
作者 | Chilia
整理 | NewBeeNLP
什么是跨域推荐呢?一句话概括就是:跨域推荐(Cross-Domain Recommendation)是 迁移学习 在推荐系统中的一种应用。
跨域推荐的目的一般是下面几个:
解决冷启动/数据稀疏问题 :例如,一个公司的两个APP业务,用户群体(user)交叉很大,但是item不同,当A业务的用户首次来访B业务时(冷启动问题),如何做出有效的推荐、从而提升留存/转化率呢?或者,假如B业务的用户行为数据量很少(数据稀疏问题),训练的时候不免会过拟合,怎么去获得更丰富的用户数据呢?此时,A业务就可以作为源域、B业务作为目标域,利用好源域的丰富用户行为信息,作为目标域的辅助,使得在目标域甚至多个域上都能进行更好的推荐。例如,豆瓣根据用户的电影评论来给用户推荐书,这就是假设了同样的用户对于电影和书有着相似的品味。
跳出信息茧房 :基于同业务的推荐,往往会让用户的兴趣越变越窄,因为都是基于用户的行为进行挖掘的,当使用跨域推荐时可以跳出原先的舒适圈,从而改善推荐系统的平衡性、多样性和新奇性。
域的相似性来自于哪里?
域的相似性可以从如下几个方面来看:
Content-level 的相似性。指的是不同域的item/user有着相似的 属性 。例如Amazon music 和 Netflix的业务比较相似,虽然他们没有很多相同的user和item,但是user和item的属性是类似的。
User 相似性。两个域有着很多相同的用户。例如抖音和西瓜视频有很多公共用户。
Item 相似性。两个域有着很多相同的商品。例如Movielens 和 Netflix有很多相同的电影。
跨域推荐的分类
Single-target :一个具有丰富数据的源域,和稀疏数据的目标域。需要利用源域的辅助信息,提升目标域的推荐准确率。可以进行feature层面的参数共享,也可以进行user/item的embedding共享(直接把源域的embedding拿到目标域来用,或者进行某种mapping映射)。
Dual-target:同时提升两个域(或者多个域)的推荐效果,两个域的信息相辅相成。类似multi-tasking,这里需要防止negative transfer,即稀疏域对于源域有着负面的影响。所以,不能简单的把迁移方向从rich->sparse改成sparse->rich。
下面,介绍四种常见的跨域推荐解决方案。
1. 共享重合user/item的embedding表示
对于那些两个域中有重叠user/item的情况,可以共享、融合不同域中相同user/item的embedding表示,来使得embedding包含每个领域中的信息。如何 结合 不同领域中的embedding,是值得仔细研究的问题。
代表论文:A Graphical and Attentional Framework for Dual-Target Cross-Domain Recommendation[1] [ijcai, 2020]
