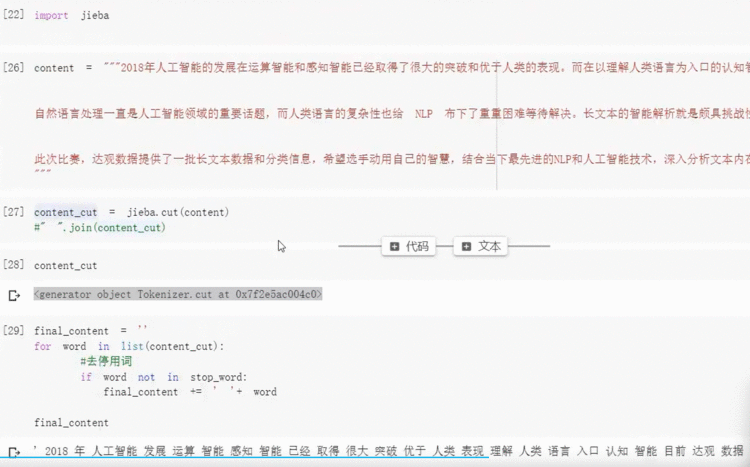
2.1 语料清洗
使用正则表达式去除空格和符号

2.2 分词:使用jieba


如果分词错误,我们可以选择自己调整词典
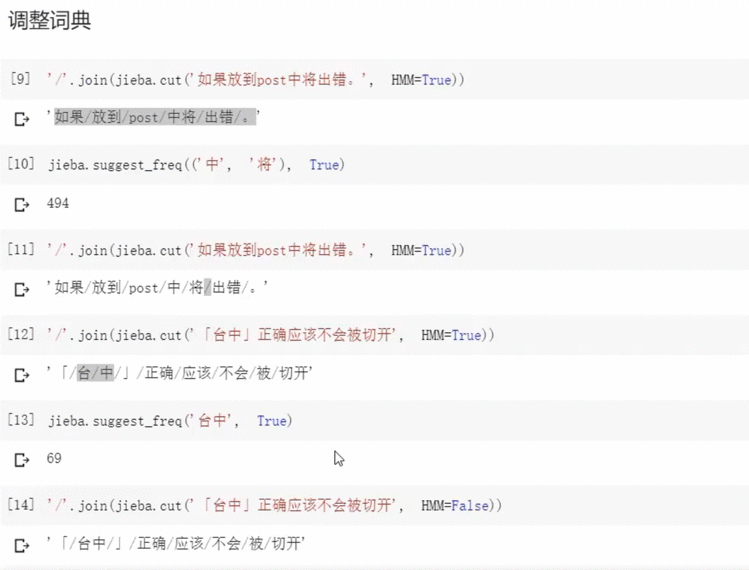
2.3 分词:使用pkuseg

2.4 去停用词
下载

加载

使用停用词
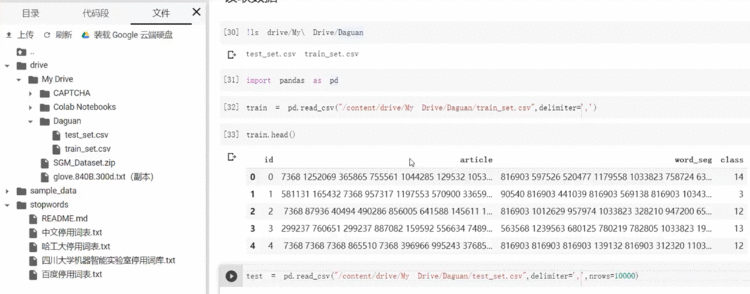
3、数据分析
3.1 读取数据
3.2 字和词的区别

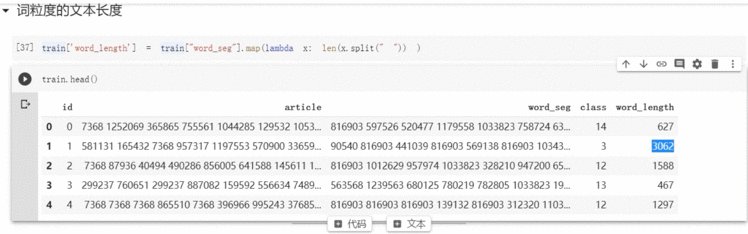
3.3 训练集文本长度
(1)词粒度
进行可视化的代码

基本信息分析

