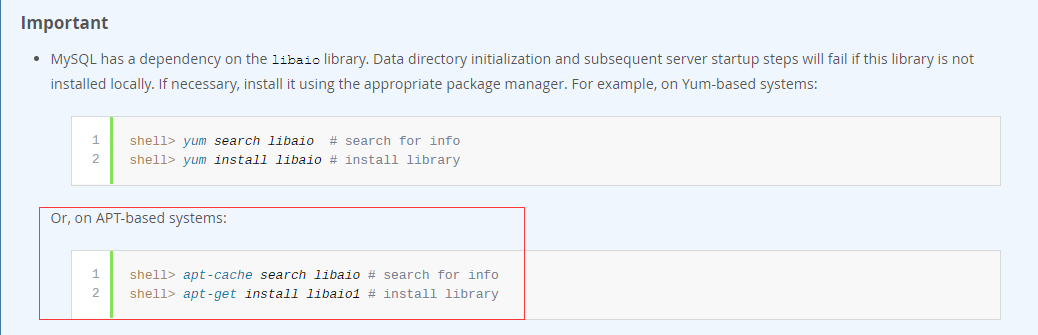
有了上一篇关于pids的热身之后,我们这篇将介绍稍微复杂点的内存控制。
本篇所有例子都在ubuntu-server-x86_64 16.04下执行通过
代码总会有bug,有时会有内存泄漏,或者有意想不到的内存分配情况,或者这是个恶意程序,运行起来就是为了榨干系统内存,让其它进程无法分配到足够的内存而出现异常,如果系统配置了交换分区,会导致系统大量使用交换分区,从而系统运行很慢。
站在一个普通Linux开发者的角度,如果能控制一个或者一组进程所能使用的内存数,那么就算代码有bug,内存泄漏也不会对系统造成影响,因为可以设置内存使用量的上限,当到达这个值之后可以将进程重启。
站在一个系统管理者的角度,如果能限制每组进程所能使用的内存量,那么不管程序的质量如何,都能将它们对系统的影响降到最低,从而保证整个系统的稳定性。
限制cgroup中所有进程所能使用的物理内存总量
限制cgroup中所有进程所能使用的物理内存+交换空间总量(CONFIG_MEMCG_SWAP): 一般在server上,不太会用到swap空间,所以不在这里介绍这部分内容。
限制cgroup中所有进程所能使用的内核内存总量及其它一些内核资源(CONFIG_MEMCG_KMEM): 限制内核内存有什么用呢?其实限制内核内存就是限制当前cgroup所能使用的内核资源,比如进程的内核栈空间,socket所占用的内存空间等,通过限制内核内存,当内存吃紧时,可以阻止当前cgroup继续创建进程以及向内核申请分配更多的内核资源。由于这块功能被使用的较少,本篇中也不对它做介绍。
由于memory subsystem比较耗资源,所以内核专门添加了一个参数cgroup_disable=memory来禁用整个memory subsystem,这个参数可以通过GRUB在启动系统的时候传给内核,加了这个参数后内核将不再进行memory subsystem相关的计算工作,在系统中也不能挂载memory subsystem。
上面提到的CONFIG_MEMCG_SWAP和CONFIG_MEMCG_KMEM都是扩展功能,在使用前请确认当前内核是否支持,下面看看ubuntu 16.04的内核:
#这里CONFIG_MEMCG_SWAP和CONFIG_MEMCG_KMEM等于y表示内核已经编译了该模块,即支持相关功能
dev@dev:~$ cat /boot/config-`uname -r`|grep CONFIG_MEMCG
CONFIG_MEMCG=y
CONFIG_MEMCG_SWAP=y
# CONFIG_MEMCG_SWAP_ENABLED is not set
CONFIG_MEMCG_KMEM=y
CONFIG_MEMCG_SWAP控制内核是否支持Swap Extension,而CONFIG_MEMCG_SWAP_ENABLED(3.6以后的内核新加的参数)控制默认情况下是否使用Swap Extension,由于Swap Extension比较耗资源,所以很多发行版(比如ubuntu)默认情况下会禁用该功能(这也是上面那行被注释掉的原因),当然用户也可以根据实际情况,通过设置内核参数swapaccount=0或者1来手动禁用和启用Swap Extension。
在ubuntu 16.04里面,systemd已经帮我们将memory绑定到了/sys/fs/cgroup/memory
#如果这里发现有多行结果,说明这颗cgroup数被绑定到了多个地方,
#不过不要担心,由于它们都是指向同一颗cgroup树,所以它们里面的内容是一模一样的
dev@dev:~$ mount|grep memory
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
在/sys/fs/cgroup/memory下创建一个子目录即创建了一个子cgroup
#--------------------------第一个shell窗口----------------------
dev@dev:~$ cd /sys/fs/cgroup/memory
dev@dev:/sys/fs/cgroup/memory$ sudo mkdir test
dev@dev:/sys/fs/cgroup/memory$ ls test
cgroup.clone_children memory.kmem.failcnt memory.kmem.tcp.limit_in_bytes memory.max_usage_in_bytes memory.soft_limit_in_bytes notify_on_release
cgroup.event_control memory.kmem.limit_in_bytes memory.kmem.tcp.max_usage_in_bytes memory.move_charge_at_immigrate memory.stat tasks
cgroup.procs memory.kmem.max_usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.numa_stat memory.swappiness
