话说python爬虫界,有个非常知名的框架Scrapy。异步爬取,使用简单,功能强大。辣条君,学习之,练习之。贝克街,一个推理爱好者论坛网站,用户数据量12W左右,很适合Scrapy学习练习爬取。本篇前半部分会介绍一点点基础,毕竟要照顾小白同学们嘛~
Tip:本文仅供学习与交流,切勿用于非法用途!!!
01. 写在前面的话
本博客在编写代码的同时,会简单介绍Scrapy这个框架。相较于辣条君写的前两篇爬虫博客,本篇博客爬取的数据量较大。
在写代码之前,我想说下贝克街这个网站。在两三年前,我上过几天这个网站,当时好像也就5、6万人,现在发展到12W多用户挺不容易的。一群推理爱好者的精神家园。本网站好像也没什么反爬措施,在再次申明免责声明的同时,辣条君恳请大家,仅仅学习交流,不要把人家服务器搞崩了哦。同时,本博客爬取的链接都在贝克街robots文件要求以外,绝对ok~
 在这里插入图片描述
在这里插入图片描述02. Scrapy安装
首先需要安装 lxml
库
pip install lxml
然后分别去以下两个链接,安装和自己本机python版本一致的 whl 文件
pywin32twisted
接着安装上面那两个库
pip install 你完整的pywin32whl 文件路径
pip install 你完整的twistedwhl 文件路径
例如:
pip install C:\Users\Administrator\Downloads\pywin32-228-cp38-cp38-win_amd64.whl
最后,可以安装Scrapy了
pip install scrapy
查看一下是否安装成功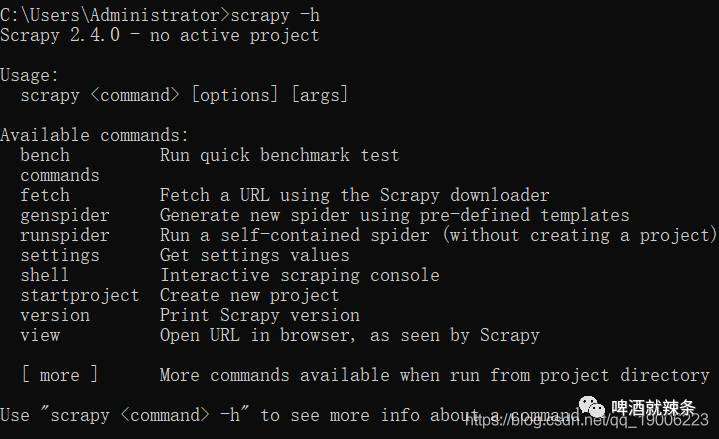 以上,我们就安装完毕了。
以上,我们就安装完毕了。
03. 项目结构简介
Scrapy为我们提供了一些好用的命令行,比如上一节的scrapy -h
。我们还可以使用命令行创建项目
scrapy startproject beikejie
然后,我们得到了如下的项目结构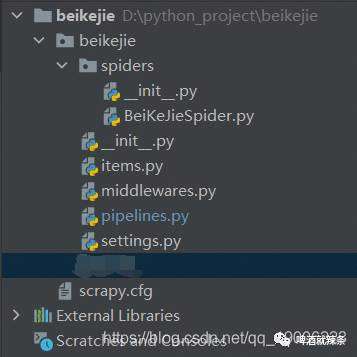 简单介绍下几个文件
简单介绍下几个文件
BeiKeJieSpider.py
:一个爬虫,咱们代码主要写和里面,后面会详细说。items.py
:数据实例,一个数据结构。pipelines.py
:数据爬取之后,进行数据清晰储存的地方。middlewares.py
:一些中间件,这里可以设置每次请求前的代理、COOKIE等。本项目不使用这个模块,毕竟人家没什么反爬措施嘛。settings.py
:一些项目的设置,可以设置很多东西,包括 pipelines 内管道的优先级等等,后面用到的地方会详细说。scrapy.cfg
:一些全局设置,本项目基本不适用。
04. 需求分析
本次爬取的目的,是获取贝克街所有的用户信息
思路:一批网站的大V,爬取他们的关注列表和粉丝列表,然后再以某个关注者或者粉丝为起点,继续爬取其关注列表和粉丝列表。这样可以爬取大部分用户,并不能爬取全部,因为毕竟可能会有无关注无粉丝的用户的用户孤岛。
所以我们要做的是:
根据某用户主页,获取一些用户信息。
获取某用户的关注列表,获取每个关注者主页,并执行第一步。
获取某用户的粉丝列表,获取每个粉丝主页,并执行第一步。
05. 获取用户信息
首先,我们需要编写根据某用户主页,获取用户信息,并储存mongo功能。
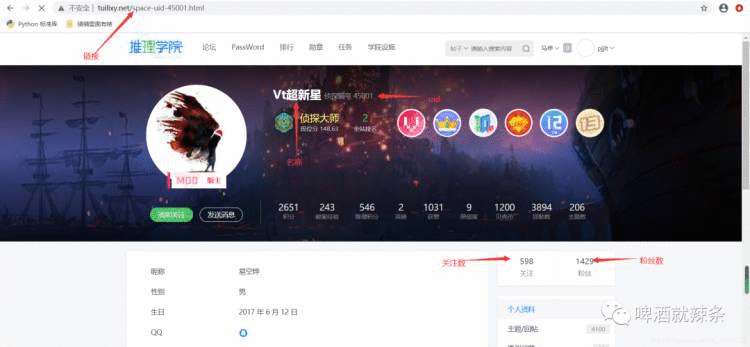 先在
先在 BeiKeJieSpider
中编写代码,这个是爬虫主要逻辑编写的地方。
class BeiKeJieSpider(scrapy.Spider):
name = "beikejie"
logger = logging.getLogger()
allowed_domains = ['tuilixy.net']
COOKIEs = {'你自己的COOKIE'}
def start_requests(self):
urls = [
'http://www.tuilixy.net/space-uid-45001.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
item = self.main_page_parse(response)
yield item
# 解析主页数据
def main_page_parse(self, response):
select = Selector(response)
uid = select.xpath('//*[@id="main"]/div[2]/div/div/div[2]/div[1]/h1/span/text()').get(default='- -').split(' ')[1]
name = select.xpath('//*[@id="main"]/div[2]/div/div/div[2]/div[1]/h1/text()').get(default='-')
