作者:冬日暖光816 | 来源:互联网 | 2023-07-18 06:57
Innodb内存结构Innodb的内存结构主要分为3个部分:BufferPool、ChangeBuffer、AdaptiveHashIndex,另外还有一个(redo)logbuf
Innodb 内存结构
Innodb的内存结构主要分为 3 个部分: Buffer Pool、Change Buffer、Adaptive HashIndex,另外还有一个(redo)log buffer。
缓冲池 Buffer Pool
首先,InnnoDB的数据都是放在磁盘上的,InnoDB操作数据有一个最小的逻辑单位,叫做页(索引页和数据页)。我们对于数据的操作,不是每次都直接操作磁盘,因为磁盘的速度太慢了。 InnoDB使用了一种缓冲池的技术,也就是把磁盘读到的页放到一块内存区域里面。这个内存区域就叫Buffer Pool。
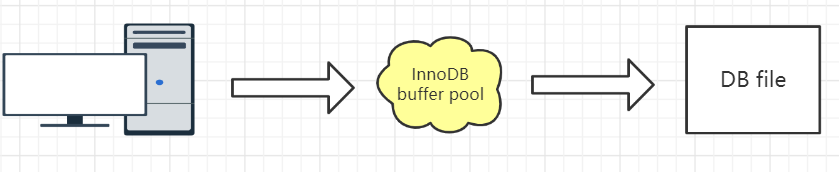
下一次读取相同的页,先判断是不是在缓冲池里面,如果是,就直接读取,不用再次访问磁盘。
修改数据的时候,先修改缓冲池里面的页。内存的数据页和磁盘数据不一致的时候,我们把它叫做脏页。InnoDB里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
Buffer Pool缓存的是页面信息,包括数据页、索引页。查看服务器状态,里面有很多跟Buffer Pool相关的信息:
SHOW STATUS LIKE '%innodb_buffer_pool%';
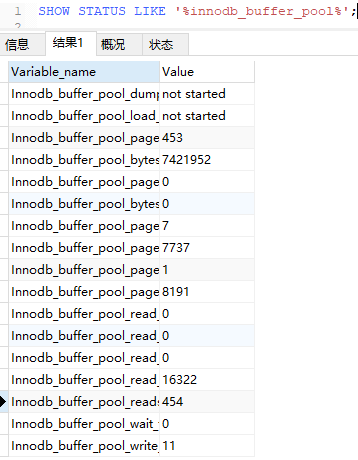
这些状态都可以在官网查到详细的含义,用搜索功能。 Buffer Pool默认大小是128M(134217728字节),可以调整。另外,查看参数(系统变量)的命令是:
SHOW VARIABLES like '%innodb_buffer_pool%';
内存缓冲区对于提升读写性能有很大的作用。思考一个问题:当需要更新一个数据页时,如果数据页在BufferPool中存在,那么就直接更新好了。否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。也就是说,如果没有命中缓冲池,至少要产生一次磁盘IO,有没有优化的方式呢?
Change Buffer(写缓冲)
如果这个数据页不是唯一索引(注:唯一索引就是在同一字段下不能有相同值),也就不需要从磁盘加载索引页判断数据是不是重复(唯一性检查)。这种情况下可以先把修改记录在内存的缓冲池中,从而提升更新语句(Insert、Delete、Update)的执行速度。这一块区域就是 Change Buffer。5.5 之前叫Insert Buffer 插入缓冲,现在也能支持delete和update。最后把 Change Buffer 记录到数据页的操作叫做 merge。
什么时候发生 merge?有几种情况:在访问这个数据页的时候,或者通过后台线程、或者数据库shut down、redo log写满时触发。
(redo) Log Buffer
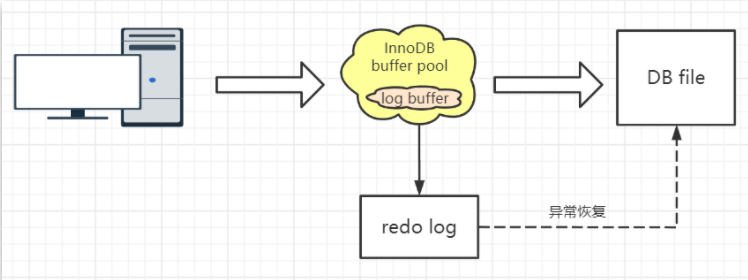
思考一个问题:如果BufferPool里面的脏页还没有刷入磁盘时,数据库宕机或者重启,这些数据丢失。如果写操作写到一半,甚至可能会破坏数据文件导致数据库不可用。为了避免这个问题, InnoDB把所有对页面的修改操作专门写入一个日志文件,并且在数据库启动时从这个文件进行恢复操作(实现crash-safe)——用它来实现事务的持久性。
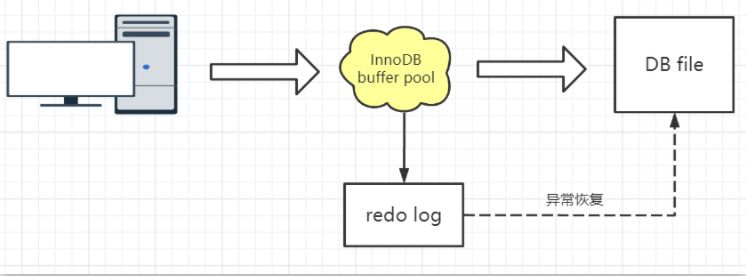
这个文件就是磁盘的redo log(叫做重做日志),对应于/var/lib/mysql/目录下的ib_logfile0和ib_logfile1,每个48M。
这种日志和磁盘配合的整个过程,其实就是 MySQL 里的 WAL 技术(Write-Ahead Logging),它的关键点就是先写日志,再写磁盘。
show variables like 'innodb_log%';
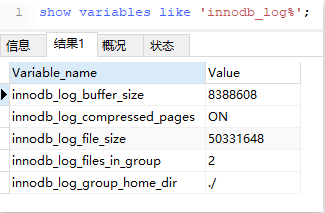
- innodb_log_file_size:指定每个文件的大小,默认 48M
- innodb_log_files_in_group:指定文件的数量,默认为 2
- innodb_log_group_home_dir:指定文件所在路径,相对或绝对。如果不指定,则为 datadir 路径。
刷盘是随机I/O,而记录日志是顺序I/O,顺序I/O效率更高。因此先把修改写入日志,可以延迟刷盘时机,进而提升系统吞吐。
redo log,它又分成内存和磁盘两部分。redo log有什么特点?