memory.failcnt memory.kmem.slabinfo memory.kmem.usage_in_bytes memory.oom_control memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.failcnt memory.limit_in_bytes memory.pressure_level memory.use_hierarchy
从上面ls的输出可以看出,除了每个cgroup都有的那几个文件外,和memory相关的文件还不少(由于ubuntu默认禁用了CONFIG_MEMCG_SWAP,所以这里看不到swap相关的文件),这里先做个大概介绍(kernel相关的文件除外),后面会详细介绍每个文件的作用
cgroup.event_control #用于eventfd的接口
memory.usage_in_bytes #显示当前已用的内存
memory.limit_in_bytes #设置/显示当前限制的内存额度
memory.failcnt #显示内存使用量达到限制值的次数
memory.max_usage_in_bytes #历史内存最大使用量
memory.soft_limit_in_bytes #设置/显示当前限制的内存软额度
memory.stat #显示当前cgroup的内存使用情况
memory.use_hierarchy #设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
memory.force_empty #触发系统立即尽可能的回收当前cgroup中可以回收的内存
memory.pressure_level #设置内存压力的通知事件,配合cgroup.event_control一起使用
memory.swappiness #设置和显示当前的swappiness
memory.move_charge_at_immigrate #设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
memory.oom_control #设置/显示oom controls相关的配置
memory.numa_stat #显示numa相关的内存
参考:eventfd,numa
和“创建并管理cgroup”中介绍的一样,往cgroup中添加进程只要将进程号写入cgroup.procs就可以了
注意:本篇将以进程为单位进行操作,不考虑以线程为单位进行管理(原因见“创建并管理cgroup”中cgroup.pro与tasks的区别),也即只写cgroup.procs文件,不会写tasks文件
#--------------------------第二个shell窗口----------------------
#重新打开一个shell窗口,避免相互影响
dev@dev:~$ cd /sys/fs/cgroup/memory/test/
dev@dev:/sys/fs/cgroup/memory/test$ echo $$
4589
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo $$ >> cgroup.procs"
#运行top命令,这样这个cgroup消耗的内存会多点,便于观察
dev@dev:/sys/fs/cgroup/memory/test$ top
#后续操作不再在这个窗口进行,避免在这个bash中运行进程影响cgropu里面的进程数及相关统计
设置限额很简单,写文件memory.limit_in_bytes就可以了,请仔细看示例
#--------------------------第一个shell窗口----------------------
#回到第一个shell窗口
dev@dev:/sys/fs/cgroup/memory$ cd test
#这里两个进程id分别时第二个窗口的bash和top进程
dev@dev:/sys/fs/cgroup/memory/test$ cat cgroup.procs
4589
4664
#开始设置之前,看看当前使用的内存数量,这里的单位是字节
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.usage_in_bytes
835584
#设置1M的限额
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 1M > memory.limit_in_bytes"
#设置完之后记得要查看一下这个文件,因为内核要考虑页对齐, 所以生效的数量不一定完全等于设置的数量
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.limit_in_bytes
1048576
#如果不再需要限制这个cgroup,写-1到文件memory.limit_in_bytes即可
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo -1 > memory.limit_in_bytes"
#这时可以看到limit被设置成了一个很大的数字
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.limit_in_bytes
9223372036854771712
如果设置的限额比当前已经使用的内存少呢?如上面显示当前bash用了800多k,如果我设置limit为400K会怎么样?