register_time = select.xpath('//*[@id="pbbs"]/tbody/tr[2]/td[2]/text()').get(default='-')
follower_numbers = select.xpath('//*[@id="ct"]/div[2]/div[1]/ul/a[1]/li/h4/text()').get(default=0)
fans_numbers = select.xpath('//*[@id="ct"]/div[2]/div[1]/ul/a[2]/li/h4/text()').get(default=0)
item = BeikejieItem()
item['uid'] = uid
item['name'] = name
item['register_time'] = register_time
item['follower_numbers'] = follower_numbers
item['fans_numbers'] = fans_numbers
return item
上面我们说了,这个类实际上就是一直爬虫,name
就是爬虫的名字,allowed_domains
是此爬虫可以爬取的域名,start_requests
是起始爬取页面,这里面urls
就是那些大V的主页,为了方便说明,我们这边从一个大V的主页开始。
爬取完了,进入回调函数parse
进行解析,注意此方法内返回数据使用的是yield
,此关键字实际上是生成了一个迭代器,再次进入函数时,会接着从yield
处开始执行,后面会有妙用。然后解析完了,会返回一个BeikejieItem
实例,因为返回的是item
,所以会让pipelines.py
进行进一步处理。
那么们先看下数据结构BeikejieItem
所在的items.py
文件吧。
class BeikejieItem(scrapy.Item):
uid = scrapy.Field()
name = scrapy.Field()
register_time = scrapy.Field()
follower_numbers = scrapy.Field(serializer=int)
fans_numbers = scrapy.Field(serializer=int)
需要继承scrapy.Item
,然后定义一些需要储存的数据字段。可以看到,字段还可以设置储存类型。
有了数据结构,那么接着看下管道处理pipelines.py
文件吧。
class MongoPipeline:
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.mongo_collection = None
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.mongo_collection = self.db['beikejie']
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.mongo_collection.insert_one(ItemAdapter(item).asdict())
return item
class DuplicatesPipeline:
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
if adapter['uid'] in self.ids_seen:
raise DropItem(f"Duplicate item found: {item!r}")
else:
self.ids_seen.add(adapter['uid'])
return item
def close_spider(self, spider):
print(self.ids_seen)
这里有两个Pipeline分别都会处理传进来的item,优先级待会会被配置到文件settings.py
里面。
先看下这两个Pipeline,DuplicatesPipeline
是去重用的,内存中维护了一个set,存放存入库中的uid
,避免重复,如果存在就报错。其实本博客的去重不太完美,首先内存问题,一个12w个元素的大集合维护是个问题,并且没有持久化(当然可以最开始,从mongo中读出所有库中已存在的uid),没有考虑到分布式。未来后期,去重应该交给Redis这种缓存中间件,这边只是演示作用。
第二个MongoPipeline
,是进行mongo储存,细品一番~ 首先执行类方法from_crawler
,从配置文件settings.py
中读取mongo库的信息,然后执行__init__
初始化信息,初始化实例属性mongo_uri
、mongo_db
。接着执行open_spider
,这个方法开启一个爬虫的时候会被执行,生成真正的数据库链接mongo_collection
