前言 开门见山,面对这样一个问题,你将如何作答?
1千万,2千万,或者上亿条数据?具体的答案不重要,当然肯定也不会是一个固定的数目,今天我们就一起来探讨探讨这个问题。
InnoDB是一种兼顾了高可靠性和高性能的通用存储引擎,它拥有诸多功能和特性,体系结构和工作原理也比较复杂。真要讲明白说透彻,不是一两篇博文能够实现的,也不是今天的重点。
所以,本文不涉及太多的原理性知识,咱们就针对开头提出的问题,通过熟悉一些基本的概念和利用工具来验证,对这个问题做到心中有数。
文件结构 我们知道,InnoDB引擎是支持事务的,所以表里的数据肯定都是存储在磁盘上的。如果在test数据库下创建两个表:t1和t2,那么在相应的数据目录下就会发现两个文件。
[root@localhost test ]# ls test ]# pwd test
其中,frm文件是表结构信息,ibd文件是表中的数据。
表结构信息包含MySQL表的元数据(例如表定义)的文件,比如表名、表有多少列、列的数据类型啥的,不重要,我们先不管;
ibd文件存储的是表中的数据,比如数据行和索引。这个文件比较重要,它是今天我们的重点研究对象。
我们说,MySQL表里的数据都是存放在磁盘上的。那么在磁盘上,最小单元是扇区,每个扇区可以存放512个字节的数据;操作系统中最小单元是块(block),最小单位是4kb。
在Windows系统中,我们可以通过fsutil fsinfo ntfsinfo c:
C:\Windows\system32>fsutil fsinfo ntfsinfo c:
在Linux系统上,可以通过以下两个命令查看,这取决于文件系统的格式。
xfs_growfs /dev/mapper/centos-root | grep bsize
我们拉回来接着说MySQL,InnoDB存储引擎它也是有最小存储单位的,叫做页(Page),默认大小是16kb。
我们新创建一个表 t3,里面任何数据都没有,我们来看它的ibd文件。
[root@localhost test ]# ll
不仅是t3,我们看到,任何表的ibd文件大小,它永远是16k的整数倍。理解这个事非常重要,MySQL从磁盘加载数据是按照页来读取的,即便你查询一条数据,它也会读取一页16k的数据出来。
聚簇索引 数据库表中的数据都是存储在页里的,那么这一个页可以存放多少条记录呢?
这取决于一行记录的大小是多少,假如一行数据大小是1k,那么理论上一页就可以放16条数据。
当然,查询数据的时候,MySQL也不能把所有的页都遍历一遍,所以就有了索引,InnoDB存储引擎用B+树的方式来构建索引。
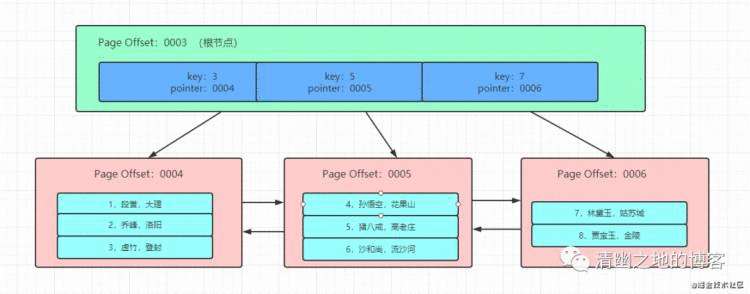
聚簇索引就是按照每张表的主键构造一颗B+树,叶子节点存放的是整行记录数据,在非叶子节点上存放的是键值以及指向数据页的指针,同时每个数据页之间都通过一个双向链表来进行链接。
如上图所示,就是一颗聚簇索引树的大致结构。它先将数据记录按照主键排序,放在不同的页中,下面一行是数据页。上面的非叶子节点,存放主键值和一个指向页的指针。
当我们通过主键来查询的时候,比如id=6id=6
在这里,我们需要理解两件事:
上图中B+树的根节点(page offset=3),是固定不会变化的。只要表创建了聚簇索引,它的根节点
现在我们知道了InnoDB存储引擎最小存储单元是页,在B+树索引结构里,页可以放一行一行的数据(叶子节点),也可以放主键+指针(非叶子节点)。
上面已经说过,假如一行数据大小是1k,那么理论上一页就可以放16条数据。那一页可以放多少主键+指针呢?
