作者:老屋时光_503 | 来源:互联网 | 2023-09-14 18:16
论文标题:MANIPULATING SGD WITH DATA ORDERING ATTACKS
论文单位:University of Cambridge
论文作者:Ilia Shumailov,Zakhar Shumaylov,Dmitry Kazhdan
收录会议:预印版
开源代码:未开源
使用数据排序攻击来操纵SGD(攻击)
简单总结 一种非常新颖的投毒和后门攻击
抓住了SGD的一个漏洞,不需要对数据和模型进行变动,仅仅是更改了输入数据的顺序即可攻击成功。 使用数据集:Cifar10,Cifar100;使用模型:ResNet-18、VGG16、LeNET5 假设了两种场景,黑盒和白盒,黑盒攻击使用一个代理模型去替代目标模型。 提出了三种手段攻击,Reordering, Reshufflfling and Replacing,Reordering 更换一个epoch里的batch的顺序,Reshufflfling 更换一个epoch里的数据点的顺序,Replacing 则是可以在一个epoch里进行过采样或欠采样。Reordering和Reshufflfling要使用代理模型(黑盒)或目标模型(白盒)输出的loss按顺序排序后,按照四种方法进行抽样。Replacing则是对一个epoch里的所有组合的情况进行随机抽样,找到尽可能符合目标分布的排序。 integrity attack 攻击者可以降低模型的准确性或者在特定的触发点出现时,任意地控制它的预测availability attack 攻击者可以增加模型训练的时间或重置学习进度提出了三种不同方向的攻击。 