篇首语:本文由编程笔记#小编为大家整理,主要介绍了联邦学习---论文汇总笔记(十四)相关的知识,希望对你有一定的参考价值。
FedCD(克隆和删除模型动态地对相似数据的设备分组)
1.机器学习的目标是在不同的数据源下效果都很好,数据受到隐私严格约束,有限的通信带宽和内存。
2.在Non-iid下导致不同设备的更新冲突,训练轮之间明显震荡,收敛速度变慢。
1.共享全局数据:但是一个全局共享数据很难代表所有的设备数据,不可行。
2.peer-to-peer: 单一模型参与,可以提高准确性,增加模型数量和通信成本,个别学习者不参与训练。
3.个性化联邦学习:基于不可知元学习(MAML)
克隆高性能模型,并删除低性能模型,同时更新每个设备的模型分数。
在每一个milestone阶段,服务器克隆每一个模型,并压缩;
在每一个训练阶段,每一个参与方设备训练Epoch,压缩模型,将权重更新和分数发送到服务器,分数是由验证集给出;
服务器更新全局模型,取该模型的评分加权,将全局模型重新部署,并删除低评分模型。
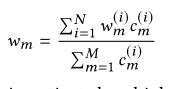
分数基于准确率,当k=3时,归一化平均的验证结果精度最高,同时强烈震荡,
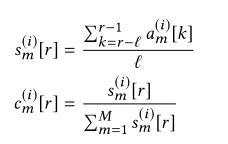
模型克隆,子模型分数为1-p,父模型分数为p,
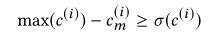

算法解读
输入:设备N,全局模型m,初始化模型的分数
c
m
(
i
)
c^{(i)}_m
cm(i)
对于T轮训练,每轮从K设备中选取子集
每一轮的设备训练全部分数不为0的模型
全局模型:对评分不为0的模型进行权重平均,更新模型
使用本地验证数据集评估模型
参照验证精确度归一化验证更新分数
对于每一个设备,删除性能不好的设备
删除分数为0的设备
对于每一个milestone,如果分数>0,克隆模型为M+m
模型数量为2M
设备性能定义:本地测试数据集上的最高评分模型的准确性。量化压缩允许在设备商使用多个更小的模型。
边缘设备:原型(数据分布),分数
分层原型
以英语为主的国家和以西班牙语为主的国家(这些国家是元原型)所有年龄层(这些年龄层是原型)用户手机的下一个单词的预测。同一个国家的不同年龄组可能会有一些共同的方言,但由于语言障碍,不同国家的共同词汇可能非常有限。
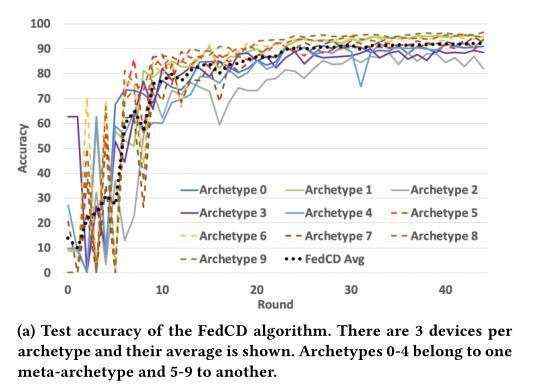
构建拥有0,1,2,3,4和5,6,7,8,9标签的两种数据集合,构建10中原型,原型1仅获得0,1,2,3,4标签,偏差为服从(0.6~0.7)的均匀分布,偏差定义为本地数据,一个设备上有标签3的数量是5k,有0,1,2,3,4的数量是(1-b)/4*5k,设置在第5,15,25,30轮克隆。











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有