接上一篇,今天我们继续聊聊HDFS
的读写流程、nn
与2nn
的关系和datanode
的工作机制。
客户端如何把数据写到hdfs
集群中的?看这个图:

在写入之前,首先要创建一个客户端,注意这里必须是一个分布式文件系统。
1、先向nn请求上传文件/**/**/ss.avi
2、nn检查目录树是否可以创建文件,最重要的是检查所属组所有者的权限和检查目录结构。检查后响应可以上传文件
3、客户端请求上传第一个block(0-128M),请求返回dn。因为有多个节点,客户端不知道具体传到哪里
4、此时nn收到请求后进行存储节点选择,此时要考虑两点,一个是节点距离问题,还有机架感知问题和负载均衡问题。节点距离即为图中的描述,4.123在源码中也有体现。
5、客户端开始创建数据流开始写数据,并请求建立block传输通道。
6、返回应答
7、传输数据以packet为单位(64k),一个packet由多个chunk512byte+chunksum4byte(校验作用)组成。同步骤5一样,传输的时候一份在磁盘中写,另一份在内存中直接传递给下一个节点。其实这里还有一个ack队列用于存数据并等待应答,类似缓存的作用,万一packet出现问题就从队列中取数据。
8、传输完毕,客户端close。
针对第四个步骤的节点距离计算问题,我们定义节点距离为两个节点到达最近共同祖先的距离总和,我理解就是这种方式会使传输速度更快。例如f
和g
的节点距离为3,h
和b
的节点距离为4。
针对第四个步骤的机架感知问题,官网的描述是这样:
第一个节点:on the local machine or a random datanode
第二个节点:on a node in different (remote) rack
第三个节点:on a different node in the same remote rack
我们顺变看下源码,BlockPlacementPolicyDefault
这个类中的chooseTargetInOrder()
方法:
// 第一个副本的选择 dn0
if (numOfResults == 0) {
writer = chooseLocalStorage(writer, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes, true)
.getDatanodeDescriptor();
if (--numOfReplicas == 0) {
return writer;
}
}
// 选择与第一个副本不在同一Rack下的第二个副本dn1
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor();
if (numOfResults <= 1) {
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
if (--numOfReplicas == 0) {
return writer;
}
}
// 第三个副本
if (numOfResults <= 2) {
final DatanodeDescriptor dn1 = results.get(1).getDatanodeDescriptor();
// 第一、二副本在同一Rack下时选第三个副本
if (clusterMap.isOnSameRack(dn0, dn1)) {
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else if (newBlock){ // 正常情况,第二副本的localRack下选第三副本
chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else { // 其它的以外
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
}
if (--numOfReplicas == 0) {
return writer;
}
}
// 如果副本数量还没到0,剩下的副本随机选择
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
return writer;
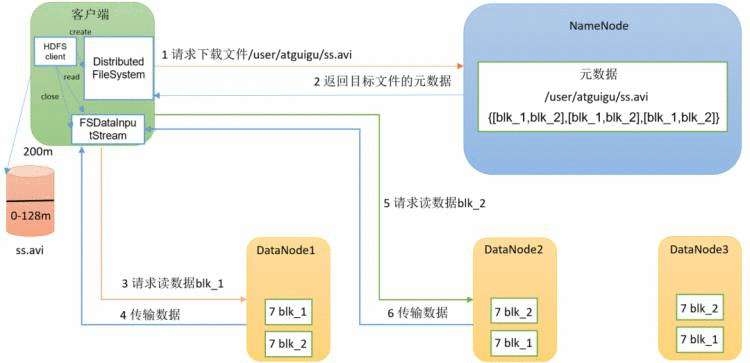
在读数据之前,首先要创建个分布式文件系统。
1、先向nn请求下载文件/**/**/ss.avi
2、nn检查client是否有权限下载。成功后返回目标文件的元数据
3、客户端创建一个input流开始请求数据,以最近节点为原则(然后随机)读数据blk_1
4、传输数据blk_1
5、倘若此时发生了负载不均衡的问题,就会请求dn2读数据数据blk_2,这里采用的是串行读的方式。
6、传输数据blk_2
7、传输完毕,客户端close。
NameNode
的元数据是怎么存储的并且存储在哪里呢?
如果只存放在磁盘中,磁盘读写速度慢,效率太低;如果存放在内存中,断电即失,集群也无法工作。所以能否同时利用磁盘和内存的优点?