为了中断整个学习过程,使得精度完全下降,每个epoch都会使用Reordering和Reshufflfling(属于integrity attack); 为了增加模型收敛时间,需要更多的epoch训练才能达到原来的精度,只在一个epoch使用Reordering和Reshufflfling(属于availability attack); batch-order poisoning (BOP) and batch-order backdooring (BOB) :达到攻击者预期的结果,使用Replacing对batch进行抽样,使其得到的更新模型的参数约等价于使用扰动后的数据所更新模型的参数。(属于integrity attack)。 第一个疑问:论文中的Figure6,这里有个细节,表现最好的攻击,是通过类别去进行排序的,将按类别排序的数据输入模型,对于模型的训练来说,显然是非常难以收敛的,那这样攻击效果肯定是很好的。在论文的前面也是根本没有介绍这种排序手段,感觉这应该是作者的一个特意的手法,用来给我们做对比的?可能得等作者开源代码才能知道细节,但其他的提到的排序方法的效果也还是比较不错的。
第二个疑问:本文说明integrity attack的一个特点是中断整个学习过程,使得精度完全下降,但在我下面的补充说明,这个特点应该是属于availability attack的,所以我认为这个地方论文存在问题,但对于论文的排序攻击有效性来说,无伤大雅。
补充 :integrity attack和availability attack是在2010年一篇综述《The security of machine learning》上介绍的,完整性攻击通过false negatives来进行危害,例如:攻击者利用对训练的控制,使垃圾邮件以假否定的形式溜过分类器;Availability attacks导致拒绝服务,通常通过false positives,例如:攻击者利用对训练实例的控制来干扰邮件系统的操作,例如阻止合法的电子邮件。