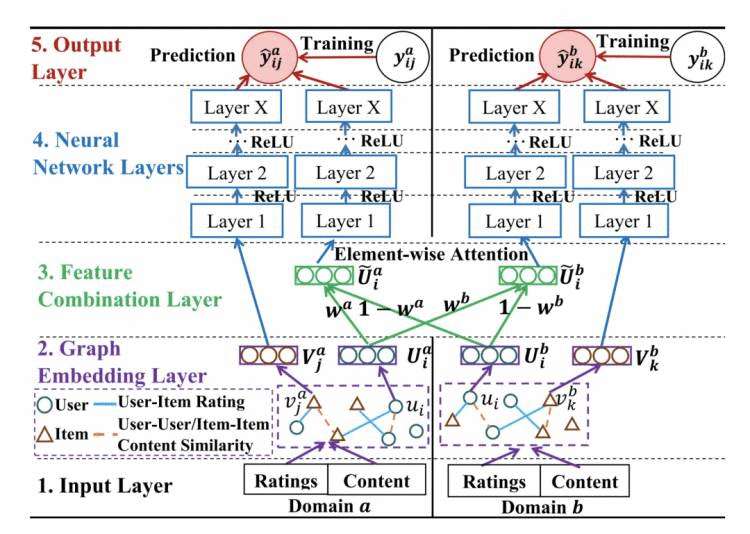
模型结构
这篇论文属于dual-target迁移,即 同时 提升源域和目标域的准确率。亮点有两个:
(1)使用图网络来建模user-item, user-user, item-item的关系
(2)更精细地合并不同域的重合user/item embedding(使用 attention 机制)
下面来详细介绍模型结构。
Input Layer: ratings就是我们熟悉的user-item评分矩阵,记录的是user-item互动关系;content端包括的是一些属性信息,例如对于item来说,可以是item detail信息;对于user来说,是user profile。
Graph Embedding Layer: 如果只使用collaborative filtering方法,那么就只考虑了user-item交互,而没有考虑user-user和item-item相似度信息。所以,不妨综合 user-item交互、user-user 相似度、item-item相似度构建图网络,然后利用deepwalk等node2vec方法得到user和item的embedding向量。(注:因为这个是召回模型,所以item embedding应该是提前线下算好存起来的)
⭐Feature combination layer: 之前的一些方法都是对两个域的重合embedding做一些简单的组合,例如average-pooling, concat等。但是这样并不能把握不同域embedding的重要性,所以本文使用了一种 element-wise注意力 机制,分别对两个域赋予不同的embedding权重。(注:本层是跨域迁移的重点,因为在这里综合了两个域中相同user/item的embedding。使用注意力机制是为了解决negative transfer的问题,即稀疏域因为学的没那么好,会对源域有着负面的影响 -- 这里就可以自动的为稀疏域的不太好的embedding分配较小权重,让它不要对源域的结果有太大影响。)
Neural Network layers: 因为这是个召回模型,所以这里是双塔,两塔之间无交互。
Output Layer: user塔和item塔输出归一化后求点积。由于召回点击日志没有负样本,所以还涉及到负采样。
2. 所有领域共享一个异构图的方法
对于不同领域间有重叠user/item的情况,可以以这些重叠user/item作为 桥梁 ,链接起不同的领域。这样,我们就得到了 一个所有领域共享的异构图 ,形如下图:
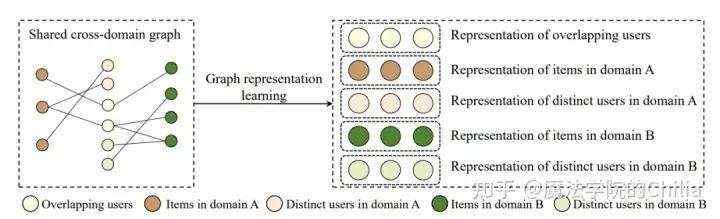
代表论文:HeroGRAPH: A Heterogeneous Graph Framework for Multi-Target Cross-Domain Recommendation \[recsys 2020\][2]
