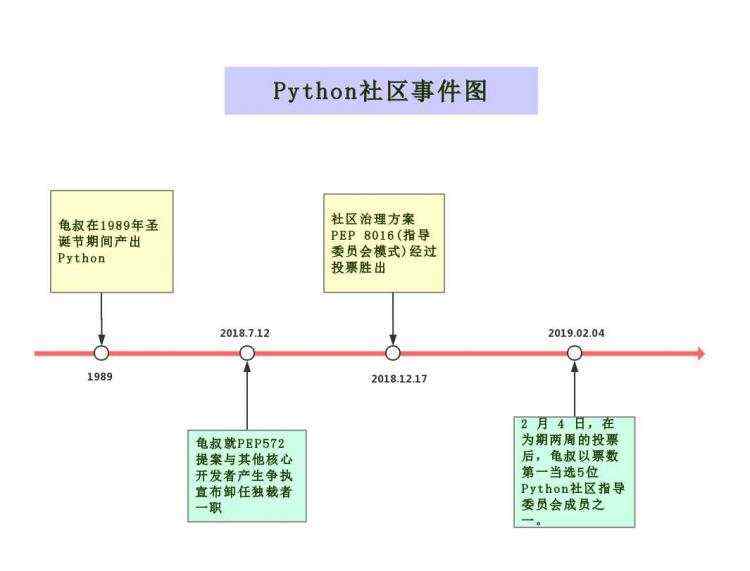
该论文是商汤2020年发表在ECCV上的一篇论文。2018年的CVPR论文《Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving》使用视觉伪点云来进行单目3D目标检测,获得了大幅性能提升,并将性能提升归因为数据表达形式。商汤在该论文中提出了不一样的观点。
基于伪点云表征的方法最开始由论文《Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving》提出,后文统一将该方法简称为pseudo-LiDAR。pseudo-LiDAR极大地缩小了视觉3D和激光3D检测方法之间的差距,其方案非常简单明了,就是模仿激光3D检测的Pipeline,但激光3D检测输入的是点云数据,没有怎么办?直接用单目深度生成伪点云,然后再用现成的激光3D检测模型从伪点云中进行目标检测。从结果上看,基于伪点云表征的方法性能普遍高于基于图像表征的,虽然pseudo-LiDAR作者指出两类方法性能差距主要是数据表征方式的不同,但该观点一直缺乏直接证据的支撑,其正确性值得考究。
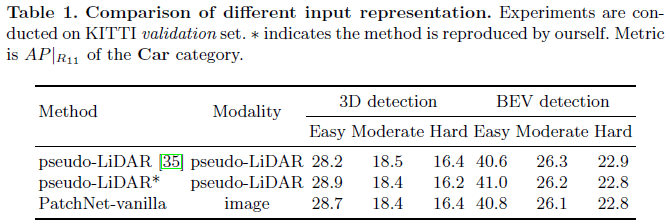
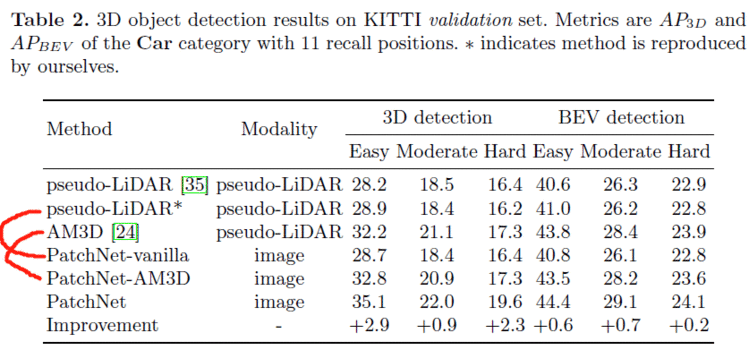
PatchNet-vanilla的前三步和pseudo-LiDAR完全一样,第四步会有所差别。如图2所示,PatchNet-vanilla将MMM个3D点重构成N×N×3N\times N \times 3N×N×3的图像块,作为PatchNet-vanilla的输入,然后可以使用一个1×11\times 11×1接收域的2D卷积层以及一个全局最大池化来实现式(1)一样效果的函数。最终性能如表1所示,可以看到PatchNet-vanilla获得了和pseudo-LiDAR几乎一样的性能,这也证明了伪点云的数据表征形式不是必要的。
2.2 PatchNet
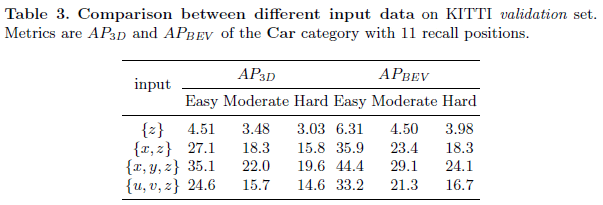
在PatchNet中,首先训练两个CNN分别用于预测2D框和深度图,对于每个检测到的2D目标框,从深度图中抠出对应的区域,利用相机内参将深度值转换成3D空间坐标(得到Fig.3中的cropped patches)。紧接着用一个主干CNN提取这些ROI的深层特征,然后使用mask global pooling分离出前景目标特征,最后通过一个检测头来进行回归目标的3D框(x,y,z,h,w,l,θ)(x,y,z,h,w,l,\theta)(x,y,z,h,w,l,θ)。
mask global pooling是论文提出了一种增强版global pooling方式,利用一个二值掩模(通过卡阈值的方式从深度图中获得)只对前景目标的特征进行global pooling操作,以获得更加鲁棒的特征。











 京公网安备 11010802041100号
京公网安备 11010802041100号