。每次进入管道,都会执行process_item
方法,进行数据插入操作。close_spider
这个方法顾名思义,只有关闭一个爬虫的时候会执行,将数据库链接关闭。
去重和存库的管道都介绍完了,下面查看一下配置信息,looksettings.py
。
ITEM_PIPELINES = {
'beikejie.pipelines.DuplicatesPipeline': 299,
'beikejie.pipelines.MongoPipeline': 300
}
MONGO_URI = '127.0.0.1:27017'
MONGO_DATABASE = 'pjjlt'
ITEM_PIPELINES
就是开启以上的两个管道,数字越小,优先级越高,所以去重优先于存库管道,符合逻辑。下面是数据库配置信息。当然,settings.py
还有很多配置信息,有用到你可以自己看撒~
以上,我们实现了一个用户主页数据的读取和储存。下面我们去做第二步和第三步。
06. 获取关注者列表
继续回到BeiKeJieSpider
这个类,我们继续爬取关注者列表。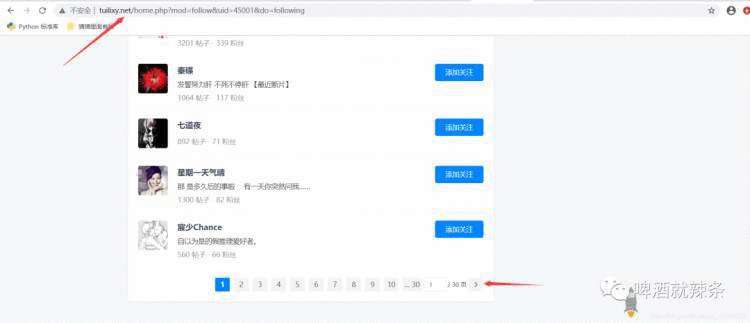 可以看出,关注者列表是分页的,我们可以根据
可以看出,关注者列表是分页的,我们可以根据下一页
按钮获取下一页url进行翻页操作。每页关注者列表都可以获取到它们的uid
,从而我们又可以去拼凑出每个关注者的主页url。献上代码~
COOKIEs = {'你自己的COOKIE'}
def parse(self, response):
item = self.main_page_parse(response)
yield item
uid = item['uid']
try:
# # 点击关注连接,进入关注页,爬取每个关注者的信息 http://www.tuilixy.net/home.php?mod=follow&uid=45001&do=following
follower_url = f'http://www.tuilixy.net/home.php?mod=follow&uid={uid}&do=following'
yield scrapy.Request(url=follower_url, COOKIEs=self.COOKIEs, callback=self.follower_parse)
except Exception as e:
logging.error("失败:uid:"+uid+"\n错误原因是: "+str(e))
def follower_parse(self, response):
logging.info('开始爬取关注列表,'+response.url)
doc = pq(response.text)
lis = doc('.flw_ulist.prw.plw').children('.ptf.pbf.cl')
for li in lis:
try:
url_end = pq(li)('.z.avt.w60.br4').attr('href')
if url_end:
url = 'http://www.tuilixy.net/'+url_end
yield scrapy.Request(url=url, callback=self.parse)
except Exception as e:
logging.error("爬取关注失败:url:" + response.url +"\n错误原因是: "+str(e))
try:
# 翻页
turn_page_url_start = doc('.nxt').attr('href')
if turn_page_url_start:
turn_page_url = 'http://www.tuilixy.net/'+turn_page_url_start
yield scrapy.Request(url=turn_page_url, COOKIEs=self.COOKIEs, callback=self.follower_parse)
except Exception as e:
logging.error("爬取关注失败:url:" + response.url+"\n错误原因是: "+str(e))
首先,补充下我们上面写的parse
方法,储存完某用户的信息后,爬取这个用户的关注者列表的第一页。获取到第一页关注着列表后执行回调函数follower_parse
。
follower_parse
主要干了两件事,获取本页所有用户的uid
,拼凑其用户主页url,并且执行获取用户主页的回调函数parse
。(就是去做我们需求分析的第一步)。第二件事就是,获取下一页url,进行翻页操作,获取下一页关注者列表,并执行获取关注者列表的回调函数follower_parse
。如此往复,知道该用户的关注者列表被翻到最后一步。