#--------------------------第一个shell窗口----------------------
#先用free看下当前swap被用了多少
dev@dev:/sys/fs/cgroup/memory/test$ free
total used free shared buff/cache available
Mem: 500192 45000 34200 2644 420992 424020
Swap: 524284 16 524268
#设置内存限额为400K
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 400K > memory.limit_in_bytes"
#再看当前cgroup的内存使用情况
#发现内存占用少了很多,刚好在400K以内,原来用的那些内存都去哪了呢?
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.usage_in_bytes
401408
#再看swap空间的占用情况,和刚开始比,多了500-16=384K,说明内存中的数据被移到了swap上
dev@dev:/sys/fs/cgroup/memory/test$ free
total used free shared buff/cache available
Mem: 500192 43324 35132 2644 421736 425688
Swap: 524284 500 523784
#这个时候再来看failcnt,发现有453次之多(隔几秒再看这个文件,发现次数在增长)
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.failcnt
453
#再看看memory.stat(这里只显示部分内容),发现物理内存用了400K,
#但有很多pgmajfault以及pgpgin和pgpgout,说明发生了很多的swap in和swap out
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.stat
rss 409600
total_pgpgin 4166
total_pgpgout 4066
total_pgfault 7558
total_pgmajfault 419
#从上面的结果可以看出,当物理内存不够时,就会触发memory.failcnt里面的数量加1,
#但进程不会被kill掉,那是因为内核会尝试将物理内存中的数据移动到swap空间中,从而让内存分配成功
如果设置的限额过小,就算swap out部分内存后还是不够会怎么样?
#--------------------------第一个shell窗口----------------------
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 1K > memory.limit_in_bytes"
#进程已经不在了(第二个窗口已经挂掉了)
dev@dev:/sys/fs/cgroup/memory/test$ cat cgroup.procs
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.usage_in_bytes
0
#从这里的结果可以看出,第二个窗口的bash和top都被kill掉了
从上面的这些测试可以看出,一旦设置了内存限制,将立即生效,并且当物理内存使用量达到limit的时候,memory.failcnt的内容会加1,但这时进程不一定就会被kill掉,内核会尽量将物理内存中的数据移到swap空间上去,如果实在是没办法移动了(设置的limit过小,或者swap空间不足),默认情况下,就会kill掉cgroup里面继续申请内存的进程。
当物理内存达到上限后,系统的默认行为是kill掉cgroup中继续申请内存的进程,那么怎么控制这样的行为呢?答案是配置memory.oom_control
这个文件里面包含了一个控制是否为当前cgroup启动OOM-killer的标识。如果写0到这个文件,将启动OOM-killer,当内核无法给进程分配足够的内存时,将会直接kill掉该进程;如果写1到这个文件,表示不启动OOM-killer,当内核无法给进程分配足够的内存时,将会暂停该进程直到有空余的内存之后再继续运行;同时,memory.oom_control还包含一个只读的under_oom字段,用来表示当前是否已经进入oom状态,也即是否有进程被暂停了。
注意:root cgroup的oom killer是不能被禁用的
为了演示OOM-killer的功能,创建了下面这样一个程序,用来向系统申请内存,它会每秒消耗1M的内存。
#include
#include
#include
#include
#define MB (1024 * 1024)
int main(int argc, char *argv[])
{
char *p;
int i = 0;
while(1) {
p = (char *)malloc(MB);
memset(p, 0, MB);
printf("%dM memory allocated\n", ++i);
sleep(1);
}
return 0;
}
保存上面的程序到文件~/mem-allocate.c,然后编译并测试
#--------------------------第一个shell窗口----------------------
#编译上面的文件
dev@dev:/sys/fs/cgroup/memory/test$ gcc ~/mem-allocate.c -o ~/mem-allocate
#设置内存限额为5M
