“从MySQL的物理结构和内存结构开始了解MySQL的运行机制”
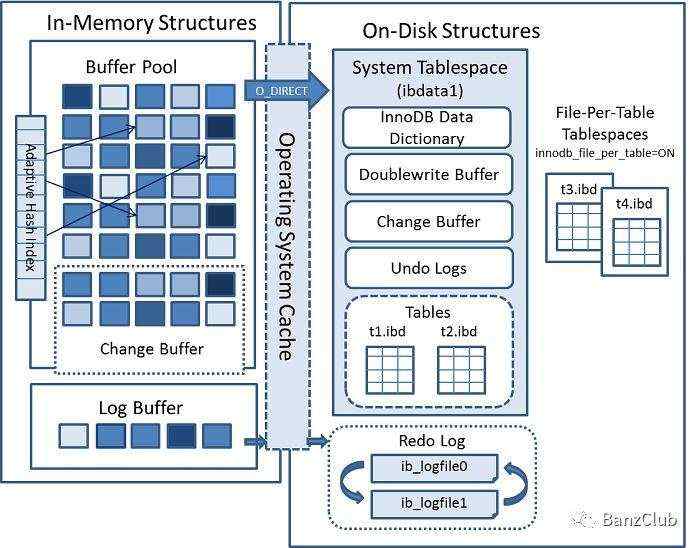
MySQL的数据存储结构主要分两个方面:物理存储结构与内存存储结构,作为数据库,所有的数据最后一定要落到磁盘上,才能完成持久化的存储。内存结构为了实现提升数据库整体性能,主要用于存储临时数据和日志的缓冲。本文主要讲MySQL的物理结构,以及MySQL的内存结构,对于存储引擎也主要以InnoDB为主。
01
—
MySQL的物理结构
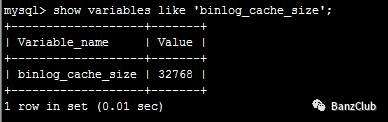
show variables like 'binlog_cache_size';
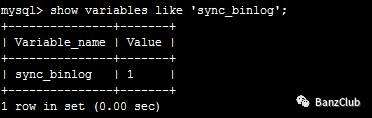
show variables like 'sync_binlog';
如果设置为0,表示MySQL不控制binlog的刷盘,由操作系统的文件系统来控制它的属性;
如果设置不为0的值,表示每【设置值】次事务,刷新binlog缓冲池到磁盘;
STATEMENT:基于SQL语句的复制(statement-based replication, SBR)
ROW:基于行的复制(row-based replication, RBR)
MIXED:混合模式复制(mixed-based replication, MBR)
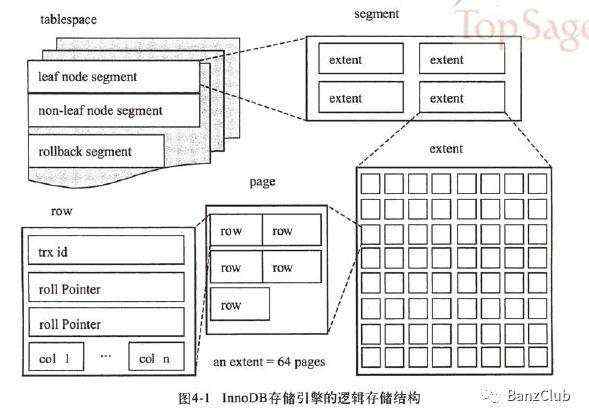
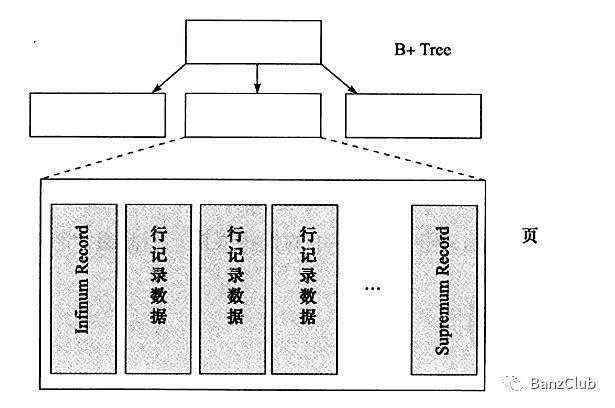
InnoDB存储引擎将所有数据逻辑地存放在一个空间,我们称之为表空间(tablespace)。表空间由段(segment)、区(extent)、页(page)组成,大致存储结构如下图所示:
段:常见的段有数据段(B+树页节点)、索引段(B+树非页节点,索引节点)、回滚段等。
区:区是由64个连续的页组成的,每个页大小为16KB,即每个区大约为1MB。
页:页是innodb磁盘管理最小的单位,innodb每个页的大小是16K,且不可更改。常见的页有数据页、Undo页、事务数据页、系统页等
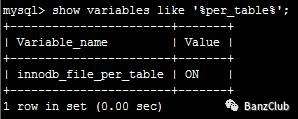
show variables like '%per_table%';
show variables like 'innodb_data%'
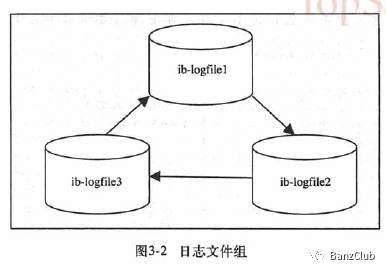
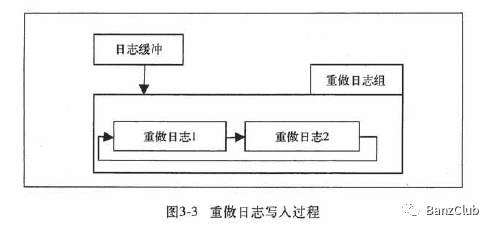
设置为0时,每次事务提交都把redo log留在redo log buffer中,等待master thread每秒定时刷到redo log中;
设置为1时,每次事务提交都将redo log持久化到磁盘;
