作者:松原电信曹玉威_203 | 来源:互联网 | 2023-09-17 21:15
目录
2021SC@SDUSC
Mixup方法
mixup原理
Mixup主要代码及分析
2021SC@SDUSC
Mixup方法
大型深度神经网络损耗巨大的内存,以及对对抗样本的敏感性一直不太理想。在VRM中,需要专业知识描述训练数据中每个样本的邻域,从而可以从训练样本邻域中提取附加的虚拟样本以扩充对训练分布的支持。数据增强可以提高泛化能力,但这一过程依赖于数据集。其次,数据增强假定领域内样本都是同一类,且没有对不同类不同样本之间领域关系进行建模。针对这些问题,一种简单且数据无关的数据增强方式被提出,即mixup方法,mixup方法构建了虚拟的样本。
mixup原理
- λ是由参数为α,β的beta分布计算出来的混合系数。
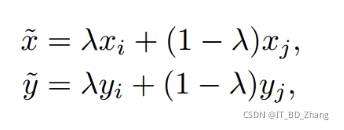
其中xi,xj,是原始输入向量,yi,yj是one-hot过的标签编码
Mixup主要代码及分析
最后附有Bert模型部分代码,进行数据增强
import numpy as np
import torch
import torch.nn as nn
from loss.focal import FocalLoss
LOSS=FocalLoss()
def criterion(batch_x, batch_y, alpha=1.0, use_cuda=True):
if alpha > 0:
#alpha=0.5使得lam有较大概率取0或1附近
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = batch_x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size) #生成打乱的batch_size索引
batch_x:批样本数,shape=[batch_size,channels,width,height]
batch_y:批样本标签,shape=[batch_size]
alpha:生成lam的beta分布参数,一般取0.5效果较好
use_cuda:条件语句:是否使用cuda
#映射为Variable
inputs, targets_a, targets_b = map(Variable, (inputs,targets_a,targets_b))
抽取特征,BACKBONE为粗特征抽取网络
抽取特征,HEAD为精细的特征抽取网络
features = BACKBONE(inputs)
outputs = mixup.mixup_criterion(HEAD, features, targets_a, targets_b, lam)
loss = mixup.mixup_criterion(LOSS, outputs, targets_a, targets_b, lam)
数据增强, 翻译成英文,在翻译回中文
param text: 单个文档的文本
return: 新的列表,列表里面是生成后的文本
translator = Translator(service_urls=['translate.google.cn'])
if text not in self.trans_dist:
text1 = translator.translate(text, dest='en')
text2 = translator.translate(text1.text, dest='zh-cn')
self.trans_dist[text] = text2.text
return self.trans_dist[text]
beta分布中取值
lbeta = np.random.beta(args.alpha, args.alpha)
运用普通的bert 模型 对无标签数据和无标签数据的增强数据进行预测,
outputs_u = model(inputs_u)
outputs_ori = model(inputs_ori)









 京公网安备 11010802041100号
京公网安备 11010802041100号