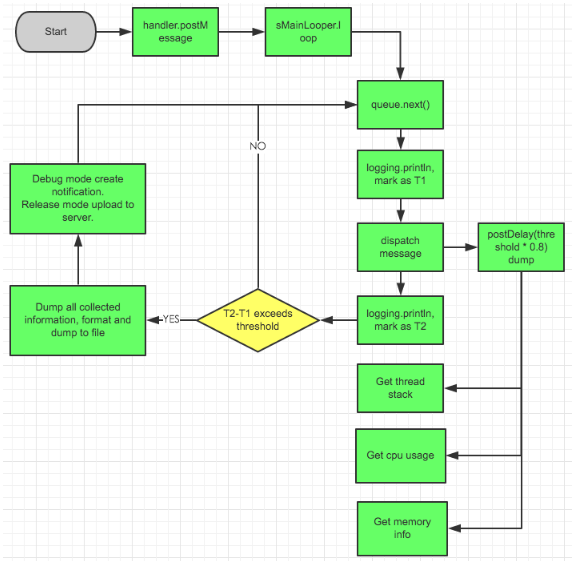
两个git commit具有相同的机会是什么 abbrev-commit
我看到git history默认显示git abbrev-commit是为了简化和美观。但是,两个相同的东西abbrev-commit出现在一个git repo中的机会是什么?
零。或更确切地说:您的回购中有SHA1冲突的机会相同。
当git命令返回缩写引用列表时,如果发现两个缩写(哈希摘要的前缀)相同,则会从完整的SHA1哈希中向这些特定引用添加更多字符,直到它们不再相同为止。
有几种不同的方法来回答这个问题。一个人用数学告诉你在各种拟议条件下机会是多少。另一个是问Git 实际做什么,但是问这个问题时,答案取决于您特定的Git版本。
机会取决于缩写的长度和存储库中对象的数量。(在某些情况下,如果您知道所需的对象类型,则可以在潜在匹配描述不同对象类型的情况下消除冲突的歧义。在这种情况下,您可以简单地在以下公式中减小值n。)
由于StackOverflow不会格式化LaTeX,因此我在自己的(正在进行中的)书的第77页上有一个屏幕截图。我把这个做的太大了,抱歉:
要找到所需的数字,请用正确的值替换n和r并评估p-bar,然后从1中减去。N是对象的数量:
$ git count-objects -v count: 49 size: 568 in-pack: 307916 packs: 40 size-pack: 176024 prune-packable: 0 garbage: 0 size-garbage: 0
该存储库大约有300,000个对象(大多数都打包;只有49个松散对象),因此n约为300k。您的存储库当然会有所不同。
然后,为r插入正确的值。如果使用完整的哈希,则r的值为2 160或1461501637330902918218284884816216283019655932542976。如果将哈希缩写为四个字符(这是Git可接受的最小输入),则为2 16或65536,因为每个字符提供4位。完整散列为40个字符长,因此完整散列公式中为160个字符。
如果使用或,则由您自行选择长度。如果您没有提供数字,Git将使用一个不足的公式来选择一个数字。1 但它不仅使用该数字!git rev-parse --short=numbergit log --abbrev=number --abbrev-commit
Modern Git 检查缩写哈希在当前数据库中是否唯一。这不是一个概率猜测,只是一个循环中执行的文字测试:
length =loop { generate short hash using characters is short hash unambiguous? if so, we're done - exit the loop increment length }
这样就不会与您现在拥有的对象发生碰撞。
不幸的是,如果再添加一个对象,则新对象可能会与基于旧对象生成的缩写哈希冲突。使用上面的公式来计算此概率,知道所有现有键都不会发生冲突,再加上缩写哈希的长度所隐含的r的值。它可能仍然相当不错,因为即使4个字符也能使您获得6536分之一。但是请注意,随着添加更多对象,它会迅速恶化。
当Linus Torvald的第一部分代码进入后来成为Git 2.11的代码时,就存在该循环检查代码。我不知道回一个有多远的地方它不会发生,但它绝对没有在一些很老的版本的Git发生。
1从Git 2.11开始,Git使用以下事实:对于大量n个键,在n = sqrt(r)时发生50%的冲突率。Linus Torvalds添加了以下代码:
+ if (len <16 && !status && (flags & GET_SHA1_AUTOMATIC)) {
+ unsigned int expect_collision = 1 <<(len * 2);
+ if (ds.nrobjects > expect_collision) {
+ default_automatic_abbrev = len+1;
+ return SHORT_NAME_AMBIGUOUS;
+ }
+ }
在提交e6c587c733了Git的2.11。随后改进了commit8e3f52d778。但是50%的可能性太大。




![[ipsec][strongswan]strongswan源码分析(五)plugin的配置文件的添加方法与管理架构解析](https://img2.php1.cn/3cdc5/3909/339/3e35aa3d77315ada.png)


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 