这篇文章还是为了解决协同过滤中的sparsity issue,只不过针对的是多个域的共同学习。如果有n个域的话,采用上文所述的pairwise迁移方法就需要构建 个域之间的关系,可不可以直接把所有域的关系都综合起来呢?
可以构建一个所有域共享的异构图,如果user对某个item有交互,那么user-item之间就有边,边的权重可以是正则化后的rating;user-user和item-item边的权重是它们属性特征的相似度。这里,重叠的用户充当着链接起多个域的“桥梁”:
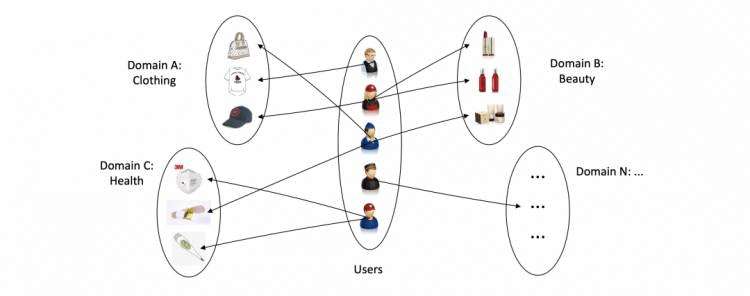
模型结构如下:
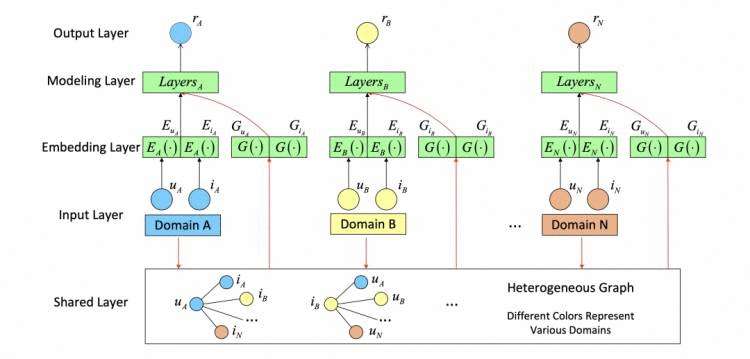
对于每个user/item分别学习两个embedding:
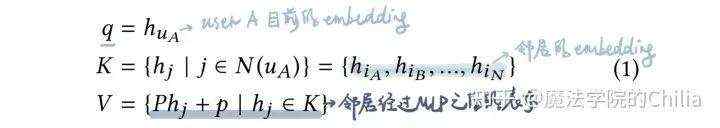
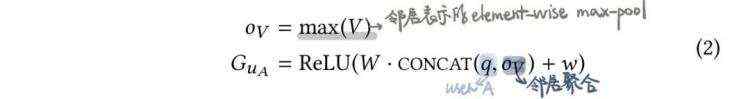
之后,把两个embedding用某些方法拼接/融合在一起,利用双塔模型计算user-item相似度。
3. 基于域间映射的模型
适用场景:存在多个数据较为充足的 源域 ,以及数据较为稀疏的 目标域 ,想要提高目标域上的 冷启动 推荐性能,而冷启动用户大多在源推荐领域有交互记录。
代表论文:Cross-Domain Recommendation: An Embedding and Mapping Approach[3] [ijcai 2017]
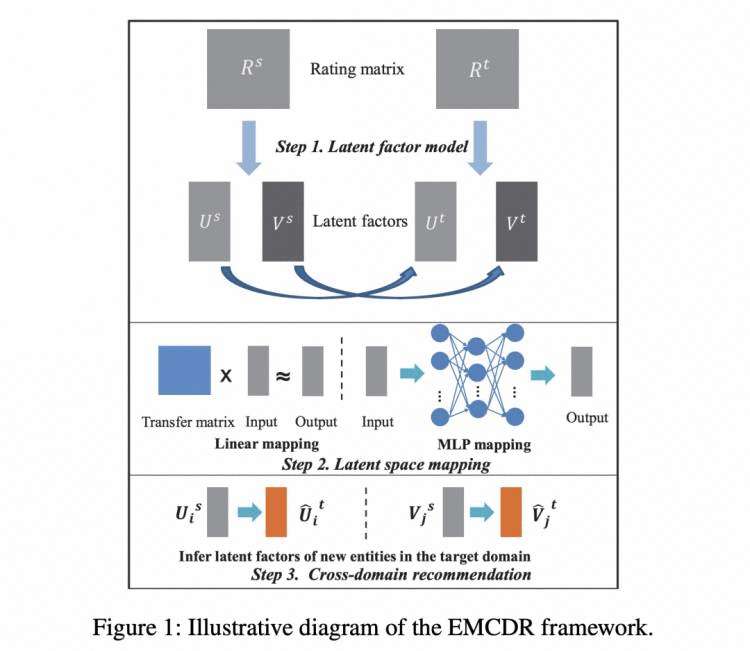
首先在每个领域对user-item的rating矩阵进行矩阵分解,得到每个域内user/item的embedding;之后利用 重叠实体 (以用户为例)训练一个由源领域到目标领域的 映射函数 ,试图使源域映射后的用户embedding接近目标域的用户embedding。这个映射函数可以是线性的( 图中step2 Linear mapping),也可以是非线性的(图中step2 MLP mapping)。训练完成后利用得到的映射函数便可以 将冷启动用户映射到目标领域 ,进行推荐。
4. 多领域共同训练
利用多个领域的数据同时对多个领域上的模型进行训练,通过模型间的信息交互使得每个领域的模型的推荐性能得到提高,类似 多任务学习 。
代表论文:CoNet: Collaborative Cross Networks for Cross-Domain Recommendation[4]
场景:用户在app商店下载app;同时在网上阅读新闻 -- 我们都用最简单的MLP来预估两个域上的CTR(注意这个任务是CTR预估,属于精排而非召回)。