请求关注者列表需要加入COOKIE,这个需要你自己从浏览器获取(需要登录,都爬人家了,不得注册一个账号嘛,嗯哼?)。值得一提的是,Scrapy的Request方法,设置COOKIE必须显示设置,不能通过将COOKIE放到headers中! 这个知识点消耗了辣条君好多时间找问题,害,还是太菜。。知道点开Request源码。
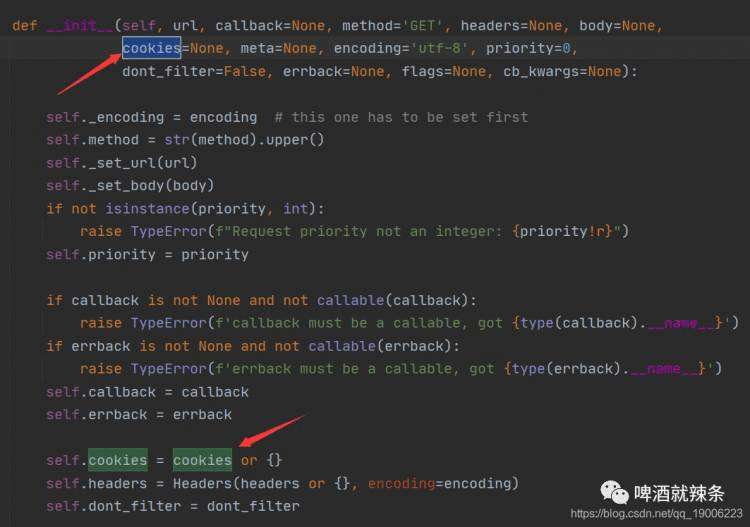 以上,我们就完成了某用户的关注者列表的爬取。
以上,我们就完成了某用户的关注者列表的爬取。
07. 获取粉丝列表
和爬取关注者逻辑一样,直接上代码吧。
def parse(self, response):
item = self.main_page_parse(response)
yield item
uid = item['uid']
try:
# # 点击关注连接,进入关注页,爬取每个关注者的信息 http://www.tuilixy.net/home.php?mod=follow&uid=45001&do=following
follower_url = f'http://www.tuilixy.net/home.php?mod=follow&uid={uid}&do=following'
yield scrapy.Request(url=follower_url, COOKIEs=self.COOKIEs, callback=self.follower_parse)
# # 点击粉丝连接,进入粉丝页,爬取每个粉丝的信息 http://www.tuilixy.net/home.php?mod=follow&uid=45001&do=follower
fans_url = f'http://www.tuilixy.net/home.php?mod=follow&uid={uid}&do=follower'
yield scrapy.Request(url=fans_url, COOKIEs=self.COOKIEs, callback=self.fans_parse)
except Exception as e:
logging.error("失败:uid:"+uid+"\n错误原因是: "+str(e))
def fans_parse(self, response):
logging.info('开始爬取粉丝列表,'+response.url)
doc = pq(response.text)
lis = doc('.flw_ulist.prw.plw').children('.ptf.pbf.cl')
for li in lis:
try:
url_end = pq(li)('.z.avt.w60.br4').attr('href')
if url_end:
url = 'http://www.tuilixy.net/'+url_end
yield scrapy.Request(url=url, callback=self.parse)
except Exception as e:
logging.error("爬取粉丝失败:url:" + response.url+"\n错误原因是: "+str(e))
# 翻页
try:
turn_page_url_start = doc('.nxt').attr('href')
if turn_page_url_start:
turn_page_url = 'http://www.tuilixy.net/'+turn_page_url_start
yield scrapy.Request(url=turn_page_url, COOKIEs=self.COOKIEs, callback=self.fans_parse)
except Exception as e:
logging.error("爬取粉丝失败:url:" + response.url+"\n错误原因是: "+str(e))
08. 运行
逻辑写完了,加上写try、except,还有关键性注释,利用Scrapy命令行操作,开始跑吧。
scrapy crawl beikejie
crawl
就是执行一个爬虫,后面的参数是爬虫的name
。
由于辣条君原始大V url只有一条,所以只爬了部分数据,只有16429个用户信息,大约耗时将近2个小时。你可以多选几个大V,选的越多,数据就会越无限接近12W。后期我们还可以利用分布式,多开几个scrapy实例,提高爬取速度。
 在这里插入图片描述
在这里插入图片描述09. 结束
相比于前面两篇博客,这篇Scrapy数据量大,代码编写时间也较长,希望各位读者小伙伴会喜欢~
喜欢的小伙伴,点个赞再走吧,您的支持,辣条君感激不尽。
最后,如果有小伙伴需要完整代码,请评论区留下邮箱,或者通过CSDN私信辣条君获取吧。食用代码的时候,请稍微轻一点,人家服务器会疼的。逃~







 京公网安备 11010802041100号
京公网安备 11010802041100号