假如我们的主键id为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节。这样算下来就是 16384 14 = 1170,就是说一个页上可以存放1170个指针。
一个指针指向一个存放记录的页,一个页里可以放16条数据,那么一颗高度为2的B+树就可以存放 1170 * 16=18720 条数据。同理,高度为3的B+树,就可以存放 1170 * 1170 * 16 = 21902400 条记录。
理论上就是这样,在InnoDB存储引擎中,B+树的高度一般为2-4层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次IO,那我们通过主键索引查询的时候,其实最多只需要2-4次IO就可以了。
那么,实际上到底是不是这样呢?我们接着往下看。
页的类型 在开始验证之前,我们不仅需要了解页,还需要知道,在InnoDB引擎中,页并不是只有一种。常见的页类型有:
事务数据页,Transaction system Page; 插入缓冲位图页,Insert Buffer Bitmap; 插入缓冲空闲列表页,Insert Buffer Free List; 未压缩的二进制大对象页,Uncompressed BLOB Page; 在这里我们重点来看 B-tree Node,我们的索引和数据就放在这种页上。既然有不同的页类型,我们怎么知道当前的页属于什么页呢?
那么我们就需要大概了解下数据页的结构,数据页由七个部分组成,每个部分都有不同的含义。
Infimum + supremum,固定26字节; User Records,用户记录,即行记录,大小不固定; Page Directort,页目录,大小不固定; File Trailer,文件结尾信息,固定8字节。 其中,File Header用来记录页的一些头信息,共占用38个字节。在这个头信息里,我们可以获取到该页在表空间里的偏移值和这个数据页的类型。
接下来是Page Header,它记录的是数据页的状态信息,共占用56个字节。在这一部分,我们可以获取到两个重要的信息:该页中记录的数量和当前页在索引树的层级,其中0x00代表叶子节点,比如聚簇索引中的叶子节点放的就是整行数据,它总是在第0层。
验证 前面我们已经说过,ibd文件就是表数据文件。这个文件会随着数据库表里数据的增长而增长,不过它始终会是16k的整数倍。里面就是一个个的页,那我们就可以一个一个页的来解析,通过文件头可以判断它是什么页,找到 B-tree Node,就可以看到里面的 Page Level,它的值+1,就代表了当前B+树的高度。
我们现在就来重新创建一个表,为了使这个表中的数据一行大小为1k,我们设置几个char(255)的字段即可。
CREATE TABLE `t5` ('1' ,'1' ,'1' ,'1' ,
然后笔者写了一个存储过程,用来批量插入数据用的,为了加快批量插入的速度,笔者还修改了innodb_flush_log_at_trx_commit=0
BEGINset i = i+1;set i = i+1;
innodbPageInfo.jar
-path 后面是文件的路径,-v 是否显示页的详情信息,0是 1否。
上面我们创建了t5这张表,一条数据还没有的情况下,我们看一下这个ibd文件的信息。
[root@localhost innodbInfo]# java -jar innodbPageInfo.jar -path /var/lib/mysql/test/t5.ibd -v 0 type type type type ,page level <0000>type type #
t5表现在没有任何数据,它的ibd文件大小是98304,也就是说一共有6个页。其中第四个页(page offset 3)是数据页,page level等于0,代表该页为叶子节点。因为目前还没有数据,可以认为B+树的索引只有1层。
我们接着插入10条数据,这个page level还是为0,B+树的高度还是1,这是因为一个页大约能存放16条大小为1k的数据。
page offset 00000003,page type ,page level <0000>
当我们插入15条数据的时候,一个页就放不下了,原本为新分配的页(Freshly Allocated Page)就会变成数据页,原来的根页面(page offset=3)就会升级成存储目录项的页。offset 04 和 05就变成了叶子节点的数据页,所以现在整个B+树的高度为2。
page offset 00000003,page type ,page level <0001>type ,page level <0000>type ,page level <0000>
继续插入10000条数据,我们再来看一下B+树高的情况。当然现在信息比较多了,我们把输出结果写到文件里。
java -jar innodbPageInfo.jar -path var/lib/mysql/test/t5.ibd -v 0 > t5.txt