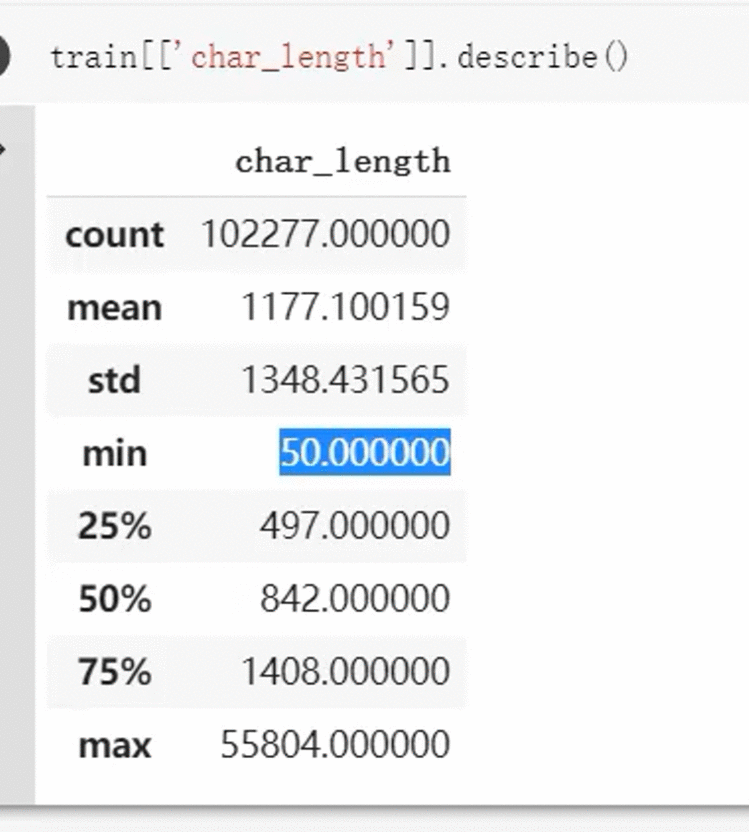
(2)字粒度

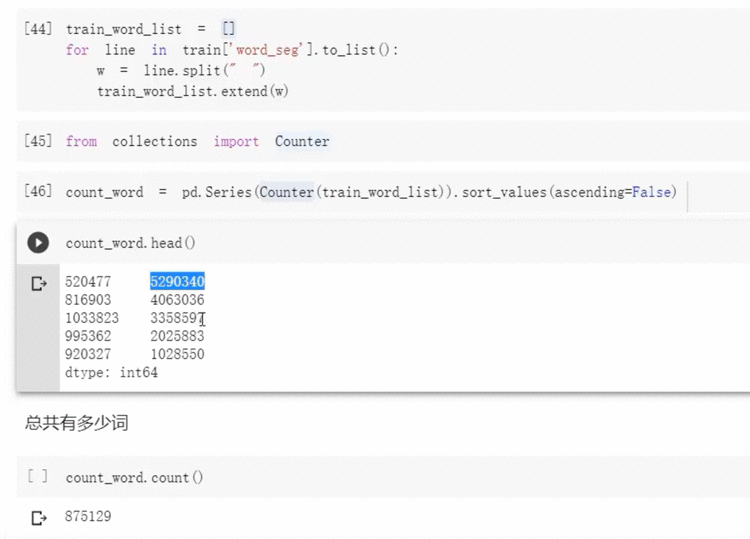
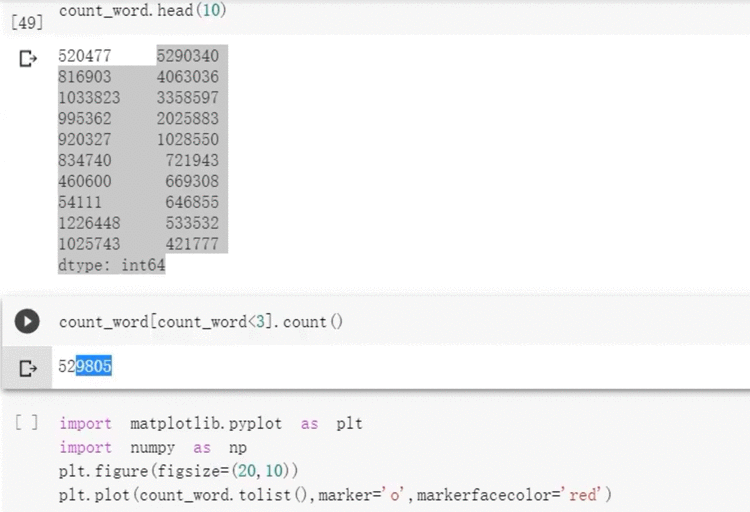
3.4 统计训练集中词的数量并进行可视化

3.5 统计训练集中字的数量并进行可视化


3.6 标签分布并可视化


4、阶段总结、
该问题是:
5、Baseline构建的基础知识
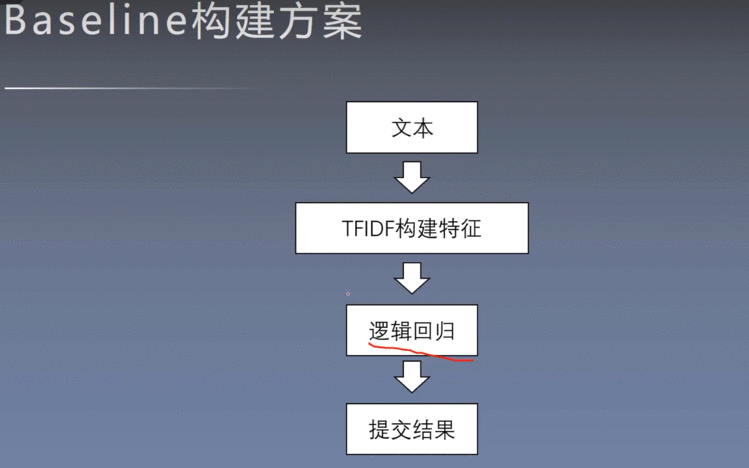
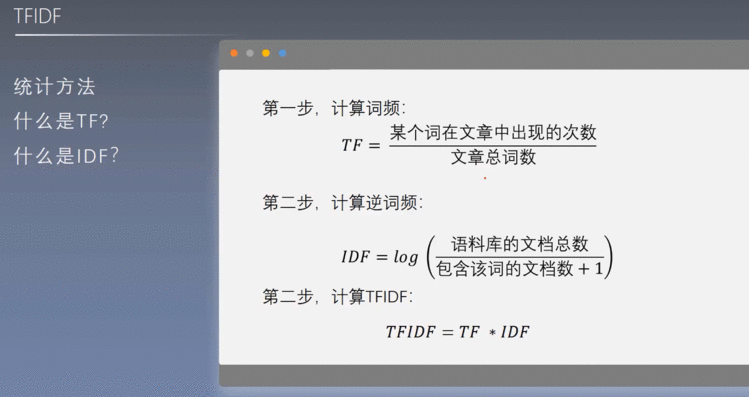
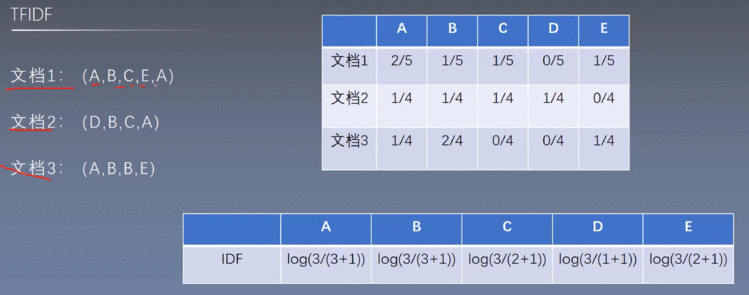
5.1 TFIDF
5.2 Ngram

