作者:励志天涯网 | 来源:互联网 | 2023-09-04 10:32
4.2 数据库的设计
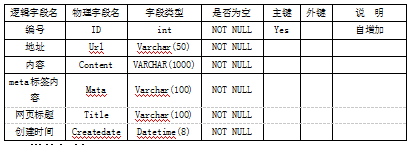
本课题包含一张用于存放抓取回来的网页信息如表1。
4.3 模块设计
该模型按照功能划分为三个部分,一是爬虫抓取网页部分,二是从数据库建立索引部分,三是从前台页面查询部分。系统的功能流程(如图5.1和5.2)。


该系统用3个模块来实现搜索引擎的主要功能。流程如上图所示。
从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。这条件可以是限定的某个域名空间、或者是限定的网页抓取级数。当在获取URL时存在这样的问题就是在实际应用中主要以绝对地址和相对地址来表现。绝对地址是指一个准确的、无歧义的Internet资源的位置,包含域名(主机名)、路径名和文件名;相对地址是绝对地址的一部分。然后把抓取到的网页信息包括网页内容、标题、链接抓取时间等信息经过‘减肥’后保存到网页存储数据库表里。然后通过正则表达式,去掉多余的HTML标签。因为抓取的网页含有HTML标签、Javascript等,对搜索多余的信息,如果抓取到的网页不经过处理就会使搜索变得不够精确。
让爬虫程序能继续运行下去,就得抓取这个网页上的其它URL,所以要用正则将这个网页上的所有URL都取出来放到一个队列里。用同样的方法继续抓取网页,这里将运用到多线程技术。
为了对文档进行索引,Lucene提供了五个基础的类,他们分别是Document,Field,IndexWriter,Analyzer,Directory Document是用来描述文档的,这里的文档可以指一个HTML页面,一封电子邮件,或者是一个文本文件。一个Document对象由多个Field对象组成的。可以把一个Document对象想象成数据库中的一个记录,而每个Field对象就是记录的一个字段。在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer来做的。Analyzer类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的Analyzer。Analyzer把分词后的内容交给IndexWriter来建立索引。
论文目录:




 京公网安备 11010802041100号
京公网安备 11010802041100号