值得做的点(仅从本文出发) 这种攻击还是非常有趣的,抓住了SGD的一个漏洞,也算是抓住了数据集采样的一个漏洞,因为这么多batch,总有些batch的数据更新模型的效果会比较差。想要解决这个问题应该非常难,SGD的出现正是因为BGD的计算量太大,当然如果计算资源解决了,本文的攻击也毫无意义了。 本文的三个方向的攻击,可以考虑在联邦学习场景下使用,因为没有人会恶意去攻击自己训练的模型,但在多方协同训练模型时,总有可能会出现那么一些恶意攻击者,因此可以在联邦学习场景下,去防御这种攻击 。这里主要要对每个batch的loss去进行分析,要重点分析随机抽样的batch的loss和精心排序后的batch的loss的区别。 abstract 机器学习模型容易受到各种各样的攻击,人们往往更改底层的数据分布去进行毒害模型或引入后门。
本文提出了一种新颖的攻击,不需要更改数据的分布和模型结构,仅仅更改了输入数据的顺序 ,并且是在不了解模型或数据集的情况下,所以这里提出的攻击不是特定于模型或数据集,而是针对现代学习过程的随机性。
affect model integrity .作者对本文的攻击进行了广泛的评估,敌手可以破坏模型训练,甚至引入后门 。(具体来说,这个攻击可以阻止模型学习,或者毒害它学习攻击者指定的行为)
affect model availability .只需一个epoch的对抗顺序就足以减缓模型学习,甚至重置所有的学习进度 。这样的攻击有一个长期的影响,在攻击发生之后的数百个epoch内降低模型性能。
该攻击方法提醒我们,随机梯度下降(stochastic gradient descent)依赖于数据是随机抽样的假设。如果这种随机性被破坏了,那么一切都很难说了。
1.introduction 背景 在随机梯度下降(SGD)的情况下,它假设从训练数据集中进行均匀随机采样,但在实践中这种随机性很少被测试或执行。因此,作者聚焦于对抗性数据采样 。
先前的攻击 恶意的参与者可以毒害数据并引入后门,迫使ML模型的表现在触发器存在时有所不同。虽然这类攻击已被证明构成了真正的威胁,但它们需要攻击者训练集中引入扰动或触发器用于训练。
