目录
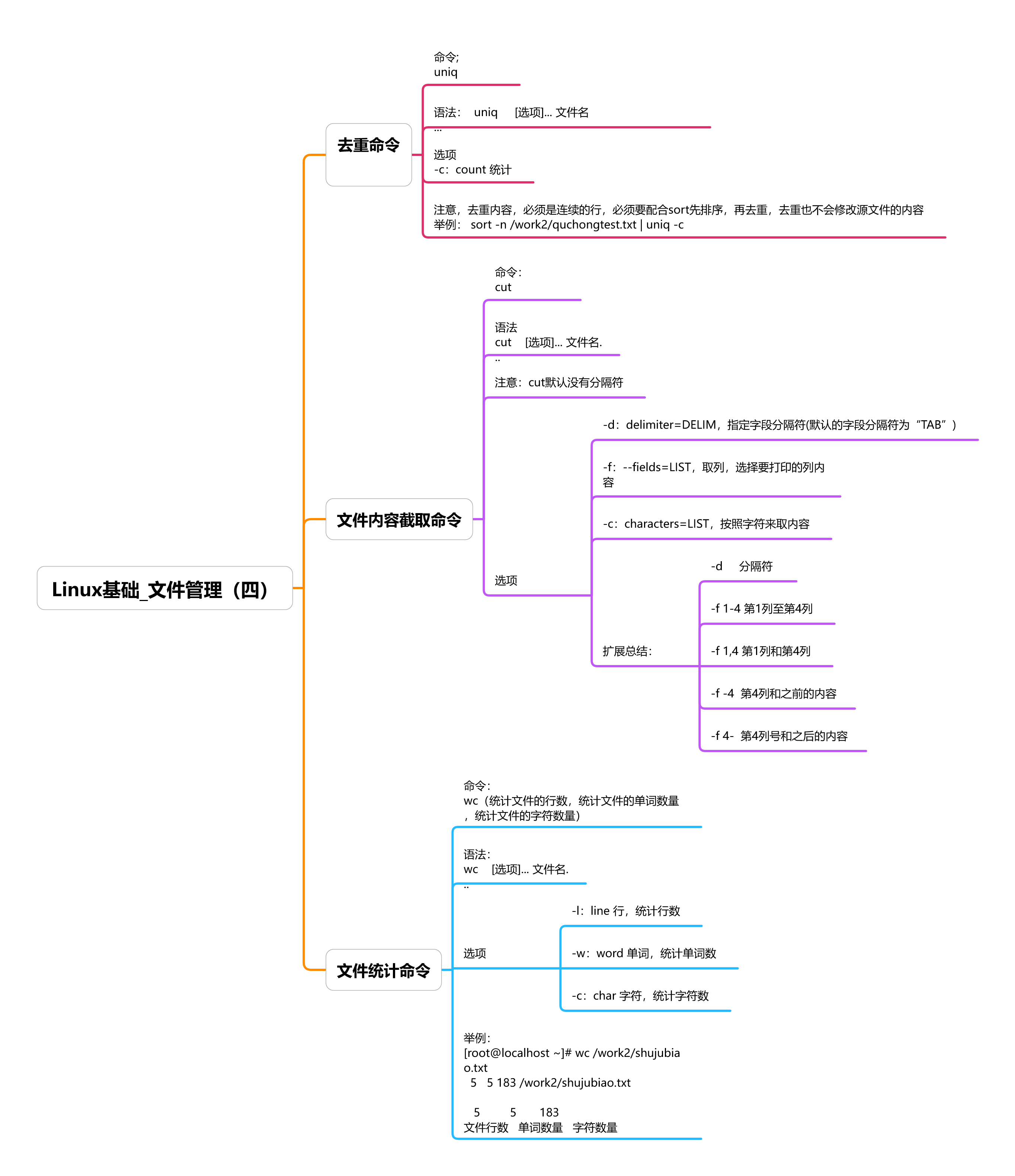
# 命令:
uniq
## 语法
uniq [选项]... 文件名...