截取部分结果如下:
[root@localhost innodbInfo]# vim t5.txt type ,page level <0001>type ,page level <0000>type ,page level <0000>type
可以看到,1万条1k大小的记录,一共用了716个数据页,根页面显示的树高还是2层。
前面我们计算过,2层的B+树理论上可以存放18000条左右,笔者测试大约13000条数据左右,B+树就会成为3层了。
page offset 00000003,page type ,page level <0002>
原因也不难理解,因为每个页不可能只放数据本身。
首先每个页都有一些固定的格式,比如文件头部、页面头部、文件尾部这些,我们的数据放在用户记录
其次,用户记录也不只放数据行,每个数据行还有一些其他标记,比如是否删除、最小记录、记录数、在堆中的位置信息、记录的类型、下一条记录的相对位置等等;
另外,MySQL参考手册中也有说到,InnoDB会保留页的1/16空闲,以便将来插入或者更新索引使用,如果主键id不是顺序插入的,那可能还不是1/16,会占用更多的空闲空间。
总之,我们理解一个页不会全放数据就行了。所以,实测跟理论上不一致也是完全正常的,因为上面的理论没有排除这些项。
接着来,我们再插入1000万条数据,现在ibd文件已经达到11GB。
page offset 00000003,page type ,page level <0002>
我们看到,1千万条数据,数据页已经有71万个,B+树的高度还是3层,这也就是说几万条数据和一千万条数据的查询效率基本上是一样的。比如我们现在根据主键ID查询一条数据,select * from t5 where id = 6548215;
什么时候会到4层呢?大概在1300万左右,B+树就会增加树高到4层。
什么时候会到5层呢?笔者没测试出来,因为插入到5000万条数据的时候,ibd数据文件大小已经55G了,虚拟机已经空间不足了。。
page offset 00000003,page type ,page level <0003>
即便是5000万条数据,我们通过主键ID查询,查询时间也是毫秒级的。
理论上要达到十亿 - 百亿行数据,树高才能到5层。如果有小伙伴用这种方法,测试出来5层高的数据,欢迎在评论区留言,让我看看。
另外,朋友们有没有意识到一个问题?其实影响B+树树高的因素,不仅是数据行,还有主键ID的长度。我们上面的测试中,ID的类型是bigint(8),在其他字段长度均不变的情况下,我们把ID的类型改为int(4),相同的树高就会容纳更多的数据,因为它单个页能承载的指针数变多了。
CREATE TABLE `t6` ('1' ,'1' ,'1' ,'1' ,
针对t6这张表,我们插入16000条数据,然后输出一下页面信息。
page offset 00000003,page type ,page level <0001>
我们来看,如果按照主键ID类型bigint(8)来测试,13000条数据的时候,树高就已经是3了,现在改为int(4),16000条数据,树高依然还是2层。尽管数据页(B-tree Node)数量还是那么多,变化并不大,但是它不影响树高。
ok,看到这里,相信朋友们对开头提出的问题已经有自己的答案了,如果你也跟着试一遍,理解可能会更加深入。
看到这,还有道经典的面试题:为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
简单来说,其中有一个原因就是B+树的高度比较稳定,因为它的非叶子节点不会保存数据,只保存键值和指针的情况下,一个页能承载大量的数据。你想啊,B树它的非叶子节点也会保存数据的,同样的一行数据大小是1kb,那么它一页最多也只能保存16个指针,在大量数据的情况下,树高就会速度膨胀,导致IO次数就会很多,查询就会变得很慢。
源码地址 本文的innodbPageInfo.jarMySQL技术内幕(InnoDB存储引擎)
Java版本的源码我放在GitHub上了:https://github.com/taoxun/innodbPageInfo
已经打完包的Jar版本,也可以下载:https://pan.baidu.com/s/1IZVJRNUk_bPESp5zoQwOvA 提取码:5rnz。
朋友们可以拿这个工具看一看,自己认为较大的表,它的B+树索引到底有几层?
参考资料:
姜承尧:《MySQL技术内幕:InnoDB存储引擎》
天涯泪小武:https://tianyalei.blog.csdn.net/article/details/100015840
飘扬的红领巾:https://www.cnblogs.com/leefreeman/p/8315844.html
MySQL官方参考手册:https://dev.mysql.com/doc/refman/5.7/en/






 京公网安备 11010802041100号
京公网安备 11010802041100号