假设我们在内存中存放元数据,在磁盘中用FsImage
备份元数据,同时引入Edits
文件(只追加)做记录,每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits
中。一旦NameNode
断电,可以通过FsImage
和Edits
的合并,合成元数据。
但是,如果长时间添加数据到Edits
中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage
和Edits
的合并,如果这个操作由NameNode
完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode
,专门用于它们的合并。

图中描述了两个阶段的内容:nn
和2nn
。
左侧的nn:
1、加载磁盘中的edits和fsimage到内存
2、元数据请求增删改
3、将操作日志记录在edits中
4、更新fsimage对内存进行增删改
右侧的2nn:
1、请求是否需要checkpoint,判断条件:定时时间到(1h)或edits中数据满了
2、请求同意,执行checkpoint
3、先生成新的edits_inprogress_002(新的edits),将edits_inprogress_001重命名edits_001
4、nn中的edits_001和fsimage拷贝到2nn
5、二者加载到内存并合并
6、生成新的fsimage.ckpt
7、再将fsimage.ckpt拷贝到nn
8、在nn中将fsimage.ckpt重命名为fsimage
所以说nn
和2nn
的不同之处在与nn
多了一个edits_inprogress_002
用来记录最新的日志。
在hadoop102
上,进入到/opt/module/hadoop-3.1.3/data/dfs/name/current
路径里,主要有下面四个关键文件:
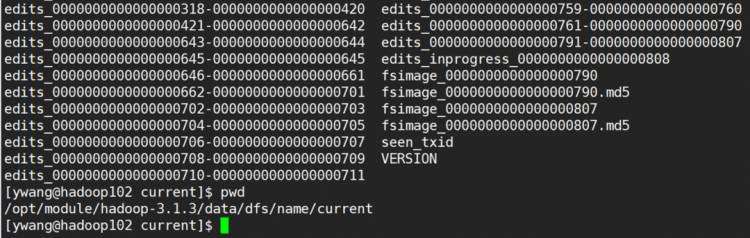
(1)fsimage
文件:HDFS
文件系统中元数据的一个永久性的检查点,其中包含HDFS
文件系统的所有目录和文件inode
的序列化信息;
(2)Edits
文件:存放HDFS
文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits
文件中;
(3)seen_txid
文件保存的是一个数字,就是最后一个edits_
的数字;
(4)每次nn
启动的时候都会将fsimage
文件读入内存,加载edits
里面的更新操作,保证内存中的元数据信息是最新的同步的。
我们可以使用命令查看fsimage
镜像文件,格式为hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径:
[ywang@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000790 -o /opt/software/fsimage.xml
查看输出的fsimage.xml
就能看的在镜像文件内部是以inode
的形势进行存储,而且有child
和parent
,很容易想到是一种树形结构。这里查看的时候我发现里面的文件与集群中的文件并不一一对应,原因应该是还没进行及时的更新和保存,因为合并时间设置的是每1h
进行一次合并。
blocks>
<storagePolicyId>0storagePolicyId>inode>
<inode><id>16388id><type>FILEtype><name>jdk-8u212-linux-x64.tar.gzname><replication>3replication><mtime>1636884567856mtime><atime>1637407569204atime><preferredBlockSize>134217728preferredBlockSize><permission>ywang:supergroup:0644permission><blocks><block><id>1073741826id><genstamp>1002genstamp><numBytes>134217728numBytes>block>
<block><id>1073741827id><genstamp>1003genstamp><numBytes>60795424numBytes>block>
blocks>
<directory><parent>16386parent><child>16387child><child>16416child><child>16436child>directory>
<directory><parent>16389parent><child>16390child><child>16487child>directory>
<directory><parent>16390parent><child>16391child>directory>