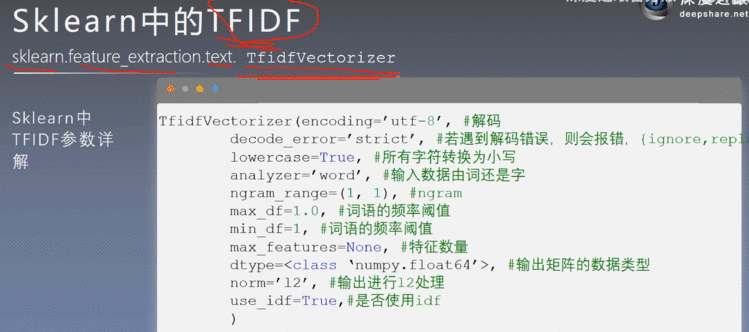
5.3 Sklearn中的TFIDF
5.4 逻辑回归
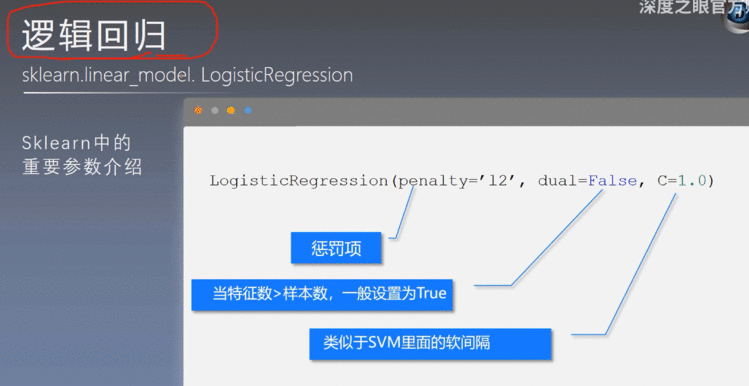
6、实际构建Baseline
6.1 读取数据集
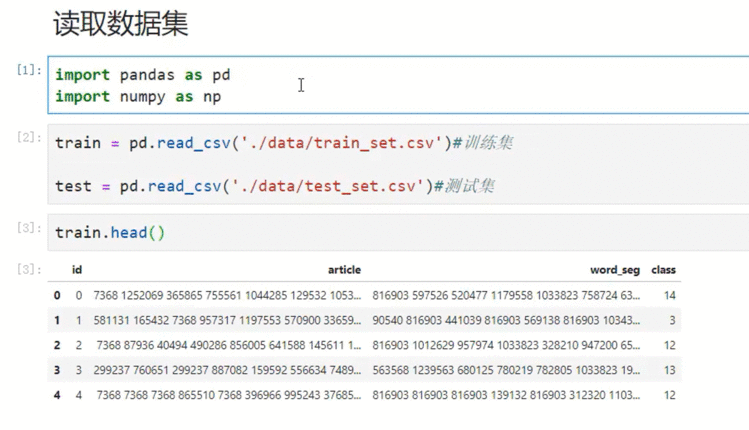
6.2 TFIDF构建文本特征
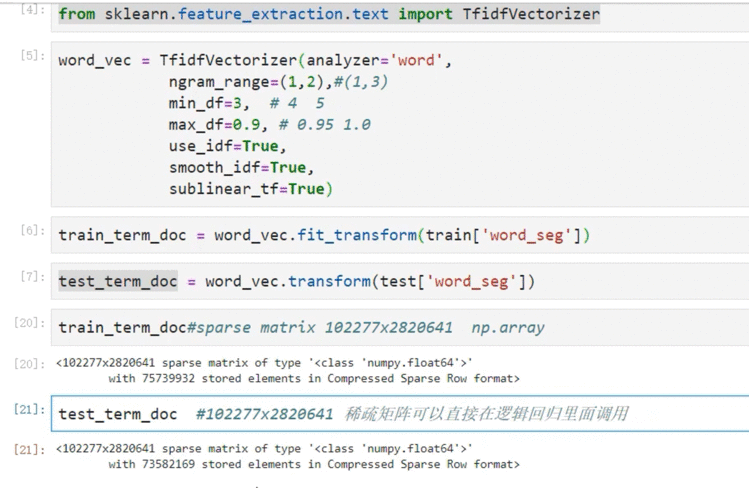
6.3 逻辑回归构建模型
针对标签进行转换,这里是从1-19➡0-18。其实如果是字母也可以转化
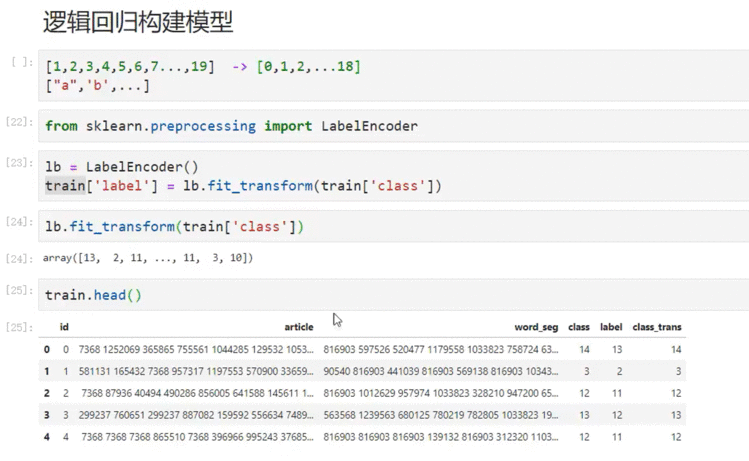
同样的我们也可以针对分类转化为标签
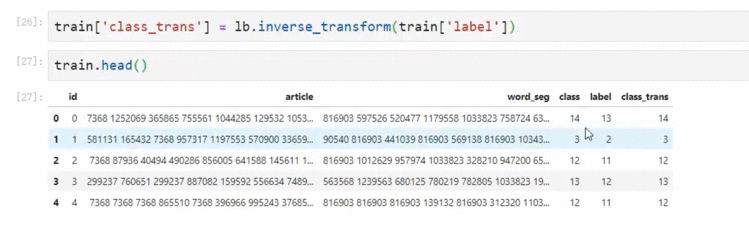
测试一下转化的是否正确

