由于配套的监控系统还不完善,自己写了一个简易版kafka消息消费tps监控页面。
下载安装
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.6.2.x86_64.rpm
sudo yum localinstall influxdb-1.6.2.x86_64.rpm
vi /etc/influxdb/influxdb.conf
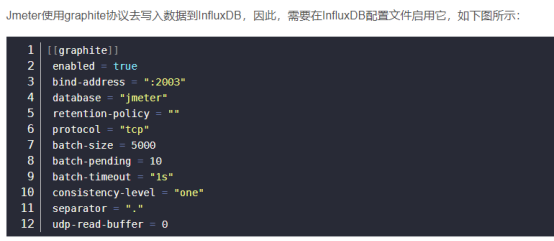
enabled = true
database = "jmeter"
retention-policy = ""
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
batch-size = 5000
batch-pending = 10
batch-timeout = "1s"
udp-read-buffer = 0
separator = "."
influxd -config /etc/influxdb/influxdb.conf
显示所有数据库:show databases
新增数据库:create database shhnwangjian
创建管理员权限的用户:CREATE USER "admin" WITH PASSWORD 'admin' WITH ALL PRIVILEGES
删除数据库:drop database shhnwangjian
使用指定数据库:use shhnwangjian
显示所有表:SHOW MEASUREMENTS
显示一个measurement中所有tag key:show tag keys from disk_free
查看一个measurement中所有的field key:show field keys
新增数据:insert disk_free,hostname=server01 value=442221834240i 1435362189575692182
删除表:drop measurement disk_free
插入数据:insert disk_free,hostname=server01 value=100 1613791502000000000
顺序为:表名(不存在则直接新建)+tag的key和value,field的key和value。注意中间的空格。
Api接口插入数据:
curl -i -XPOST 'http://IP:PORT/write?db=jmeter' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
端口说明:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.2.0-1.x86_64.rpm sudo yum localinstall grafana-4.2.0-1.x86_64.rpm
service grafana-server start

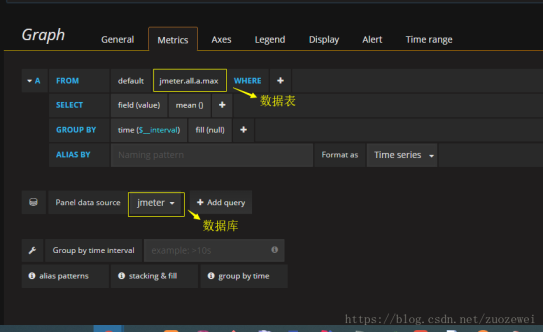

SQL:SELECT mean("value") FROM "tps" WHERE $timeFilter GROUP BY time(1s), "host" fill(null)
$__interval:group time(interval)会对查询结果按照interval进行聚合,例如:time(5m),interval=5m, 则会将数据每隔5m进行聚合
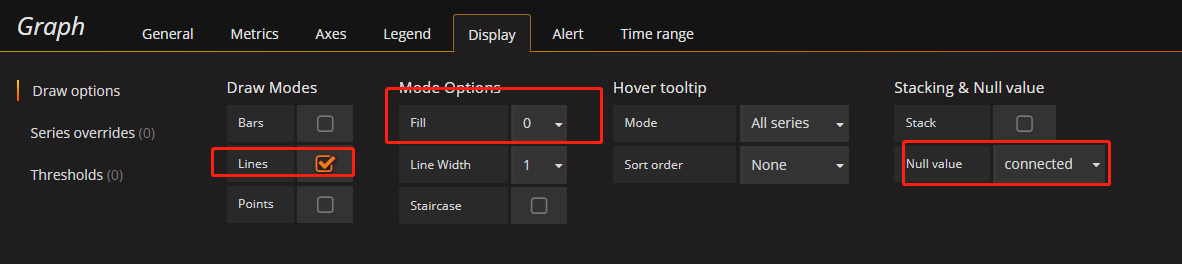
通过Stack来控制是否累积
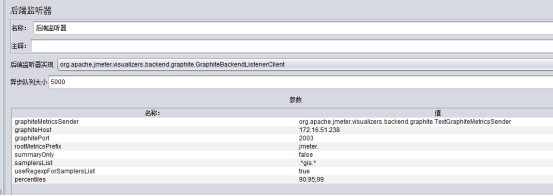
通过javasample将消费监控集成到jmeter中,在启动生产者之前先启动消费监控线程组
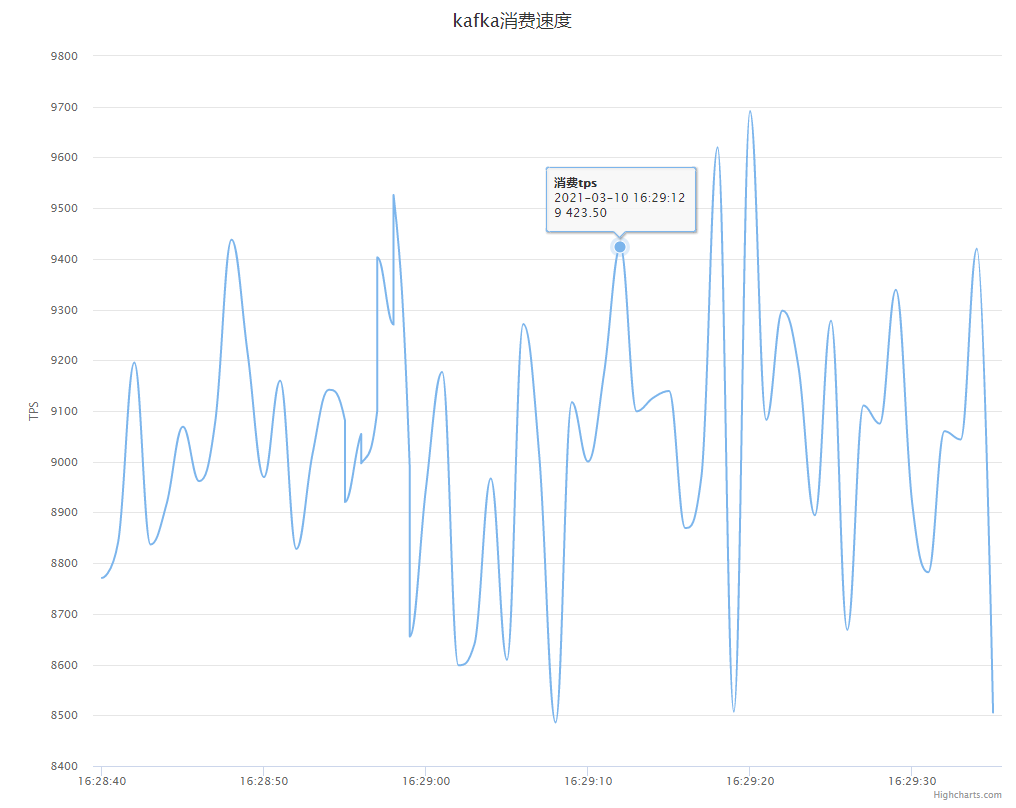
import lombok.SneakyThrows; partitiOnInfos= consumer.partitionsFor(TOPIC); 另外自己也通过Highcharts写了一个简单的监控页面: <html>
import org.apache.jmeter.config.Arguments;
import org.apache.jmeter.protocol.java.sampler.AbstractJavaSamplerClient;
import org.apache.jmeter.protocol.java.sampler.JavaSamplerContext;
import org.apache.jmeter.samplers.SampleResult;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author: weisy
* @date: 2021/02/22
* @description:
*/
public class KafkaMonitor extends AbstractJavaSamplerClient {