<directory><parent>16391parent><child>16399child><child>16392child>directory>
<directory><parent>16392parent><child>16393child>directory>
<directory><parent>16399parent><child>16456child><child>16400child>directory>
我们还可以使用命令查看edits
文件中的内容:
[ywang@hadoop102 current]$ hdfs oev -p XML -i edits_inprogress_0000000000000000813 -o /opt/software/edits.xml
查看输出的edtis.xml
可以看到文件本质是在做一系列的ADD
操作。
<RECORD>
<OPCODE>OP_ADDOPCODE>
<DATA>
<TXID>815TXID>
<LENGTH>0LENGTH>
<INODEID>16550INODEID>
<PATH>/new_dir/new_dir.txtPATH>
<REPLICATION>3REPLICATION>
<MTIME>1639036008660MTIME>
<ATIME>1639036008660ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_2049329202_37CLIENT_NAME>
<CLIENT_MACHINE>192.168.10.104CLIENT_MACHINE>
<OVERWRITE>falseOVERWRITE>
<PERMISSION_STATUS>
<USERNAME>ywangUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
<ERASURE_CODING_POLICY_ID>0ERASURE_CODING_POLICY_ID>
<RPC_CLIENTID>42b715f7-5977-466b-a31e-b8c02167f79fRPC_CLIENTID>
<RPC_CALLID>1977RPC_CALLID>
DATA>
RECORD>
另外,并不是每次合并都要用所有的edits
文件,是从edits_inprogress_0000000000000000830
这个文件序号开始最新的合并,这也是上面说的nn
与2nn
的唯一不同点。
(1)通常情况下,2nn
每隔一小时执行一次。这个参数在hdfs-default.xml
中;
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>3600svalue>
property>
(2)2nn每一分钟检查一次操作次数,当操作次数达到1百万时,2nn
执行一次;
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>操作动作次数description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60svalue>
<description> 1分钟检查一次操作次数description>
property>
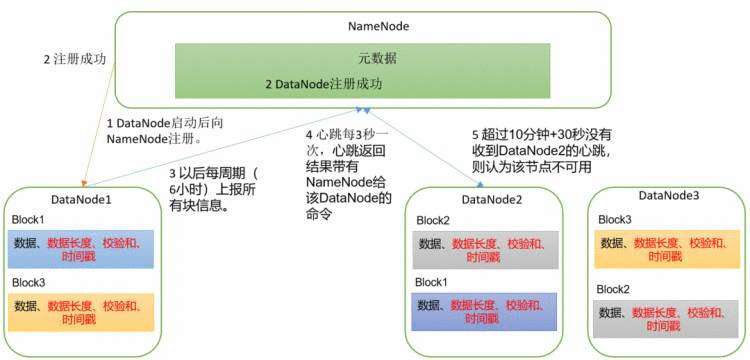
1、集群启动,dn向nn注册。内容是存在哪些block信息,其中数据长度、校验和、时间戳在.meta文件中存放
2、nn记录注册信息后,dn注册成功
3、dn每周期(6h)上报所以block信息。
4、同时dn每3秒进行通讯,dn要告诉nn,“我还活着”
5、如果没有进行可靠通讯,超过10m+30s没有收到dn心跳,则认为该节点不可用,以后不再向这里读写数据
dn
向nn
汇报当前解读信息的时间间隔,默认6小时。也在hdfs-defaults.xml
中:
<property>
<name>dfs.blockreport.intervalMsecname>
<value>21600000value>
<description>Determines block reporting interval in milliseconds.description>
property>
dn
自查时间:扫描自己节点块信息列表的时间,默认6小时。其实具体流程是先自查,没问题后再向nn
汇报。
<property>
<name>dfs.datanode.directoryscan.intervalname>
<value>21600svalue>
<description>Interval in seconds for Datanode to scan data directories and reconcile the difference between blocks in memory and on the disk.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.