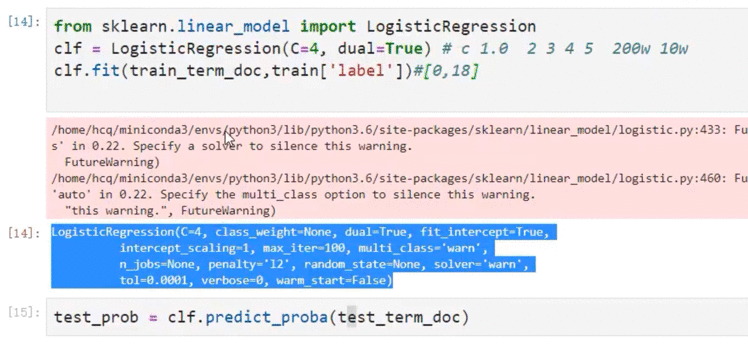
逻辑回归转化
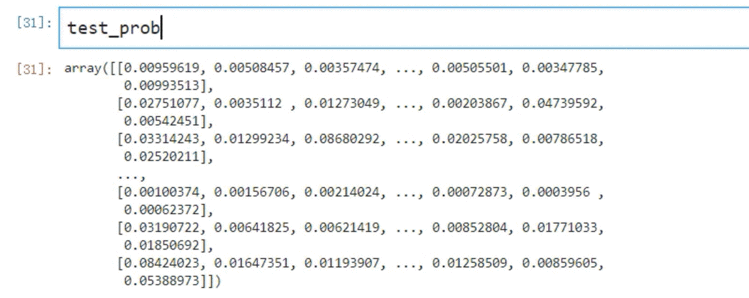
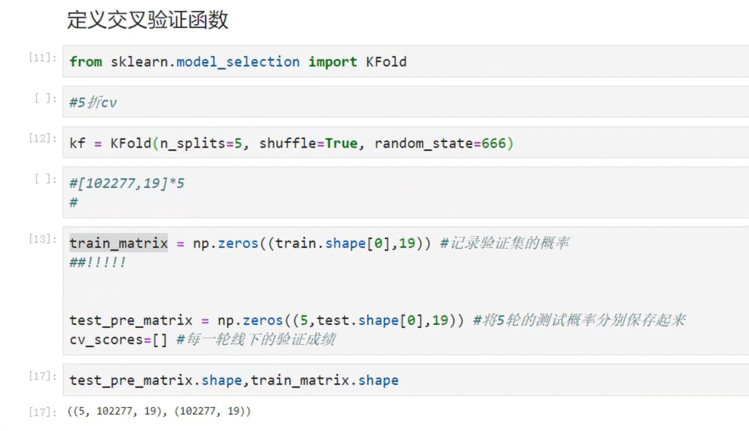
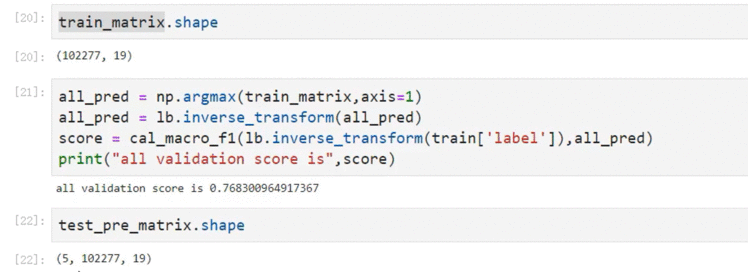
最终得到一个矩阵,shape=(102277,19)
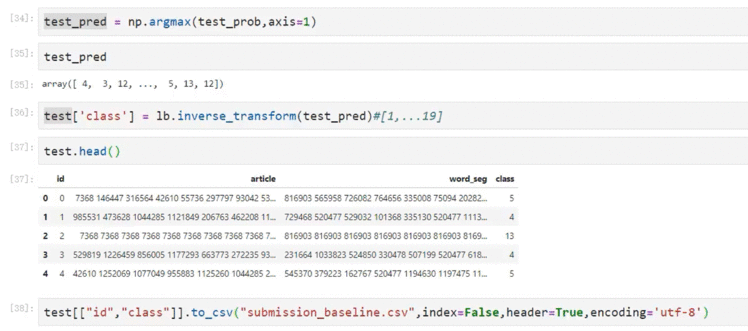
6.4 结果保存
7、如何提升成绩
- TFIDF只使用了词的特征,没有使用字的
- 逻辑回归 LightGBM Xgboost SVM
8、构建验证集
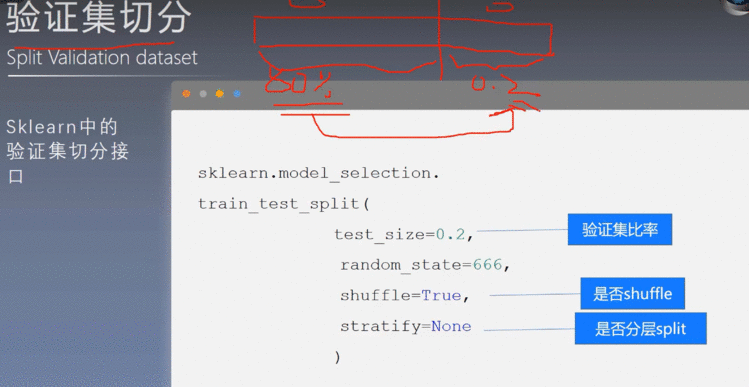