private String kafkaIp;
private String topic;
private String consumer;
private String influxdbIp;
private String influxdbName;
private String measurement;
private int sampleInterval;
private int loopTime;
@Override
public Arguments getDefaultParameters() {
Arguments params = new Arguments();
params.addArgument("kafkaIp", "IP:PORT","kafka集群信息");
params.addArgument("topic", "topic_name","topic");
params.addArgument("consumer", group_name","消费者");
params.addArgument("influxdbIp", "IP:PORT","数据库ip");
params.addArgument("influxdbName", "jmeter","数据库名");
params.addArgument("measurement", "tps","表名");
params.addArgument("sampleInterval", "0.5","采样间隔时间/s");
params.addArgument("loopTime", "60","持续时间/s");
return params;
}
/**
* 每个线程测试前执行一次,做一些初始化工作
* 获取输入的参数,赋值给变量,参数也可以在下面的runTest方法中获取,这里是为了展示该方法的作用
* @param arg0
*/
@Override
public void setupTest(JavaSamplerContext arg0) {
kafkaIp = arg0.getParameter("kafkaIp");
topic = arg0.getParameter("topic");
consumer = arg0.getParameter("consumer");
influxdbIp = arg0.getParameter("influxdbIp");
influxdbName = arg0.getParameter("influxdbName");
measurement = arg0.getParameter("measurement");
try {
this.sampleInterval = Integer.valueOf(arg0.getParameter("sampleInterval")).intValue()*1000;
} catch (NumberFormatException e) {
e.printStackTrace();
}
try {
this.loopTime = Integer.valueOf(arg0.getParameter("loopTime")).intValue();
} catch (NumberFormatException e) {
e.printStackTrace();
}
}
/**
* 真正执行逻辑的方法
* @param arg0
* @return
*/
@SneakyThrows
@Override
public SampleResult runTest(JavaSamplerContext arg0) {
SampleResult sr = new SampleResult();
Date data = new Date();
long currentTime =new Date().getTime();
long endTime=currentTime+loopTime * 1000L;
int tol = 0;
int num = 0;
System.out.println("开始时间"+currentTime);
System.out.println("结束时间"+endTime);
while (currentTime < endTime) {
currentTime=new Date().getTime();
int offsets = 0;
offsets = getPartitionsForTopic(topic,kafkaIp,consumer);
System.out.println("消费时间:"+currentTime+" 消费量:"+ (offsets-num));
int tps = offsets-num;
if (num != 0 && offsets - num != 0){
tol = offsets - num + tol;
String querybody = measurement+",host=server01,region=us-west value="+tps;
String url = "http://"+influxdbIp+"/write?db="+influxdbName;