description>
property>
在dn
中如何保证数据完整性呢?常用的方法是对数据进行校验,例如奇偶校验和循环冗余校验等。
1、当dn读取Block的时候,它会计算CheckSum(对收到的Block做校验)。
2、如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
3、Client读取其他DataNode上的Block。
4、常见的校验算法crc(32),md5(128),sha1(160)
5、dn在其文件创建后周期验证CheckSum。
上一篇的内容里在HDFS
中通过Shell
的各种操作是在集群内部跟集群进行客户端的交互,现在我们在本地通过wins
系统对远程的集群进行客户端访问,也就是在idea
中写代码。
对本地的wins
进行环境变量的配置,首先在 https://hadoop.apache.org/releases.html 下载wins
的hadoop
,我下载了hadoop-3.1.0
,把文件夹放到一个不含中文路径的目录,然后再系统环境变量中增加HADOOP_HOME和%HADOOP_HOME%\bin
(类似对JDK的配置),最后hadoop-3.1.0
文件夹的bin目录下双击一下 winutils.exe
即可。
新建一个maven
项目后,导入一些必要依赖,这里的hadoop3.1.3
必须要和集群的版本一致。并且在resources
目录下新建log4j.properties
,填入日志打印相关信息。
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.30version>
dependency>
dependencies>
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.COnversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.COnversionPattern=%d %p [%c] - %m%n
创建包以及一个HdfsClient.java
类:
像hadoop
和zookeeper
这种连接客户端都有一个常用的套路,首先获取客户端对象,其次执行操作命令,最后关闭资源。那么我们按照这个流程写一下java
代码。
package com.ywang.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testmkdir() throws IOException, URISyntaxException, InterruptedException {
// 连接集群namenode的地址,注意这里端口是集群内部的8020,9870是hdfs网页端的端口
URI uri = new URI("hdfs://hadoop102:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
// 用户名ywang
String user = "ywang";
// 1、获取客户端对象
FileSystem fs = FileSystem.get(uri, configuration, user);
// 2、创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan"));
// 3、关闭资源
fs.close();
}
现在做一下简单修改,提升下fs的作用域(idea的tips:选中fs,ctrl+alt+f,变为private即可)
,再把三步分开加上junit
注解。
package com.ywang.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 连接集群namenode的地址,注意这里端口是集群内部的8020,9870是hdfs网页端的端口
URI uri = new URI("hdfs://hadoop102:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
// 用户名ywang
String user = "ywang";
// 1、获取客户端对象
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
// 3、关闭资源
fs.close();
}
// 创建目录
@Test
public void testmkdir() throws IOException {
// 2、创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan"));
}
}
此时我们可以访问 http://hadoop102:9870/explorer.html#/ 就能查看到了创建的目录。
上传使用fs.copyFromLocalFile
进行操作,看代码:
// 上传文件
@Test
public void testPut() throws IOException {
// 四个参数:是否删除原始数据、是否允许覆盖、原数据路径、目的地路径
fs.copyFromLocalFile(false, true,
new Path("C:\\Users\\ywang\\Desktop\\sunwukong.txt"),
new Path("/xiyou/huaguoshan"));
}
关于上传文件优先级问题:我们默认的hdfs
有一个hdfs-default.xml
文件,其中有一个参数叫做dfs-replicattion
,它默认是3,现在测试hdfs
中参数的优先级。在resources目录下建立hdfs-site.xml
文件,写入
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
这个配置文件将副本数设置为1,同时在代码中的init()
对configuration
进行设置
configuration.set("dfs.replication", "2");
这段代码将副本数设置为2。经过测试可以发现,下方的指向里,越向右侧优先级越高。
hdfs-dufault.xml
=> hdfs-site.xml
=> 在resources
目录下的配置文件 => 代码中的配置
上传使用fs.copyToLocalFile
进行操作,看代码:
@Test
public void testGet() throws IOException {
// 三个参数:源文件是否删除、源文件路径、目标路径、CRC校验(true是关闭)
fs.copyToLocalFile(true, new Path("/xiyou/huaguoshan"),
new Path("D:\\"),
true);
}
@Test
public void testRemove() throws IOException {
// 两个参数:要删除的路径(或文件)、是否递归删除
fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"), false);
fs.delete(new Path("/xiyou"), false);
fs.delete(new Path("/jinguo"), true);
}
@Test
public void testMove() throws IOException {
// 更改文件名字
fs.rename(new Path("/wcinput/a.txt"), new Path("/wcinput/aa.txt"));
// 移动文件
fs.rename(new Path("/wcinput/aa.txt"), new Path("/cls.txt"));
// 更改目录名字
fs.rename(new Path("/wcinput"), new Path("/wcinput2"));
}
查看文件名称、权限、长度、块信息和块分布等。
@Test
public void testGetFileDetail() throws IOException {
// 获取所有文件信息,第一个参数是路径,第二个参数表示是否递归
RemoteIterator
// 遍历迭代器
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("======" + fileStatus.getPath() + "======");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
如何判断是文件和文件夹?用fs.listStatus()
获取所有文件。
@Test
public void testListStatus() throws IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
if (fileStatus.isFile()) {
System.out.println("isFile:" + fileStatus.getPath().getName());
} else {
System.out.println("isDirectory:" + fileStatus.getPath().getName());
}
}
}
查看更多Hadoop系列文章:
[1] 从头学习Hadoop
[2] Hadoop集群配置
[3] Hadoop集群配置(续)
[4] 来聊一聊HDFS
更多技术分享:技术文章分享目录









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 