介绍 在训练过程中,简单地改变某一些batch或数据的顺序,即可影响模型的正常训练。更准确地说,在本文中,作者证明了无需添加或修改任何数据的integrity and availability attack 是可行的。
作者提出了Batch Reordering, Reshufflfling and Replacing 三种不同类型的攻击,并将它们命名为BRRR attack 。
Reordering:改变提供给模型训练的batch顺序; Reshufflfling:改变单个数据点的顺序; Replacing:将batch里的数据点替换为数据集中的其他数据点进行提升特定的数据偏差。 此外,还介绍了 Batch-Order Poison (BOP) 和 Batch-Order Backdoor (BOB)
再次强调了,其攻击方法与模型和数据集知识无关,主要集中于梯度下降的随机性,在训练过程中去干扰单个batch的近似真实分布。
贡献 作者提出了一种针对ML模型的新型攻击,该攻击针对训练中使用的数据批处理过程,影响其integrity和availability 。并且提出了一个理论分析,解释如何和为什么这些攻击有效,表明它们针对的是随机学习的基本假设,因此是与模型和数据集无关。 作者展示了数据顺序可以毒害模型和引入后门 ,即使是在黑盒设置中。对于一个白盒设置,作者发现攻击者可以引入后门,就像他们使用干扰数据一样好。而使用扰动数据的基线得到99%的触发精度,白盒BOB攻击者得到91%±13和黑盒BOB攻击者达到68%±19。 2.Methodology 2.1Motivation 场景 :我们探讨获得了数据采样过程控制权的攻击者是否会影响模型的完整性和可用性。这样的攻击很难检测到,因为它不会改变机器学习工作流中的任何东西;数据集仍然是是一样的,没有任何扰动。
以上两种攻击都没有起到任何作用对基础数据的预先假设。