## 注意,去重内容,必须是连续的行,必须要配合sort先排序,再去重,去重也不会修改源文件的内容
## 选项
-c:count 统计
## 举例:
[root@localhost ~]# cat >> /work2/quchongtest.txt <
> 2
> 3
> 4
> 1
> 3
> 4
> 2
> 11
> 1
> 1
> 22
> 2
> 2
> 2
> EOF
[root@localhost ~]# uniq /work2/quchongtest.txt
1
2
3
4
1
3
4
2
11
1
22
2
[root@localhost ~]# sort /work2/quchongtest.txt
1
1
1
1
11
2
2
2
2
2
22
3
3
4
4
[root@localhost ~]# sort /work2/quchongtest.txt | uniq
1
11
2
22
3
4
# -c
[root@localhost ~]# sort -n /work2/quchongtest.txt | uniq -c
4 1
5 2
2 3
2 4
1 11
1 22
## 命令:
cut | 截取
## 语法
cut [选项]... 文件名...
## 注意:cut默认没有分隔符
## 选项
-d:--delimiter=DELIM(默认的字段分隔符为“TAB”)
-f:--fields=LIST,选择要打印的列内容
-c:--characters=LIST,按照字符来取内容
## 举例
[root@localhost ~]# cat /work2/shujubiao.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# -d
# -f
## 取出第一列
[root@localhost ~]# cut -d ':' -f 1 /work2/shujubiao.txt
root
bin
daemon
adm
lp
## 取出第一列和第四列
[root@localhost ~]# cut -d ':' -f 1,4 /work2/shujubiao.txt
root:0
bin:1
daemon:2
adm:4
lp:7
## 取出第一列到第四列
[root@localhost ~]# cut -d ':' -f 1-4 /work2/shujubiao.txt
root:x:0:0
bin:x:1:1
daemon:x:2:2
adm:x:3:4
lp:x:4:7
## 取出第四列和之前的所有列
[root@localhost ~]# cut -d ':' -f -4 /work2/shujubiao.txt
root:x:0:0
bin:x:1:1
daemon:x:2:2
adm:x:3:4
lp:x:4:7
## 取出第四列和之后的所有列
[root@localhost ~]# cut -d ':' -f 4- /work2/shujubiao.txt
0:root:/root:/bin/bash
1:bin:/bin:/sbin/nologin
2:daemon:/sbin:/sbin/nologin
4:adm:/var/adm:/sbin/nologin
7:lp:/var/spool/lpd:/sbin/nologin
扩展总结:
总结:
-d 分隔符
-f 1-4 第1列至第4列
-f 1,4 第1列和第4列
-f -4 第4列和之前的内容
-f 4- 第4列号和之后的内容
# -c
[root@localhost ~]# cut -c 1 /work2/shujubiao.txt
r
b
d
a
l
## -c 1-5 打印第一个字符到第五个字符的内容
[root@localhost ~]# cut -c 1-5 /work2/shujubiao.txt
root:
bin:x
daemo
adm:x
lp:x:
## -c -4 打印前面四个字符
[root@localhost ~]# cut -c -4 /work2/shujubiao.txt
root
bin:
daem
adm:
lp:x
## -c 4- 打印第四个字符和之后的内容
[root@localhost ~]# cut -c 4- /work2/shujubiao.txt
t:x:0:0:root:/root:/bin/bash
:x:1:1:bin:/bin:/sbin/nologin
mon:x:2:2:daemon:/sbin:/sbin/nologin
:x:3:4:adm:/var/adm:/sbin/nologin
x:4:7:lp:/var/spool/lpd:/sbin/nologin
## -c -4,4- 打印全部内容 第四个字符也不会重复
[root@localhost ~]# cut -c -4,4- /work2/shujubiao.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
## 命令:
wc:统计文件的行数,统计文件的单词数量,统计文件的字符数量
## 语法
wc [选项]... 文件名...
## 选项
-l:line 行,统计行数
-w:word 单词,统计单词数
-c:char 字符,统计字符数
举例:
[root@localhost ~]# wc /work2/shujubiao.txt
5 5 183 /work2/shujubiao.txt
5 5 183
文件行数 单词数量 字符数量
## -l -w -c 可组合使用
举例:
[root@localhost ~]# wc -l /work2/shujubiao.txt
5 /work2/shujubiao.txt
[root@localhost ~]# wc -w /work2/shujubiao.txt
5 /work2/shujubiao.txt
[root@localhost ~]# wc -c /work2/shujubiao.txt
183 /work2/shujubiao.txt
[root@localhost ~]# wc -lw /work2/shujubiao.txt
5 5 /work2/shujubiao.txt
[root@localhost ~]# wc -wc /work2/shujubiao.txt
5 183 /work2/shujubiao.txt
[root@localhost ~]# wc -lc /work2/shujubiao.txt
5 183 /work2/shujubiao.txt





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 