HttpClient4.writeInfluxdb(url,querybody,null);
}
num = offsets;
Thread.sleep(sampleInterval);
}
return sr;
}
/**
* 测试结束后调用
* @param arg0
*/
@Override
public void teardownTest(JavaSamplerContext arg0) {
}
private static Consumer
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, Group);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
final Consumer
return consumer;
}
public static int getPartitionsForTopic(String TOPIC,String BOOTSTRAP_SERVERS,String Group) {
final Consumer
AtomicInteger sonsumernum = new AtomicInteger();
Collection
System.out.println("Get the partition info as below:");
List
partitionInfos.forEach(str -> {
tp.add(new TopicPartition(TOPIC,str.partition()));
consumer.assign(tp);
consumer.seekToEnd(tp);
sonsumernum.set(sonsumernum.get() + (int) consumer.committed(new TopicPartition(TOPIC, str.partition())).offset()); //获取每个分区提交的偏移量总和
});
return sonsumernum.get();
}
/**
* main方法测试程序是否可用,打包时 注释掉
* @param args
*/
public static void main(String[] args) {
Arguments params = new Arguments();
//设置参数
params.addArgument("kafkaIp", "IP:PORT","kafka集群信息");
params.addArgument("topic", "topic_name","topic");
params.addArgument("consumer", "group_name","消费者");
params.addArgument("influxdbIp", "IP:PORT","数据库ip");
params.addArgument("influxdbName", "jmeter","数据库名");
params.addArgument("measurement", "tps","表名");
params.addArgument("sampleInterval", "0.5","采样间隔时间");
params.addArgument("loopTime", "60","持续时间/s");
JavaSamplerContext arg0 = new JavaSamplerContext(params);
t3.jmeter.javasample.kafka.KafkaMonitor test = new KafkaMonitor();
test.setupTest(arg0);
test.runTest(arg0);
test.teardownTest(arg0);
}
}最终效果

<head>
<meta charset="UTF-8" />
<title>Highchartstitle>
<script src="http://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js">script>
<script src="http://code.highcharts.com/highcharts.js">script>head>
<body>
<div id="container" style="width: 1000px; height: 800px; margin: 0 auto">div>
<script language="Javascript">
$(document).ready(function() {
var chart = {
type: 'spline',
animation: Highcharts.svg, // don't animate in IE
marginRight: 10,
events: {
load: function () {
// set up the updating of the chart each second
var series = this.series[0];
setInterval(function () {