2.2Threat model
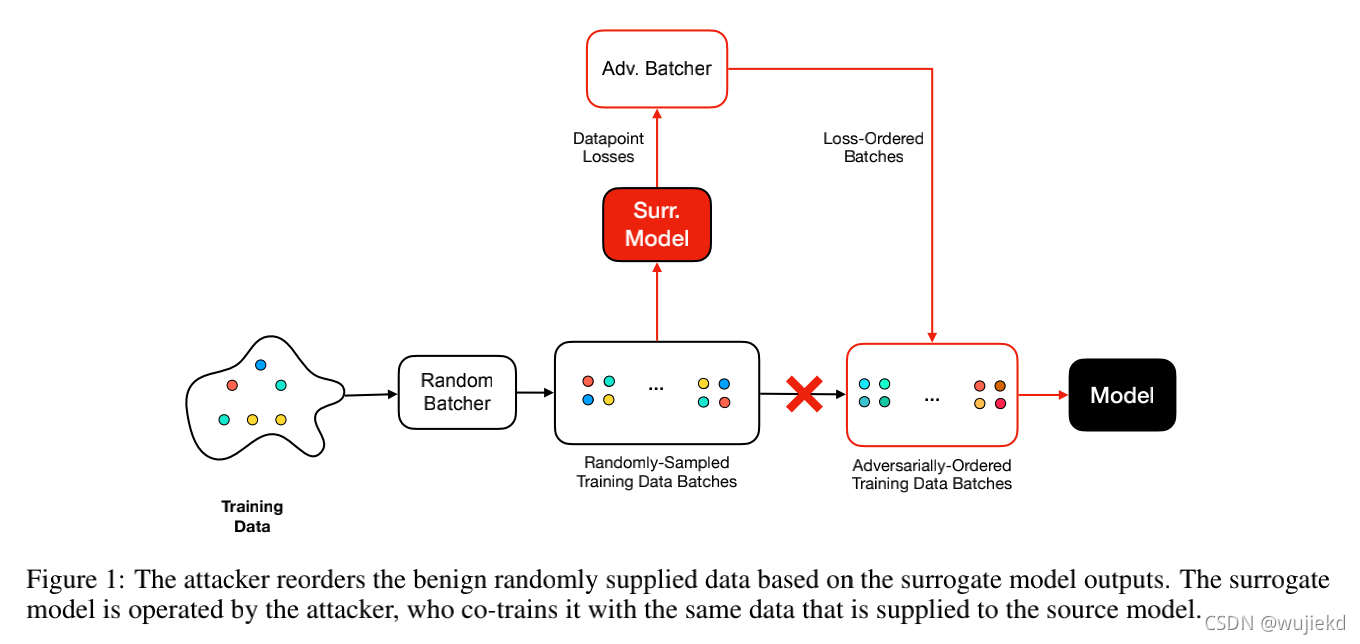
我们假设目前文献中描述的最强威胁模型 之一。特别是黑盒攻击者假设没有对模型的访问权,也没有训练数据的先验知识。这次攻击的重点是ML流程的批处理部分如图1所示。
这个威胁模型的具体过程就是,使用一个代理模型对随机采样的batch数据进行训练,得到一个生成对抗batch的数据,用于攻击目标模型,即放在目标模型训练。
这里可以看出来黑盒攻击和白盒攻击的区别即是否使用一个代理模型 。
2.3Primer on stochastic learning and batching SGD、Adam的一些简单介绍(跳过)
一个epoch需要执行N次SGD去更新参数,也正如上图所示,在这种情况下,二阶修正(通过泰勒展开去逼近)依赖的是提供的batch的顺序(如下图所示)。
因此,找到一个更新序列,使一阶导数和二阶导数与真正的梯度步长不一致,就可使得攻击成功,简而言之,就是使式(7)最大化,这样更新的梯度方向就最不等价于一个batch所更新的效果。但作者认为实践中这样做是昂贵的,因此,在攻击中我们直接利用损失的大小 。直观地说,大的预测误差对应大的损失梯度规范,而正确的预测产生接近零的梯度。
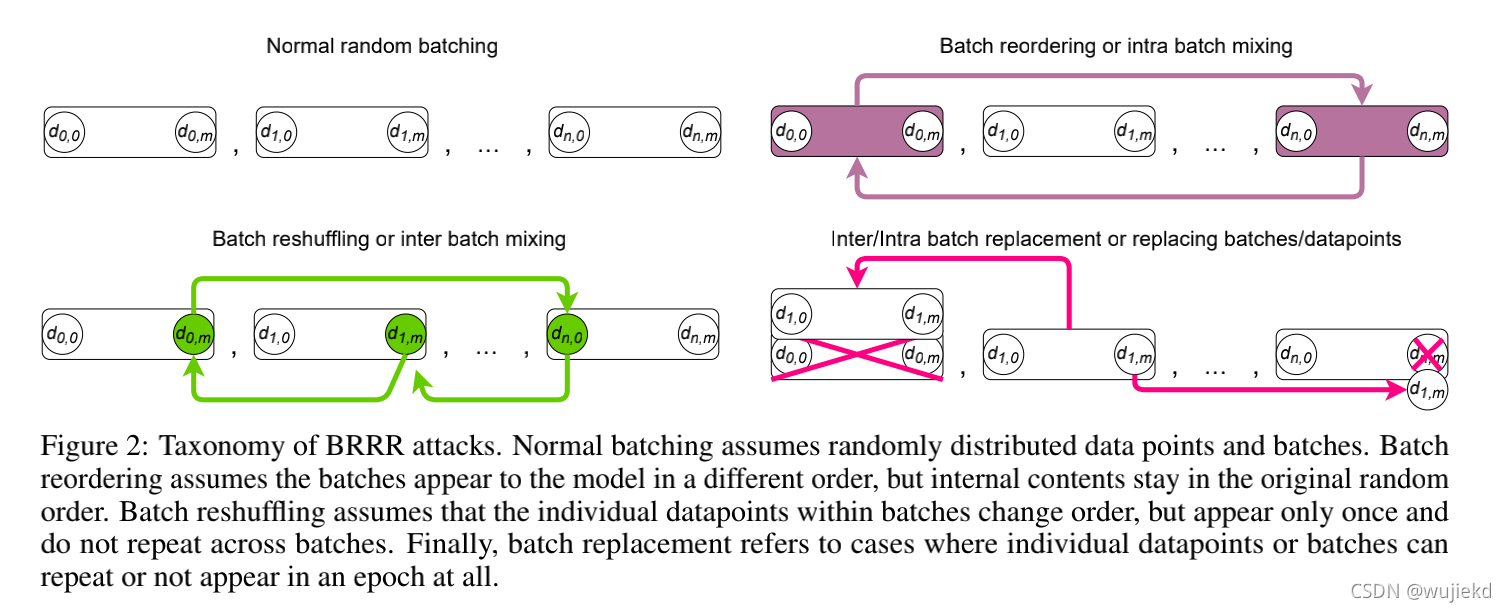
2.4Taxonomy of batching attacks 批次攻击的分类,分三类 ,如下图所示
Batch reshufflfling or inter-batch mixing :攻击者专注于改变单个数据点在给定epoch中出现在batch中的顺序。
Batch reordering or intra-batch mixing :攻击者专注于改变被提供给模型提前随机抽样好的batch的顺序