那么,如何同时提高这两个域的推荐精度呢?最直接的transfer learning的思想就是把一个网络的前若干层直接拷贝到另一个网络做初始化,然后再在此基础上做微调。但是,这引入了一个很强的假设,即这两个域前几层的分布是一样的,然而事实并非如此。所以,我们可以用更为复杂的mapping来代替这种identical mapping。
模型结构如下:
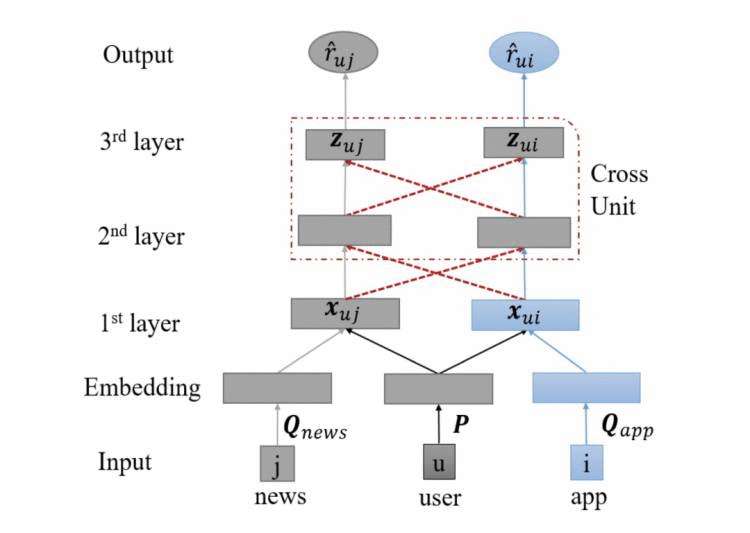
如果不看中间的红色虚线的话,我们会发现这就是两个最简单的CTR预估模型,即把user、item的特征拼接起来,然后输入MLP中得到预测结果。此时由于利用了两个域中的共同user,所以user embedding是共享的,两个任务的梯度都可以反传来更新user embedding,此时问题退化为shared-bottom多任务学习,共享的底层参数就是user embedding。
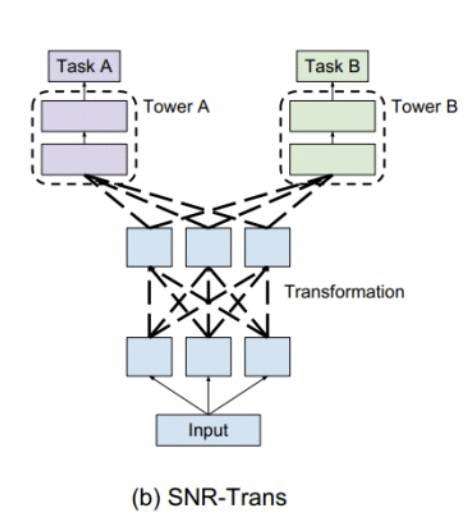
那么,能不能利用两个任务也来指导中间hidden layer的学习呢?本模型使用类似 Cross-stitch 网络,第L+1层隐藏层同时由本任务的第L层隐藏层和对方任务的第L层隐藏层决定:
这样,两个域的预测loss都可以反传来更新两个模型的 隐藏层 参数,起到了正则化和增加训练集的目的。
(注:这个模型和多任务CTR预估中的SNR比较类似,都是对不同子网络的输出进行组合又输入到了下一层子网络,形成子网络的组合。)
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
Graphical and Attentional Framework for Dual-Target Cross-Domain Recommendation: https://www.ijcai.org/proceedings/2020/0415.pdf
[2]
HeroGRAPH: A Heterogeneous Graph Framework for Multi-Target Cross-Domain Recommendation [recsys 2020]: https://ceur-ws.org/Vol-2715/paper6.pdf
[3]
Cross-Domain Recommendation: An Embedding and Mapping Approach: https://www.ijcai.org/proceedings/2017/0343.pdf
[4]
CoNet: Collaborative Cross Networks for Cross-Domain Recommendation: https://www.ijcai.org/proceedings/2017/0343.pdf











 京公网安备 11010802041100号
京公网安备 11010802041100号