8.1 实操
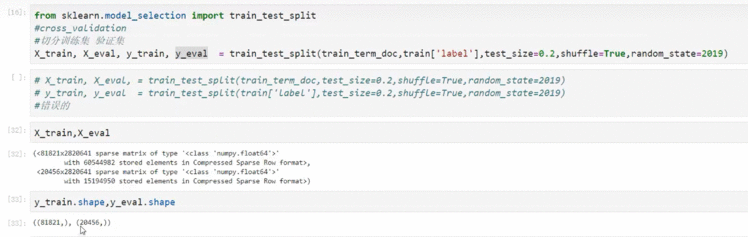
8.2 用于训练
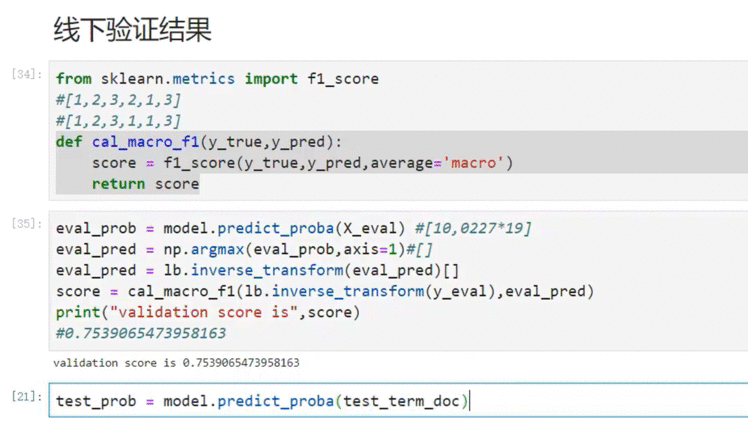
8.3 验证结果
使用f1作为预测结果的效果
8.4 结果保存并提交
效果很稳定,但是准确率依然不足
9、交叉验证
9.1 K折交叉验证
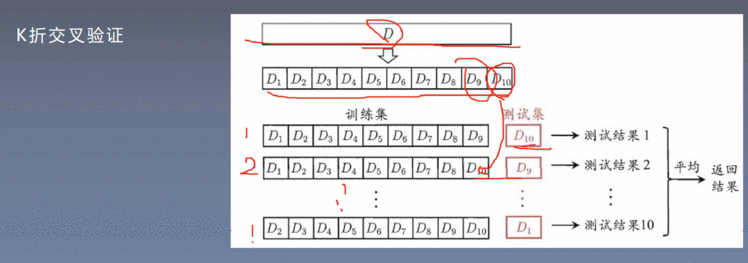
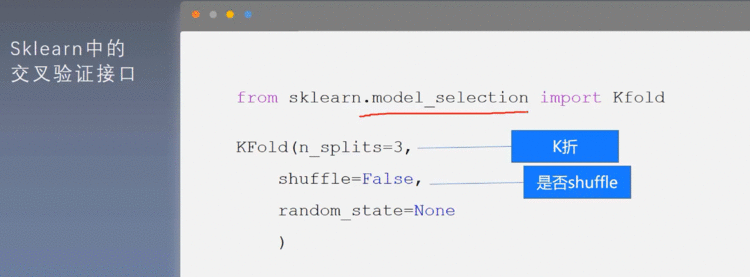
9.2 接口
9.3 使用逻辑回归应用K折交叉验证
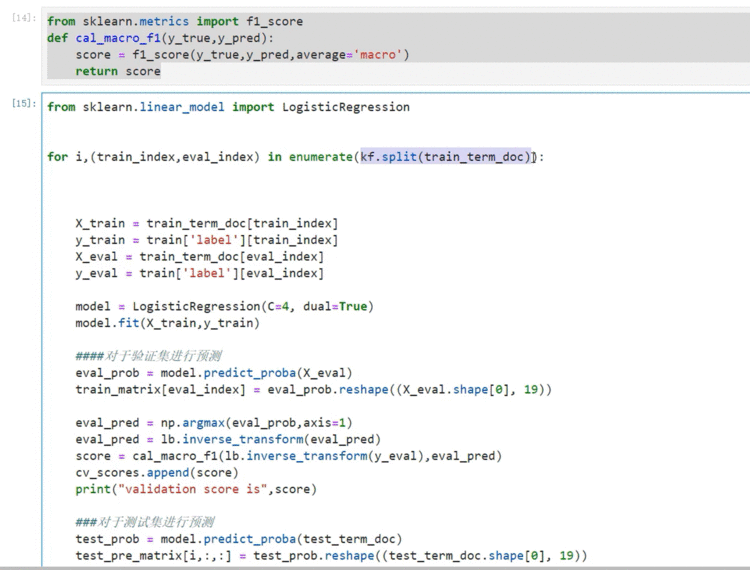
实践开始——深度学习
1、词向量
想让计算机理解一个词的意思和词之间的相似性,必须使用词向量