Data point or batch replacement :攻击者的关注点要么是替换批内的数据点,要么是替换整个批。在这种情况下,攻击者既可以对数据点进行过采样,也可以对数据点进行过采样。
总的来说,不是更换batch优化的顺序,就是破坏原来的batch内的数据点
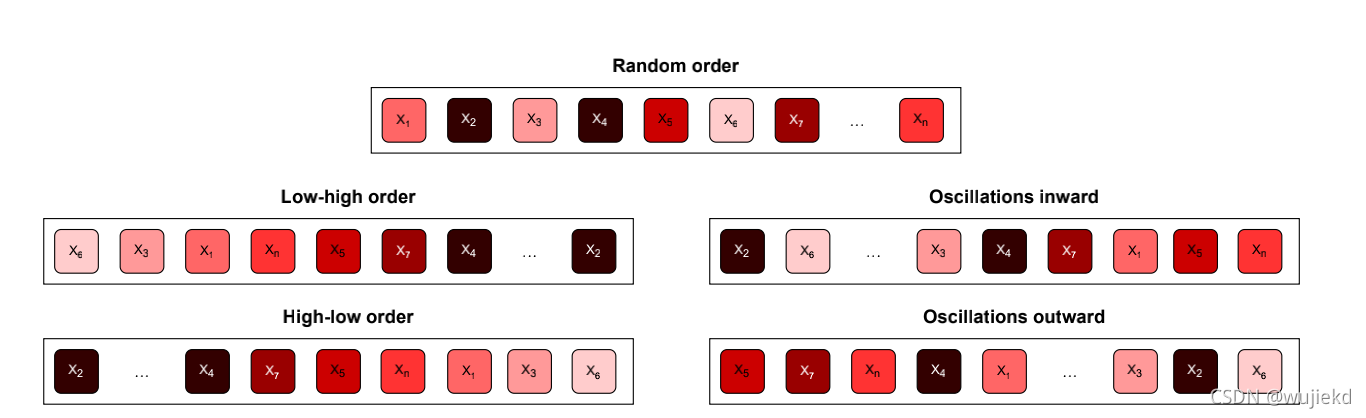
考虑了四种重新排序策略 ,如下图所示
先排序好,再按照策略选择
通过损失由低到高的排序。 通过损失由高到低的排序。 从外向里从两边依次选取元素。 从里向外从两边依次选取元素。 2.5Batch-order poison and backdoor 介绍了batch-order poisoning (BOP) and batch-order backdooring (BOB),这是首个在训练中不依赖添加对抗数据点和干扰的中毒和后门攻击的策略,仅仅采用了batch replacement attacks。
先介绍了一下常规的后门攻击的一个更新参数的机制,X^\hat{X} X ^
然后想说明仅通过观测△θk\triangle θ_k △ θ k XkX_k X k ∇θL^(Xi,θk)≈∇θL^(Xj,θk)\nabla_θ \hat {L}(X_i, θ_k)≈\nabla_θ\hat {L}(X_j, θ_k) ∇ θ L ^ ( X i , θ k ) ≈ ∇ θ L ^ ( X j , θ k ) Xj≠XiXj \neq Xi X j = X i
最后说明,可以通过batch replacement在干净的数据集中重构一个数据集XiXi X i ∇θL^(Xi,θk)≈∇θL^(X^k,θk)\nabla_θ \hat {L}(X_i, θ_k)≈\nabla_θ\hat {L}(\hat{X}_k, θ_k) ∇ θ L ^ ( X i , θ k ) ≈ ∇ θ L ^ ( X ^ k , θ k )