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 5M > memory.limit_in_bytes"
#将当前bash加入到test中,这样这个bash创建的所有进程都会自动加入到test中
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo $$ >> cgroup.procs"
#默认情况下,memory.oom_control的值为0,即默认启用oom killer
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.oom_control
oom_kill_disable 0
under_oom 0
#为了避免受swap空间的影响,设置swappiness为0来禁止当前cgroup使用swap
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 0 > memory.swappiness"
#当分配第5M内存时,由于总内存量超过了5M,所以进程被kill了
dev@dev:/sys/fs/cgroup/memory/test$ ~/mem-allocate
1M memory allocated
2M memory allocated
3M memory allocated
4M memory allocated
Killed
#设置oom_control为1,这样内存达到限额的时候会暂停
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 1 >> memory.oom_control"
#跟预期的一样,程序被暂停了
dev@dev:/sys/fs/cgroup/memory/test$ ~/mem-allocate
1M memory allocated
2M memory allocated
3M memory allocated
4M memory allocated
#--------------------------第二个shell窗口----------------------
#再打开一个窗口
dev@dev:~$ cd /sys/fs/cgroup/memory/test/
#这时候可以看到memory.oom_control里面under_oom的值为1,表示当前已经oom了
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.oom_control
oom_kill_disable 1
under_oom 1
#修改test的额度为7M
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 7M > memory.limit_in_bytes"
#--------------------------第一个shell窗口----------------------
#再回到第一个窗口,会发现进程mem-allocate继续执行了两步,然后暂停在6M那里了
dev@dev:/sys/fs/cgroup/memory/test$ ~/mem-allocate
1M memory allocated
2M memory allocated
3M memory allocated
4M memory allocated
5M memory allocated
6M memory allocated
该文件还可以配合cgroup.event_control实现OOM的通知,当OOM发生时,可以收到相关的事件,下面是用于测试的程序,流程大概如下:
利用函数eventfd()创建一个efd;
打开文件memory.oom_control,得到ofd;
往cgroup.event_control中写入这么一串:
通过读efd得到通知,然后打印一句话到终端
#include
#include
#include
#include
#include
#include
#include
#include
#include
static inline void die(const char *msg)
{
fprintf(stderr, "error: %s: %s(%d)\n", msg, strerror(errno), errno);
exit(EXIT_FAILURE);
}
#define BUFSIZE 256
int main(int argc, char *argv[])
{
char buf[BUFSIZE];
int efd, cfd, ofd;
uint64_t u;
if ((efd = eventfd(0, 0)) == -1)
die("eventfd");
snprintf(buf, BUFSIZE, "%s/%s", argv[1], "cgroup.event_control");
if ((cfd = open(buf, O_WRONLY)) == -1)
die("cgroup.event_control");
snprintf(buf, BUFSIZE, "%s/%s", argv[1], "memory.oom_control");
if ((ofd = open(buf, O_RDONLY)) == -1)
die("memory.oom_control");
snprintf(buf, BUFSIZE, "%d %d", efd, ofd);
if (write(cfd, buf, strlen(buf)) == -1)
die("write cgroup.event_control");
if (close(cfd) == -1)
die("close cgroup.event_control");