1.1 one-hot词向量

语义的鸿沟,这种表示方法男人和女人与小狗之间没有任何的相似性
1.2 SVD词向量
为了解决这种矛盾,我们可以采取降维的方式、
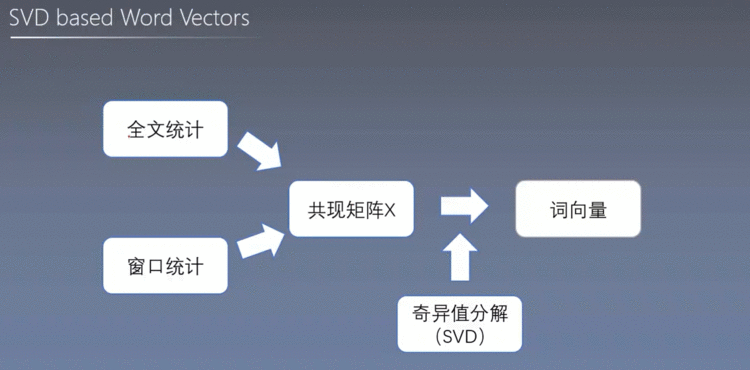
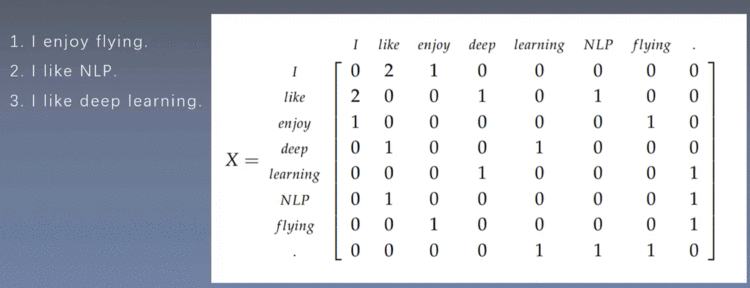
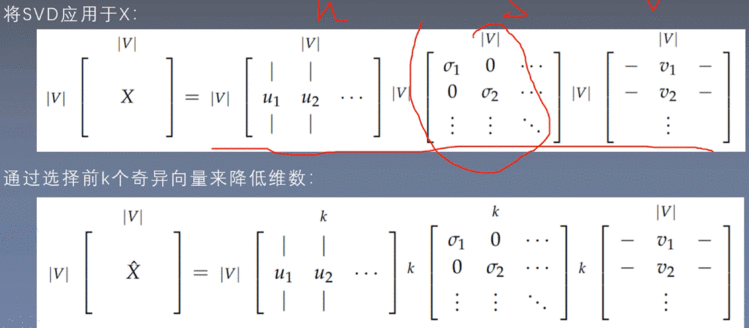
但是SVD方法仍然存在缺陷:

1.3 Word2vec词向量

两个算法
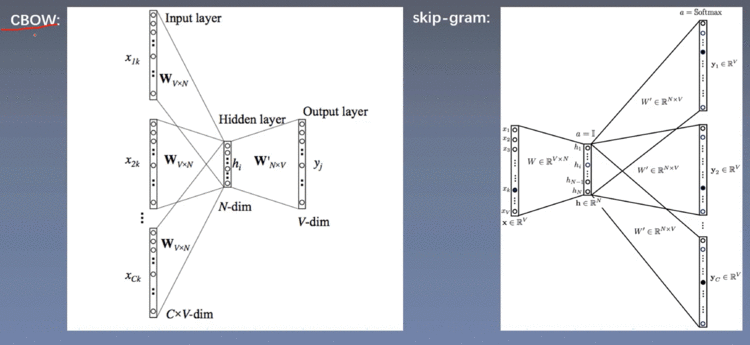
CBOW和skip-gram仍然需要后续的学习理解
两种训练方法

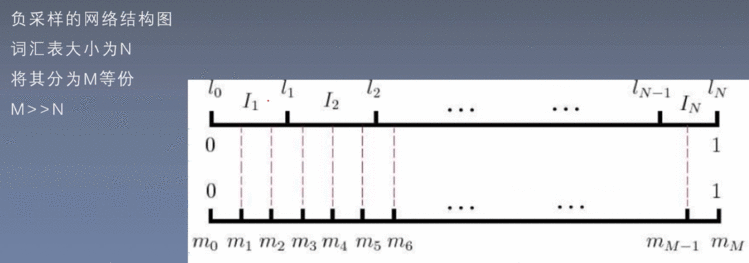
总结:

1.4 word2vec参数详解
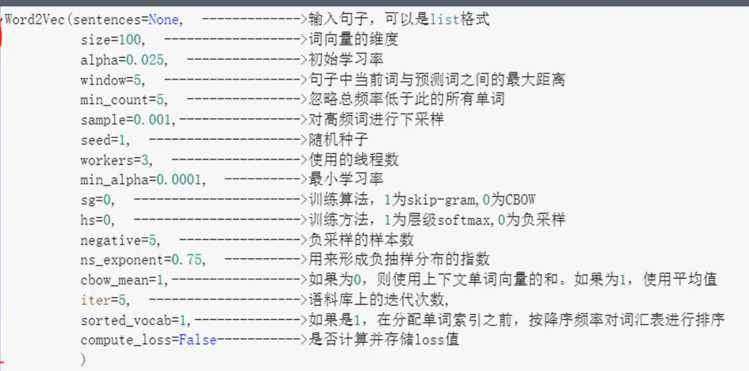
2、gensim实操
2.1 安装
2.2 gensim操作示例:100维的向量并表示词的含义


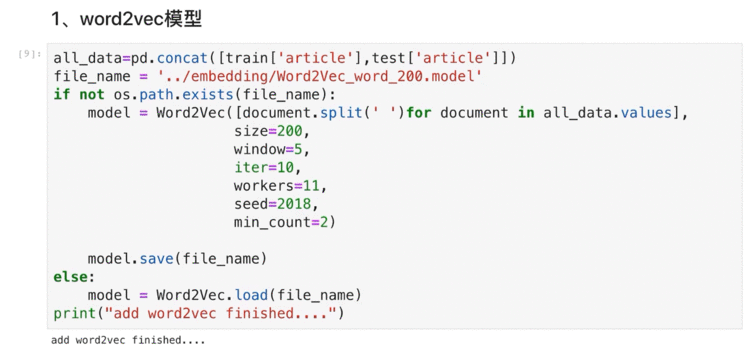
3、对达观杯数据进行词向量表示
3.1 导入包并读取数据集

将测试集和数据集的数据合并到一起:word2vec的效果会更好

3.2 训练word2vec
先将句子进行转换
进行训练

保存word2vec

下次直接加载已经训练好的word2vec

查看一个词向量及其相似关系
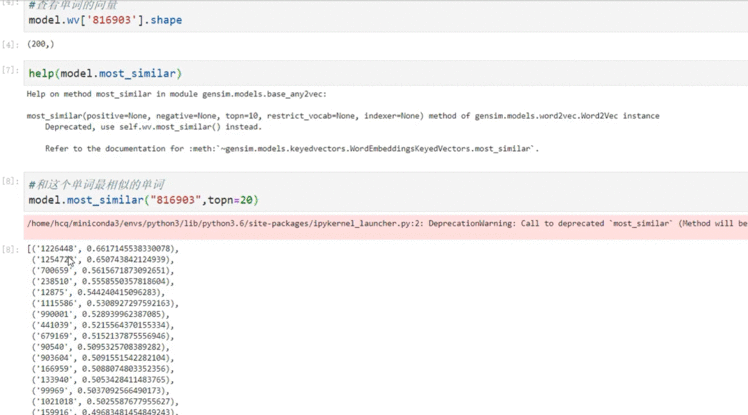

查看词表

3.3 迭代模型

4、数据处理部分
4.1 从文本到序列

4.2 文本的截断和补全:
不同的文本长度不同,我们要进行均一化
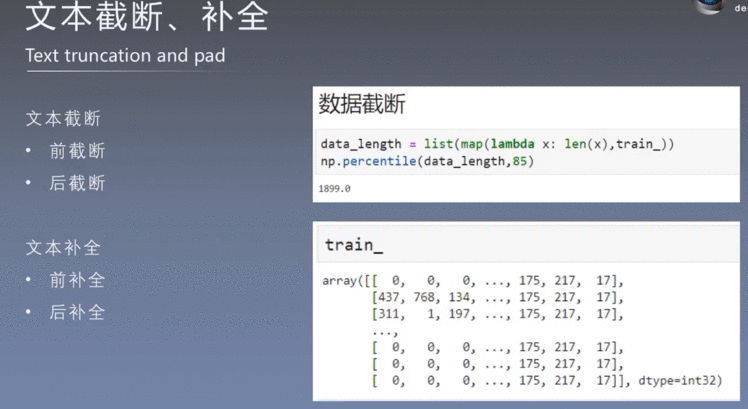
对于全部的文本进行统计,看看多长的文本可以覆盖到全部文本的80%、90%
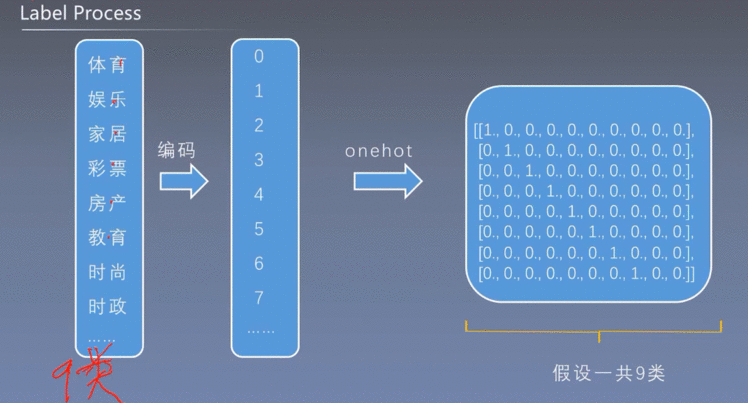
4.3 Label处理
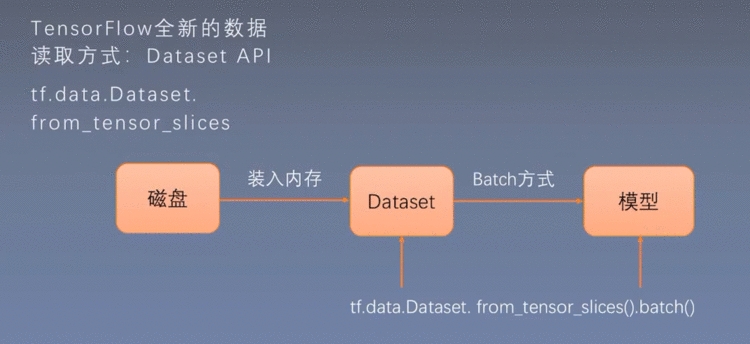
4.4 Dataset数据读取
5、数据处理实操
5.1 导入包