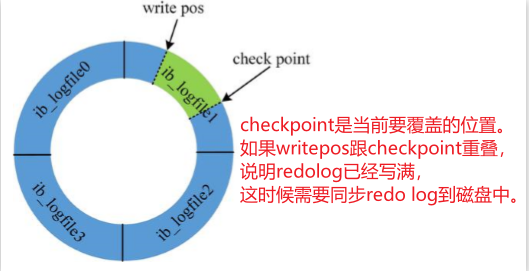
- redo log是InnoDB存储引擎实现的,并不是所有存储引擎都有。
- 不是记录数据页更新之后的状态,而是记录这个页做了什么改动,属于物理日志。
- redo log的大小是固定的,前面的内容会被覆盖
这里再强调一次,redolog的内容主要是用于崩溃恢复。磁盘的数据文件,数据来自bufferpool。redo log 写入磁盘,不是写入数据文件。
当然redo log也不是每一次都直接写入磁盘,在Buffer Pool里面有一块内存区域(Log Buffer)专门用来保存即将要写入日志文件的数据,默认16M,它一样可以节省磁盘IO。
update过程
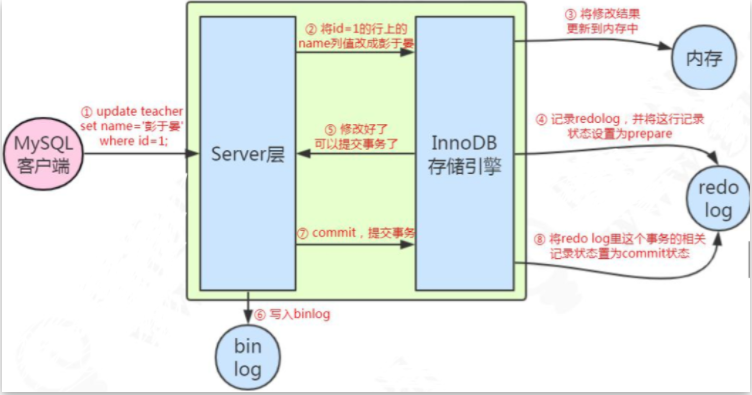
有了这些日志之后,我们来总结一下一个更新操作的流程,这是一个简化的过程(name原值是zhangsan)。
update user set name='penyuyan' where id=1;
- 事务开始,从内存或磁盘取到这条数据,返回给Server 的执行器;
- 执行器修改这一行数据的值为penyuyan;
- 记录 name=zhangsan 到 undo log;
- 记录 name=zhangsan 到redo log;
- 调用存储引擎接口,在内存(Buffer Pool)中修改 name=zhangsan;
- 事务提交
另外,内存和磁盘之间,工作着很多后台线程。后台线程的主要作用是负责刷新内存池中的数据和把修改的数据页刷新到磁盘。后台线程分为:master thread,IO thread,purge thread,page cleaner thread。
- master thread:负责刷新缓存数据到磁盘并协调调度其它后台进程
- IO thread:分为 insert buffer、 log、 read、 write进程。分别用来处理 insert buffer、重做日志、读写请求的IO回调
- purge thread:用来回收undo 页
- page cleaner thread:用来刷新脏页
除了 InnoDB 架构中的日志文件,MySQL 的 Server 层也有一个日志文件,叫做binlog,它可以被所有的存储引擎使用。
binlog 以事件的形式记录了所有的DDL和DML语句(因为它记录的是操作而不是数据值,属于逻辑日志),可以用来做主从复制和数据恢复。跟redo log不一样,它的文件内容是可以追加的,没有固定大小限制。
在开启了binlog功能的情况下,我们可以把binlog导出成SQL语句,把所有的操作重放一遍,来实现数据的恢复。binlog的另一个功能就是用来实现主从复制,它的原理就是从服务器读取主服务器的binlog,然后执行一遍。
有了这两个日志之后,我们来看一下一条更新语句是怎么执行的:






 京公网安备 11010802041100号
京公网安备 11010802041100号