for (;;) {
if (read(efd, &u, sizeof(uint64_t)) != sizeof(uint64_t))
die("read eventfd");
printf("mem_cgroup oom event received\n");
}
return 0;
}
将上面的文件保存为~/oom_listen.c,然后测试如下
#--------------------------第二个shell窗口----------------------
#编译程序
dev@dev:/sys/fs/cgroup/memory/test$ gcc ~/oom_listen.c -o ~/oom_listen
#启用oom killer
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 0 >> memory.oom_control"
#设置限额为2M,缩短测试周期
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 2M > memory.limit_in_bytes"
#启动监听程序
dev@dev:/sys/fs/cgroup/memory/test$ ~/oom_listen /sys/fs/cgroup/memory/test
#--------------------------第一个shell窗口----------------------
#连续运行两次mem-allocate,使它触发oom killer
dev@dev:/sys/fs/cgroup/memory/test$ ~/mem-allocate
1M memory allocated
Killed
dev@dev:/sys/fs/cgroup/memory/test$ ~/mem-allocate
1M memory allocated
Killed
#--------------------------第二个shell窗口----------------------
#回到第二个窗口可以看到,收到了两次oom事件
dev@dev:/sys/fs/cgroup/memory/test$ ~/oom_listen /sys/fs/cgroup/memory/test
mem_cgroup oom event received
mem_cgroup oom event received
当一个进程从一个cgroup移动到另一个cgroup时,默认情况下,该进程已经占用的内存还是统计在原来的cgroup里面,不会占用新cgroup的配额,但新分配的内存会统计到新的cgroup中(包括swap out到交换空间后再swap in到物理内存中的部分)。
我们可以通过设置memory.move_charge_at_immigrate让进程所占用的内存随着进程的迁移一起迁移到新的cgroup中。
enable: echo 1 > memory.move_charge_at_immigrate
disable:echo 0 > memory.move_charge_at_immigrate
注意: 就算设置为1,但如果不是thread group的leader,这个task占用的内存也不能被迁移过去。换句话说,如果以线程为单位进行迁移,必须是进程的第一个线程,如果以进程为单位进行迁移,就没有这个问题。
当memory.move_charge_at_immigrate被设置成1之后,进程占用的内存将会被统计到目的cgroup中,如果目的cgroup没有足够的内存,系统将尝试回收目的cgroup的部分内存(和系统内存紧张时的机制一样,删除不常用的file backed的内存或者swap out到交换空间上,请参考Linux内存管理),如果回收不成功,那么进程迁移将失败。
注意:迁移内存占用数据是比较耗时的操作。
当memory.move_charge_at_immigrate为0时,就算当前cgroup中里面的进程都已经移动到其它cgropu中去了,由于进程已经占用的内存没有被统计过去,当前cgroup有可能还占用很多内存,当移除该cgroup时,占用的内存需要统计到谁头上呢?答案是依赖memory.use_hierarchy的值,如果该值为0,将会统计到root cgroup里;如果值为1,将统计到它的父cgroup里面。
当向memory.force_empty文件写入0时(echo 0 > memory.force_empty),将会立即触发系统尽可能的回收该cgroup占用的内存。该功能主要使用场景是移除cgroup前(cgroup中没有进程),先执行该命令,可以尽可能的回收该cgropu占用的内存,这样迁移内存的占用数据到父cgroup或者root cgroup时会快些。
该文件的值默认和全局的swappiness(/proc/sys/vm/swappiness)一样,修改该文件只对当前cgroup生效,其功能和全局的swappiness一样,请参考Linux交换空间中关于swappiness的介绍。
注意:有一点和全局的swappiness不同,那就是如果这个文件被设置成0,就算系统配置的有交换空间,当前cgroup也不会使用交换空间。
该文件内容为0时,表示不使用继承,即父子cgroup之间没有关系;当该文件内容为1时,子cgroup所占用的内存会统计到所有祖先cgroup中。
如果该文件内容为1,当一个cgroup内存吃紧时,会触发系统回收它以及它所有子孙cgroup的内存。
注意: 当该cgroup下面有子cgroup或者父cgroup已经将该文件设置成了1,那么当前cgroup中的该文件就不能被修改。
#当前cgroup和父cgroup里都是1
dev@dev:/sys/fs/cgroup/memory/test$ cat memory.use_hierarchy