通过对一个batch随机采样重构,有∣X∣B|X|^B ∣ X ∣ B BB B ∣X∣|X| ∣ X ∣
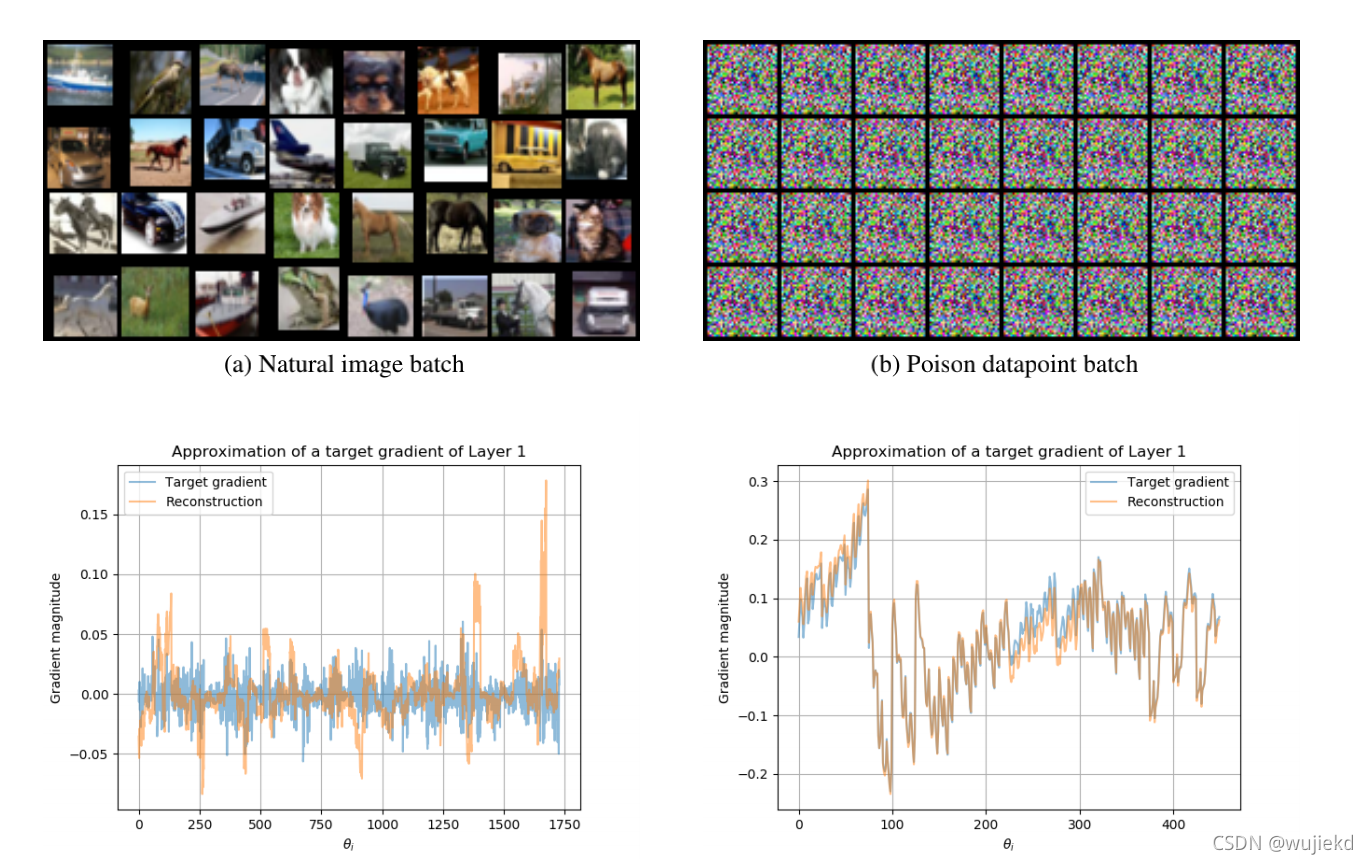
作者也说明了更多的随机方法可以找到更好的候选者,但随机采样工作已经很不错了,权衡了速度和性能。 效果如下图所示,左上角是重构后的batch(作者的方法),右上角是投毒后的数据集(逼近的目标),下方两张图为不同模型(ResNet-18和LeNet5)下的两类数据训练得到的第一层的梯度图,可以看到非常接近。两类数据训练得到的ResNet-18的精度都达到了80%,并且使得中毒数据分类为指定目标。
3.Evaluation 3.1Experimental setup 数据集:CIFAR-10 and CIFAR-100 datasets
目标模型:VGG16、ResNet-18 and ResNet-50
代理模型: ResNet-18、LeNet-5 and MobileNet
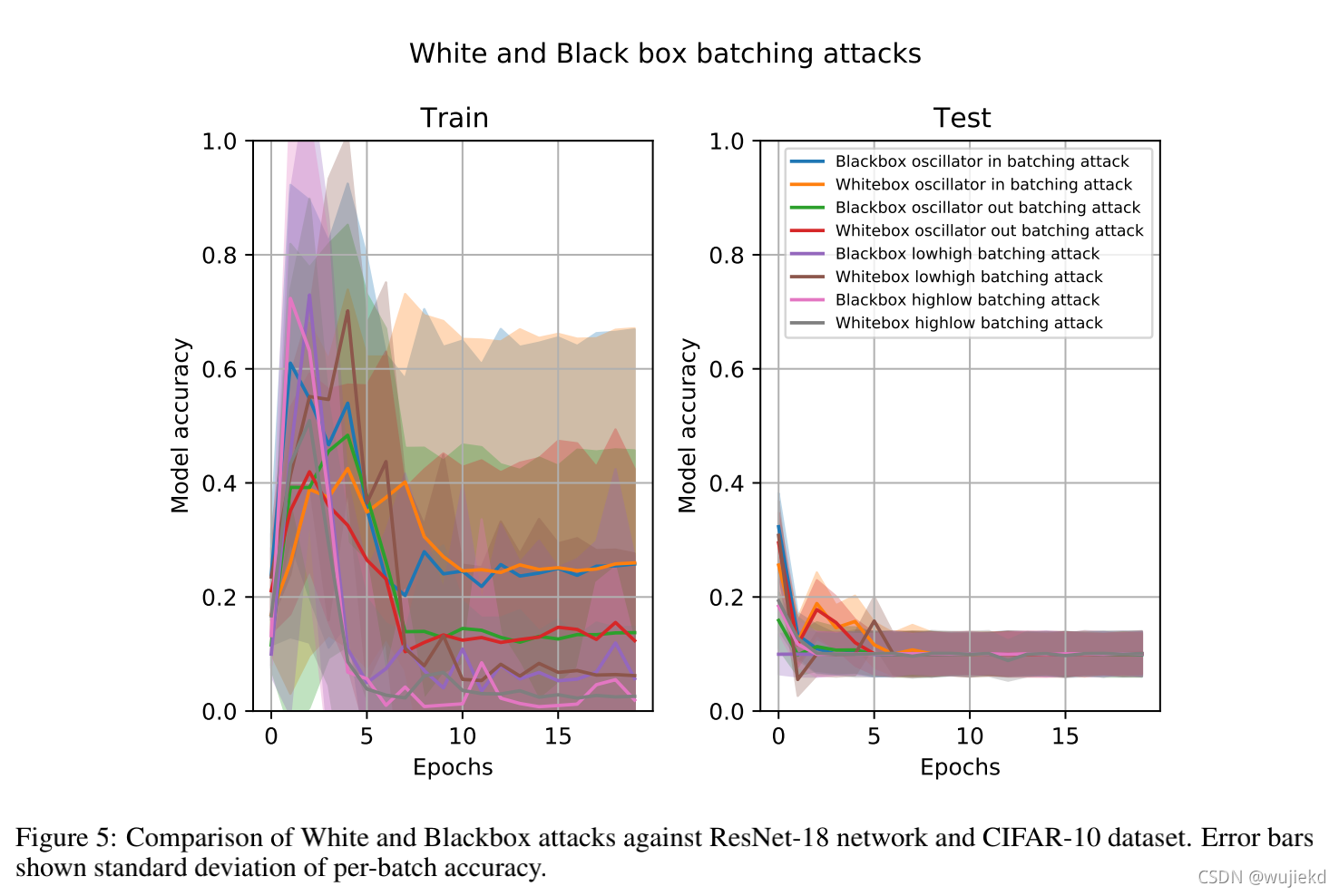
3.2Integrity attacks in white and blackbox setups 评估了在白盒和黑盒设置下的 batch reordering attacks 的性能,并用了四种reorder方法进行评估,说明在黑盒和白盒场景下都适用。
注:白盒直接使用目标模型输出的loss,黑盒使用了代理模型计算loss。
3.3Integrity attacks with reshufflfling and reordering of natural data 比较了baseline 、 batch reordering attacks 、 batch reshuffle attacks 三种训练模型的精度,最终训练得到的模型精度依次下降。
总结:
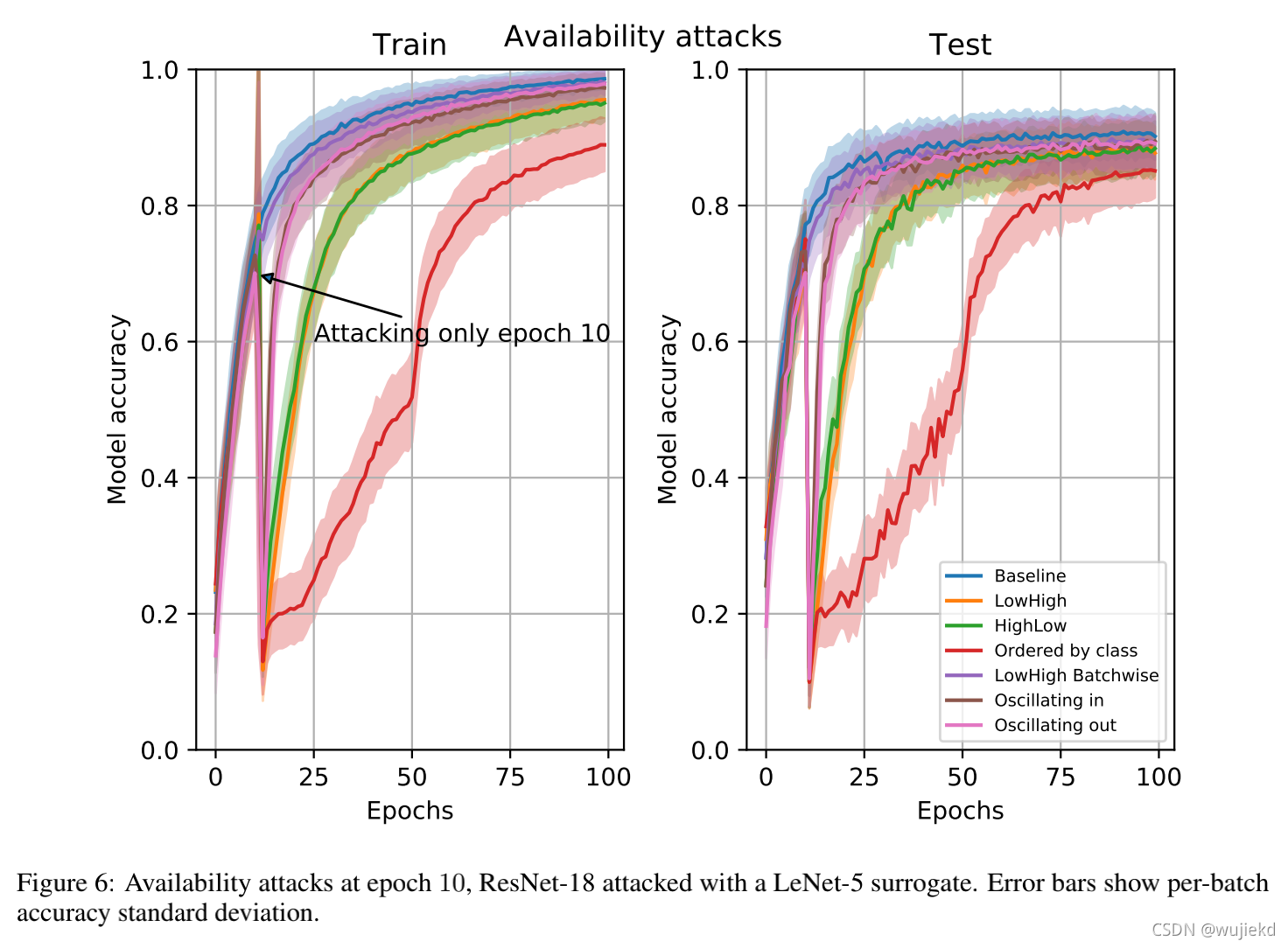