5.2 读取数据集

5.3 数据准备
查看了一下95%的样本可以使用1822进行表示
数据截断与补全

词表

Label处理

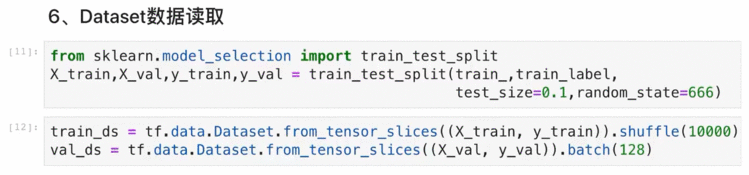
Dataset数据读取
6、Word Embedding构建
6.1 构建流程

将词向量映射成Word Embedding,可以节约大量的内存

6.2 构建
首先获取word2vec模型
word embedding构建

7、深度学习baseline
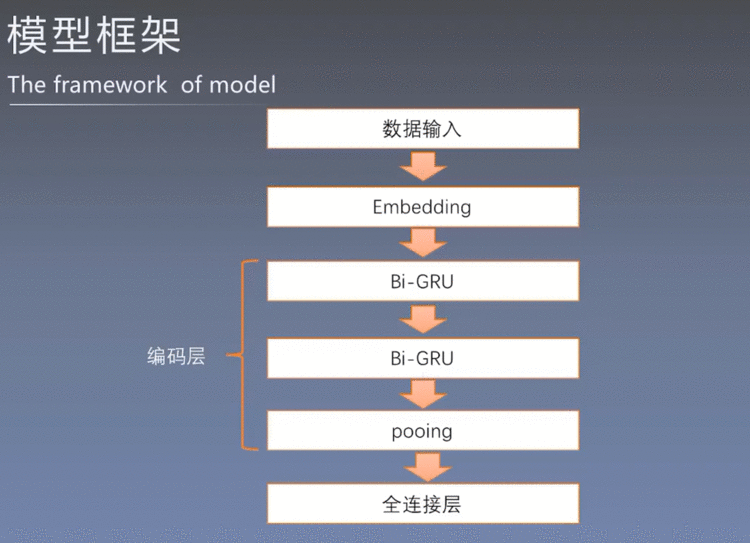
7.1 模型构建


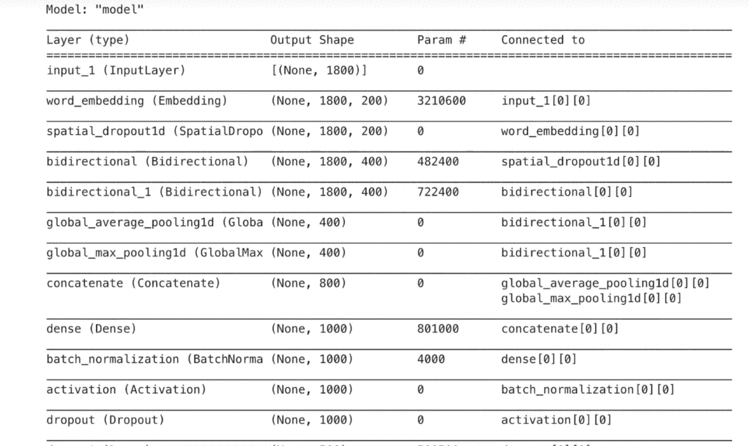
7.2 模型一览

7.3 模型的训练与预测



7.4 加载模型

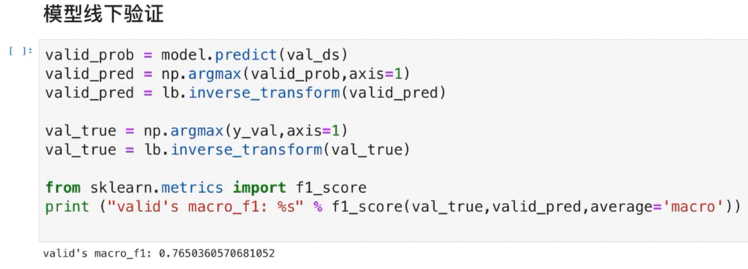
7.5 模型的验证
7.6 结果提交










 京公网安备 11010802041100号
京公网安备 11010802041100号