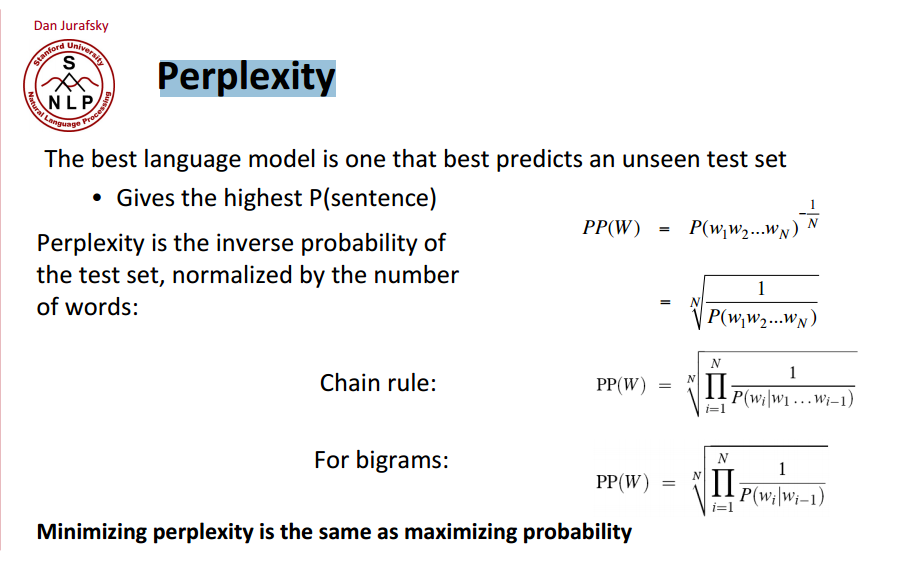
假设W是一句话,w1,w2,⋯,wn是构成这句话的单词,利用链式法则求W的概率公式如下: 现在的目标变成估计P(wi|w1w2⋯wi−1)了,同样,如果直接采取频率的估计方法,可能的句子太多,将永远不会有足够的数据来估计这个条件概率密度。引入Markov Assumption:句子当前词出现的概率仅与前N−1个词有关,那么该模型就成为”N元模型” 最简单的模型即Unigram model,每个词出现的概率与上下文无关, Bigram model:认为每个单词的出现只与它的前一个单词相关, 我们也可以使用4元模型,5元模型,N越大,语言模型的准确率越大,但是每增加一元,带来的是计算量的指数增长。事实上,句子中的long distance dependencies(长程依赖)是存在的,如:The computer which I had just put into the machine room on the fifth floor crashed.最后一个单词crashed实际上是与句子中靠前的computer相关,就算是使用5元模型也不可能把单词之前的相关性展示出来。

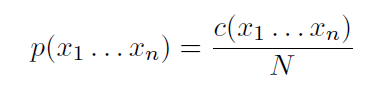
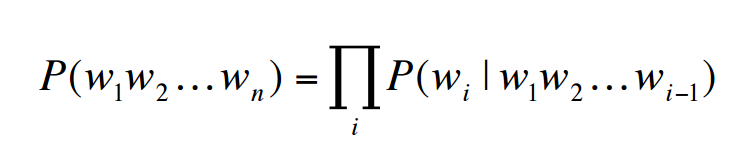
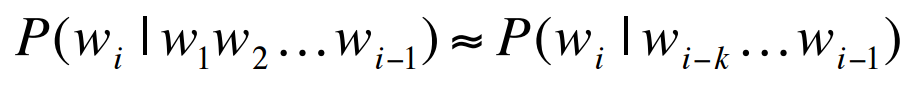
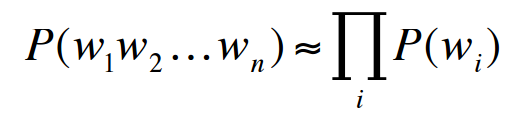
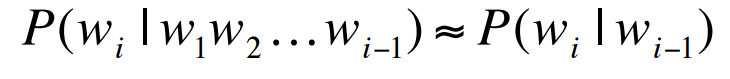
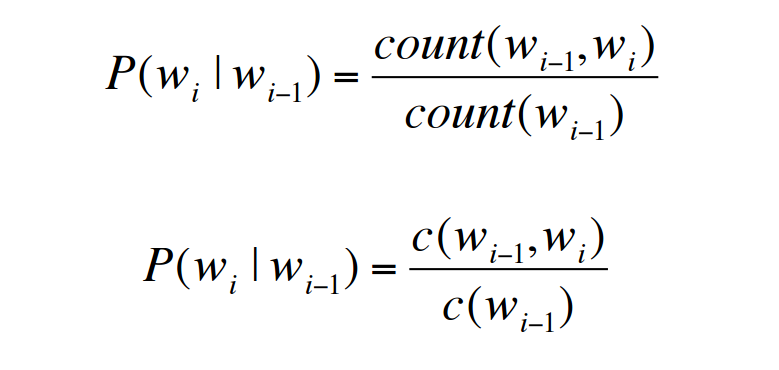

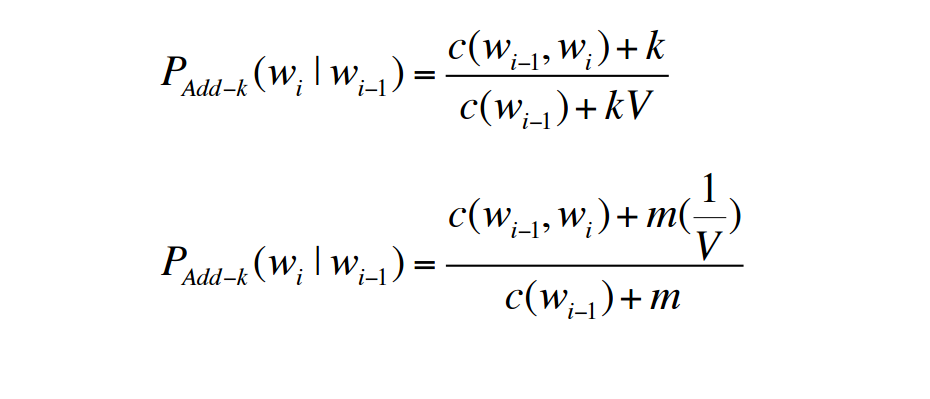





 京公网安备 11010802041100号
京公网安备 11010802041100号