var res = showAdress(5);
if(res.series){
var x = res.series[0].values[0][0];
var y = res.series[0].values[0][1];
series.addPoint([x, y], true, true);
}
// series.addPoint([x, y], true, true);
}, 1000);
}
}
};
var title = {
text: 'kafka消费速度'
};
var xAxis = {
type: 'datetime',
tickPixelInterval: 150
};
var yAxis = {
title: {
text: 'TPS'
},
plotLines: [{
value: 0,
width: 1,
color: '#808080'
}]
};
var tooltip = {
//设置x和y轴显示格式
formatter: function () {
return '' + this.series.name + '
' +
Highcharts.dateFormat('%Y-%m-%d %H:%M:%S', this.x) + '
' +
Highcharts.numberFormat(this.y, 2);
}
};
var plotOptions = {
area: {
pointStart: 1940,
marker: {
enabled: false,
symbol: 'circle',
radius: 2,
states: {
hover: {
enabled: true
}
}
}
}
};
var legend = {
enabled: false
};
var exporting = {
enabled: false
};
var series= [{
name: '消费tps',
data: (function () {
// generate an array of random data
var data = [],time = (new Date()).getTime(),i;
var res = showAdress(60);
if(res.series){
var values = res.series[0].values;
//遍历数组并打印当前值和下标
values.forEach(function (element, index, array) {
console.log(element, index)
data.push({
x: element[0],
y: element[1]
});
})
}
console.log(res);
return data;
}())
}];
function showAdress(time)
{
var flag = false;//全局变量,以便下面做判断
var datas;
$.ajax
({
url: "http://IP:PORT/query",
dataType: "json",
type: "get",
async: false,
data: {
u:"admin",
p:"admin",
db:"jmeter",
q:`SELECT mean("value") FROM "tps" WHERE time > now() - ${time}s GROUP BY time(1s) fill(null)`,
// q:'SELECT mean("value") FROM "tps" WHERE time > 1614757792613ms and time <1614757896397ms GROUP BY time(1s) fill(null)',
epoch:"ms"
},
success:function(res){
if(null != res){
// datas = res.results[0].series[0].values;
datas = res.results[0];
flag = true;
}
},
error:function(){
alert('failed!');
},
});
if(flag){
return datas;
}
}
var json = {};
json.chart = chart;
json.title = title;
json.tooltip = tooltip;
json.xAxis = xAxis;
json.yAxis = yAxis;
json.legend = legend;
json.exporting = exporting;
json.series = series;
json.plotOptions = plotOptions;
Highcharts.setOptions({
global: {
useUTC: false
}
});
$('#container').highcharts(json);
});
script>
body>
html>






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有