单词联想 《A. Hard, K. Rao, R. Mathews, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage, Federated learning for mobile keyboard prediction. 2018. [Online]. Available: arXiv:1811.03604》
挑战:用户为了保护个人隐私可能不愿意分享数据或者节省手机有限的带宽/电量
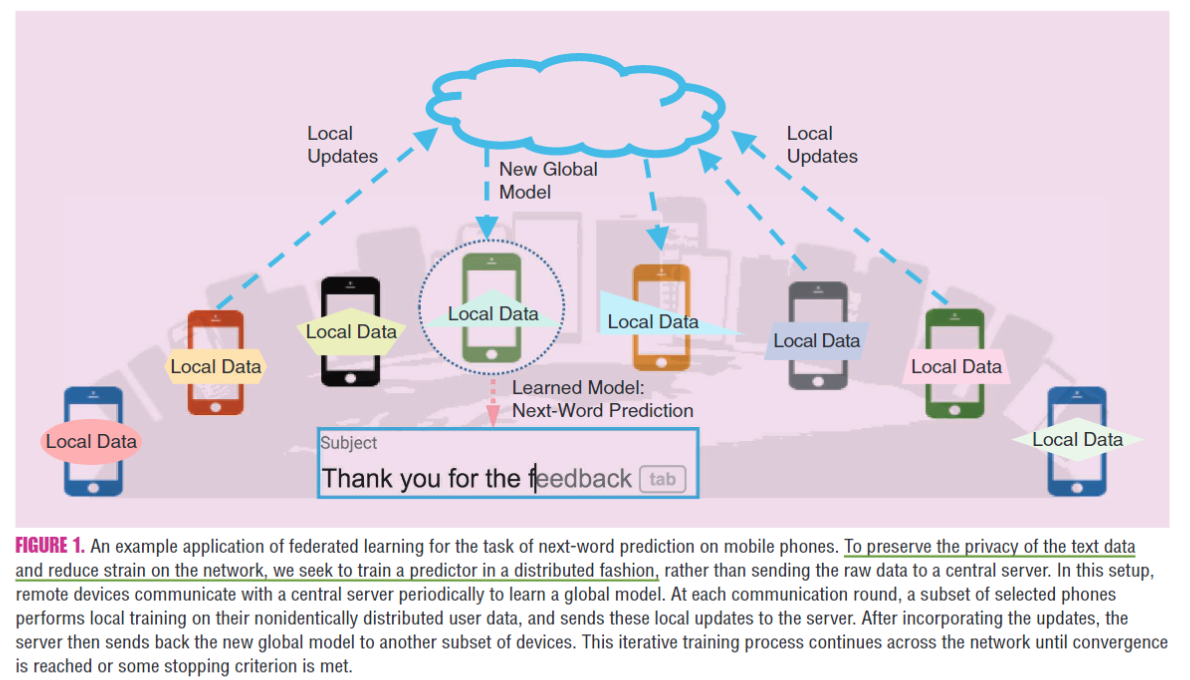
FL有潜力在不损害用户体验或泄露隐私信息前提下在智能手机上启用预测功能
组织机构 --医疗机构
L. Huang, Y. Yin, Z. Fu, S. Zhang, H. Deng, and D. Liu, LoAdaBoost: Loss-based adaboost federated machine learning on medical data. 2018. [Online]. Available: arXiv:1811.12629
物联网-- 可穿戴设备、自动驾驶车辆、智能家居
FL方法在公司的应用
K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konecnyet al., “Towards federated learning at scale: System design,” in Proc. Conf. Machine Learning and Systems, 2019.
M. J. Sheller, G. A. Reina, B. Edwards, J. Martin, and S. Bakas, “Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation,” in Proc. Int. MICCAI Brainlesion Workshop, 2018, pp. 92–104. doi: 10.1007/978-3-030 -11723-8_9.