攻击者可以通过改变单个数据项和batch的顺序来影响模型训练的完整性。 攻击者可以降低模型性能,并完全重置其性能。 3.4Availability attacks 上一节讨论的完整性攻击是为了中断整个学习过程,使得精度完全下降。
这一节介绍的可用性攻击是为了减缓训练,使得达到与baseline一样的精度所用的epoch大大增加。
这里的场景为黑盒,同时使用了batch reordering 和 batch reshuffle仅仅在第10个epoch进行攻击。
总结:
攻击者可以仅在一个epoch的训练时期通过改变数据的顺序来干扰模型训练。 仅仅一个epoch的攻击足以让该模型需要多训练90个epoch才能得到原来的精度。 有个疑问 :论文中的Figure6,这里有个细节,表现最好的攻击,是通过类别去进行排序的,按类别排序的数据输入模型对于模型的训练来说,显然是非常难以收敛的,并且在论文的前面也是根本没有介绍这种排序手段,感觉这应该是作者的一个特意的手法,用来给我们做对比的?可能得等作者开源代码才能知道细节,但其他的提到的排序方法的效果也还是比较不错的。
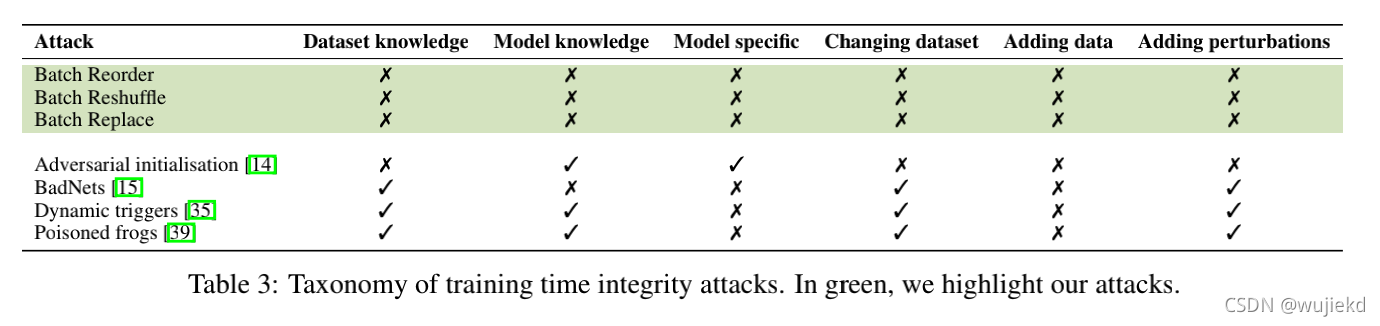
3.5BOP and BOB with batch replacement BOB和其它攻击的攻击者所掌握信息比较
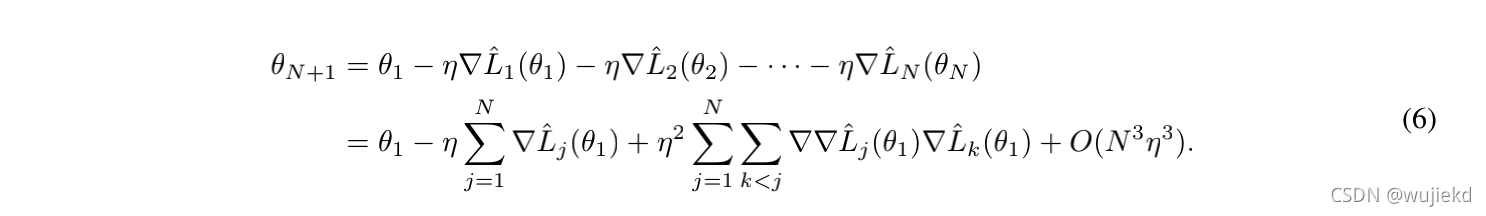
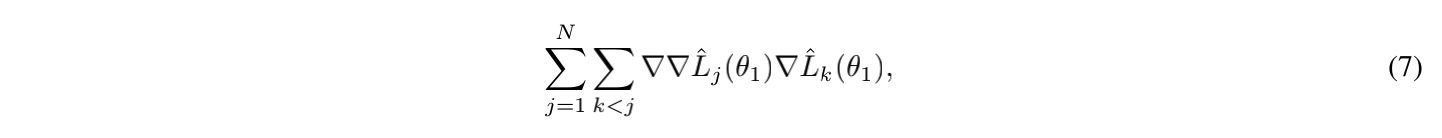
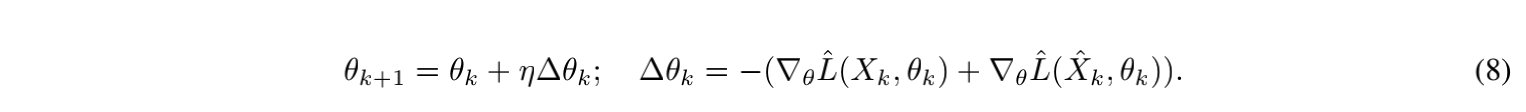
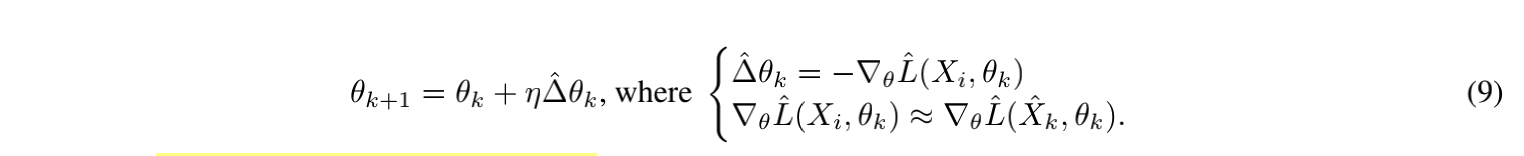
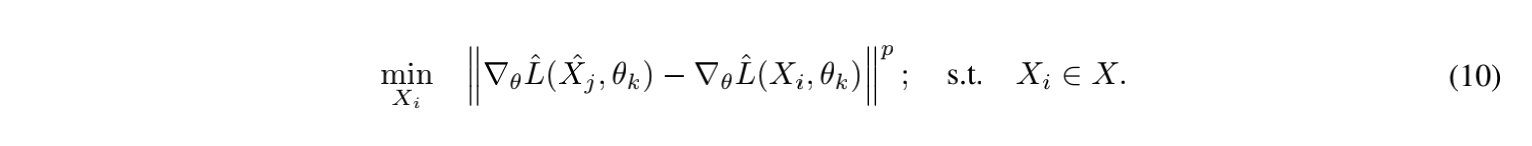






 京公网安备 11010802041100号
京公网安备 11010802041100号