设置为2时,每次事务提交只是把redo log写到磁盘的page上,等待数据刷盘;
02
MySQL的内存结构
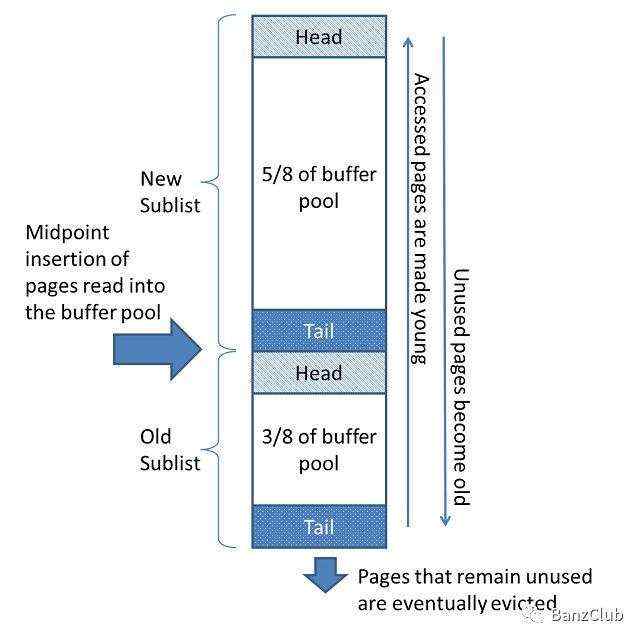
InnoDB存储引擎使用Buffer Pool在内存中缓存表数据和索引,处理数据时可以直接操作缓冲池的数据,提升InnoDB的处理速度。缓冲池的数据一般按照页格式,每个页包含多行数据,缓冲池可以看成是页面链表,并且使用LRU(last recent used)算法,来管理缓冲池的数据列表。当需要新空间将新页面加到缓冲池时,将会淘汰最近最少使用的数据。
innodb_buffer_pool_instances 与 innodb_buffer_pool_size 配置缓冲池的实例和缓冲池大小:通过配置多个缓冲池可以减少不同线程的竞争,提升并发度。通常在专用服务器上,80%的物理内存会分配给Buffer Pool。
innodb_buffer_pool_chunk_size 配置缓冲池的块大小:当增加或减少innodb_buffer_pool_size时,操作以块形式执行,块大小由此参数决定,默认为128M。
innodb_max_dirty_pages_pct 配置脏页比例:根据设置的缓冲池中脏页比例,来触发将脏页刷盘的时机。另外,InnoDB也根据redo log的生成速度和刷新频率,来触发刷盘时机。
innodb_read_ahead_threshold 与 innodb_random_read_ahead 预读参数配置:预读是指一次I/O请求磁盘中某页中的数据时,会同时同步取出相邻页面的数据,缓存到缓冲池。因为,InnoDB认为这些页面的数据大概率也将会被读取,从而来提升I/O性能。包括线性预读和随机预读。
https://dev.mysql.com/doc/refman/5.5/en/innodb-on-disk-structures.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-in-memory-structures.html
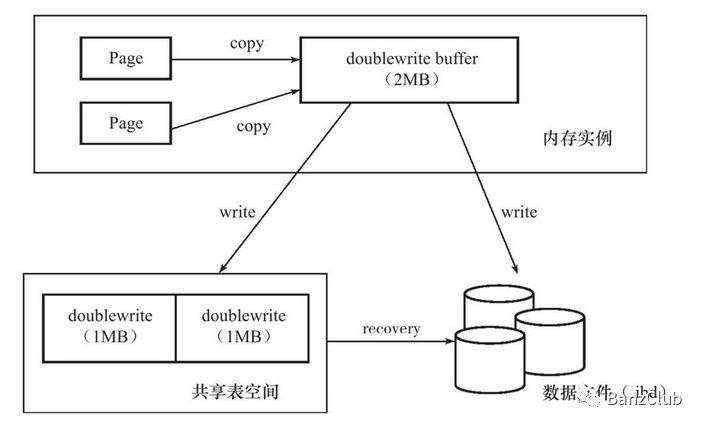
https://dev.mysql.com/doc/refman/5.7/en/innodb-doublewrite-buffer.html
《MySQL技术内幕:InnoDB存储引擎》
https://www.cnblogs.com/liuhao/p/3714012.html
https://my.oschina.net/u/553773/blog/792144
https://github.com/mysql/mysql-server/tree/5.7







 京公网安备 11010802041100号
京公网安备 11010802041100号