隐私敏感应用
T. S. Brisimi, R. Chen, T. Mela, A. Olshevsky, I. C. Paschalidis, and W. Shi, “Federated learning of predictive models from federated electronic health records,” Int. J. Medical Informatics, vol. 112, Apr. 2018, pp. 59–67. doi: 10.1016/j.ijmedinf.2018.01.007
L. Huang, Y. Yin, Z. Fu, S. Zhang, H. Deng, and D. Liu, LoAdaBoost: Loss-based adaboost federated machine learning on medical data. 2018. [Online]. Available: arXiv:1811.12629
[42]《V. Smith, C.-K. Chiang, M. Sanjabi, and A. Talwalkar, “Federated multi-task learning,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 4424–4434》 数据生成范例违反了分布式优化中经常使用的独立且均匀分布(i.i.d.)的假设,可能会增加问题建模,理论分析和解决方案的经验评估方面的复杂性
小批处理优化方法涉及扩展经典的随机方法以一次处理多个数据点,已成为数据中心环境中分布式机器学习的流行范例。然而,实际上,他们在适应通信计算权衡方面显示出有限的灵活性[53]《S. Zhang, A. E. Choromanska, and Y. LeCun, “Deep learning with elastic averaging SGD,” in Proc. Advances in Neural Information Processing Systems, 2015, pp. 685–693》
最近的一些方法:通过允许在每个通信回合中并行地将变量应用于每台计算机(而不是仅局部地计算它们然后集中地应用它们)来提高分布式设置中的通信效率。 [44]《S. U. Stich, “Local SGD converges fast and communicates little,” in Proc. Int. Conf. Learning Representations, 2019.》。这使得计算量与通信量相比更加灵活。
对于凸目标,分布式局部更新原始方法已经成为解决此类问题的一种流行方法[43]《V. Smith, S. Forte, C. Ma, M. Ta kac, M. I. Jordan, and M. Jaggi, “CoCoA: A general framework for communication-efficient distributed optimization,” J. Mach. Learning Res., vol. 18, no. 1, pp. 8590–8638, 2018》;一些分布式局部更新原始方法对非凸目标也可有额外的好处
最常用的优化方法是联邦平均(FedAvg)算法,已经证明FedAvg在实际中可以很好地工作,特别是对于非凸问题,但是它没有收敛保证,并且在数据异构情况下会在实际设置中发散[25]《T. Li, A. K. Sahu, M. Sanjabi, M. Zaheer, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” in Proc. Conf. Machine Learning and Systems, 2020.》
压缩方案
尽管本地更新方法可以减少通信回合的总数,但是模型压缩方案(例如稀疏化和量化)可以显著减少每次回合传递的消息的大小。全面回顾[47]《 H. Wa ng, S. Sievert, S. Liu, Z. Charles, D. Papailiopoulos, and S. Wright, “ATOMO: Communication-efficient learning via atomic sparsification,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 1–12.》
[18] L. He, A. Bian, and M. Jaggi, “Cola: Decentralized linear learning,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 4541–4551.
HE和SMC全面回顾[7]《R. Bost, R. A. Popa, S. Tu, and S. Goldwasser, “Machine learning classification over encrypted data,” in Proc. Network and Distributed System Security Symp., 2015. doi: 10.14722/ndss.2015.23241》
DP可以与模型压缩技术结合使用以减少通信同时获得隐私好处[1]《N. Agarwal, A. T. Suresh, F. X. X. Yu, S. Kumar, and B. McMahan, “cpSGD: Communication-efficient and differentially-private distributed SGD,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 7564–7575》
sample-specific privacy[24]《J. Li, M. Khodak, S. Caldas, and A. Talwalkar, “Differentially private meta-learning,” in Proc. Int. Conf. Learning Representations, 2020》
[5]《K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konecnyet al., “Towards federated learning at scale: System design,” in Proc. Conf. Machine Learning and Systems, 2019.》讨论了生产联邦学习系统中存在的一些与系统相关的实用问题
Irish budget airline Ryanair announced plans to significantly increase its route network from Frankfurt Airport, marking a direct challenge to Lufthansa, Germany's leading carrier. ...
[详细]











 京公网安备 11010802041100号
京公网安备 11010802041100号