1
dev@dev:/sys/fs/cgroup/memory/test$ cat ../memory.use_hierarchy
1
#由于父cgroup里面的值为1,所以修改当前cgroup的值失败
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 0 > ./memory.use_hierarchy"
sh: echo: I/O error
#由于父cgroup里面有子cgroup(至少有当前cgroup这么一个子cgroup),
#修改父cgroup里面的值也失败
dev@dev:/sys/fs/cgroup/memory/test$ sudo sh -c "echo 0 > ../memory.use_hierarchy"
sh: echo: I/O error
有了hard limit(memory.limit_in_bytes),为什么还要soft limit呢?hard limit是一个硬性标准,绝对不能超过这个值,而soft limit可以被超越,既然能被超越,要这个配置还有啥用?先看看它的特点
当系统内存充裕时,soft limit不起任何作用
当系统内存吃紧时,系统会尽量的将cgroup的内存限制在soft limit值之下(内核会尽量,但不100%保证)
从它的特点可以看出,它的作用主要发生在系统内存吃紧时,如果没有soft limit,那么所有的cgroup一起竞争内存资源,占用内存多的cgroup不会让着内存占用少的cgroup,这样就会出现某些cgroup内存饥饿的情况。如果配置了soft limit,那么当系统内存吃紧时,系统会让超过soft limit的cgroup释放出超过soft limit的那部分内存(有可能更多),这样其它cgroup就有了更多的机会分配到内存。
从上面的分析看出,这其实是系统内存不足时的一种妥协机制,给次等重要的进程设置soft limit,当系统内存吃紧时,把机会让给其它重要的进程。
注意: 当系统内存吃紧且cgroup达到soft limit时,系统为了把当前cgroup的内存使用量控制在soft limit下,在收到当前cgroup新的内存分配请求时,就会触发回收内存操作,所以一旦到达这个状态,就会频繁的触发对当前cgroup的内存回收操作,会严重影响当前cgroup的性能。
这个文件主要用来监控当前cgroup的内存压力,当内存压力大时(即已使用内存快达到设置的限额),在分配内存之前需要先回收部分内存,从而影响内存分配速度,影响性能,而通过监控当前cgroup的内存压力,可以在有压力的时候采取一定的行动来改善当前cgroup的性能,比如关闭当前cgroup中不重要的服务等。目前有三种压力水平:
意味着系统在开始为当前cgroup分配内存之前,需要先回收内存中的数据了,这时候回收的是在磁盘上有对应文件的内存数据。
意味着系统已经开始频繁为当前cgroup使用交换空间了。
快撑不住了,系统随时有可能kill掉cgroup中的进程。
如何配置相关的监听事件呢?和memory.oom_control类似,大概步骤如下:
利用函数eventfd(2)创建一个event_fd
打开文件memory.pressure_level,得到pressure_level_fd
往cgroup.event_control中写入这么一串:
然后通过读event_fd得到通知
注意: 多个level可能要创建多个event_fd,好像没有办法共用一个(本人没有测试过)
我们可以通过cgroup的事件通知机制来实现对内存的监控,当内存使用量穿过(变得高于或者低于)我们设置的值时,就会收到通知。使用方法和memory.oom_control类似,大概步骤如下:
利用函数eventfd(2)创建一个event_fd
打开文件memory.usage_in_bytes,得到usage_in_bytes_fd
往cgroup.event_control中写入这么一串:
然后通过读event_fd得到通知
这个文件包含的统计项比较细,需要一些内核的内存管理知识才能看懂,这里就不介绍了(怕说错)。详细信息可以参考Memory Resource Controller中的“5.2 stat file”。这里有几个需要注意的地方:
里面total开头的统计项包含了子cgroup的数据(前提条件是memory.use_hierarchy等于1)。
里面的’rss + file_mapped”才约等于是我们常说的RSS(ps aux命令看到的RSS)
文件(动态库和可执行文件)及共享内存可以在多个进程之间共享,不过它们只会统计到他们的owner cgroup中的file_mapped去。(不确定是怎么定义owner的,但如果看到当前cgroup的file_mapped值很小,说明共享的数据没有算到它头上,而是其它的cgroup)
本篇没有介绍swap和kernel相关的内容,不过在实际使用过程中一定要留意swap空间,如果系统使用了交换空间,那么设置限额时一定要注意一点,那就是当cgroup的物理空间不够时,内核会将不常用的内存swap out到交换空间上,从而导致一直不触发oom killer,而是不停的swap out/in,导致cgroup中的进程运行速度很慢。如果一定要用交换空间,最好的办法是限制swap+物理内存的额度,虽然我们在这篇中没有介绍这部分内容,但其使用方法和限制物理内存是一样的,只是换做写文件memory.memsw.limit_in_bytes罢了。
Memory Resource Controller
memory subsystem

![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有