篇首语:本文由编程笔记#小编为大家整理,主要介绍了python's fourthday for me 内置函数相关的知识,希望对你有一定的参考价值。
a = 1
def func():
b = 2
print(locals())
print(globals())
func()
print(eval(\'2+2\')) # 4
n = 4
print(eval(\'n+4\')) # 8
eval(\'print(666)\') # 666
s = \'\'\'
for i in [1,2,3]:
print(i)
\'\'\'
exec(s)
# 1
# 2
# 3
\'\'\'
参数说明:
1. 参数source:字符串或者AST(Abstract Syntax Trees)对象。即需要动态执行的代码段。
2. 参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。当传入了source参数时,filename参数传入空字符即可。
3. 参数model:指定编译代码的种类,可以指定为 ‘exec’,’eval’,’single’。当source中包含流程语句时,model应指定为‘exec’;当source中只包含一个简单的求值表达式,model应指定为‘eval’;当source中包含了交互式命令语句,model应指定为\'single\'。
\'\'\'
>>> #流程语句使用exec
>>> code1 = \'for i in range(0,10): print (i)\'
>>> compile1 = compile(code1,\'\',\'exec\')
>>> exec (compile1)
>>> #简单求值表达式用eval
>>> code2 = \'1 + 2 + 3 + 4\'
>>> compile2 = compile(code2,\'\',\'eval\')
>>> eval(compile2)
>>> #交互语句用single
>>> code3 = \'name = input("please input your name:")\'
>>> compile3 = compile(code3,\'\',\'single\')
>>> name #执行前name变量不存在
Traceback (most recent call last):
File "
name
NameError: name \'name\' is not defined
>>> exec(compile3) #执行时显示交互命令,提示输入
please input your name:\'pythoner\'
>>> name #执行后name变量有值
"\'pythoner\'"
\'\'\' 源码分析
def print(self, *args, sep=\' \', end=\'\\n\', file=None): # known special case of print
"""
print(value, ..., sep=\' \', end=\'\\n\', file=sys.stdout, flush=False)
file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件
sep: 打印多个值之间的分隔符,默认为空格
end: 每一次打印的结尾,默认为换行符
flush: 立即把内容输出到流文件,不作缓存
"""
\'\'\'
print(111,222,333,sep=\'*\') # 111*222*333
print(111,end=\'\')
print(222) #两行的结果 111222
f = open(\'log\',\'w\',encoding=\'utf-8\')
print(\'写入文件\',file=f,flush=True)
print(hash(123)) # 如果是整型,哈希值就是本身。
print(hash(\'123\')) # 1234915259760799069
print(hash(True)) # 1
print(hash(False)) # 0
print(hash((1,2,3))) # 2528502973977326415
print(id(123)) # 1497653856
print(id(\'123\')) # 2261173251408
print(id(\'abc\')) # 1573262368136
print(help(list))
Help on class list in module builtins:
class list(object)
| list() -> new empty list
| list(iterable) -> new list initialized from iterable\'s items
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __delitem__(self, key, /)
| Delete self[key].
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(...)
| x.__getitem__(y) <==> x[y]
|
| __gt__(self, value, /)
| Return self>value.
|
| __iadd__(self, value, /)
| Implement self+=value.
|
| __imul__(self, value, /)
| Implement self*=value.
|
| __init__(self, /, *args, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mul__(self, value, /)
| Return self*value.n
|
| __ne__(self, value, /)
| Return self!=value.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __repr__(self, /)
| Return repr(self).
|
| __reversed__(...)
| L.__reversed__() -- return a reverse iterator over the list
|
| __rmul__(self, value, /)
| Return self*value.
|
| __setitem__(self, key, value, /)
| Set self[key] to value.
|
| __sizeof__(...)
| L.__sizeof__() -- size of L in memory, in bytes
|
| append(...)
| L.append(object) -> None -- append object to end
|
| clear(...)
| L.clear() -> None -- remove all items from L
|
| copy(...)
| L.copy() -> list -- a shallow copy of L
|
| count(...)
| L.count(value) -> integer -- return number of occurrences of value
|
| extend(...)
| L.extend(iterable) -> None -- extend list by appending elements from the iterable
|
| index(...)
| L.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
|
| insert(...)
| L.insert(index, object) -- insert object before index
|
| pop(...)
| L.pop([index]) -> item -- remove and return item at index (default last).
| Raises IndexError if list is empty or index is out of range.
|
| remove(...)
| L.remove(value) -> None -- remove first occurrence of value.
| Raises ValueError if the value is not present.
|
| reverse(...)
| L.reverse() -- reverse *IN PLACE*
|
| sort(...)
| L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __hash__ = None
None
Process finished with exit code 0
>>>callable(0)
False
>>> callable("runoob")
False
>>> def add(a, b):
... return a + b
...
>>> callable(add) # 函数返回 True
True
>>> class A: # 类
... def method(self):
... return 0
...
>>> callable(A) # 类返回 True
True
>>> a = A()
>>> callable(a) # 没有实现 __call__, 返回 False
False
>>> class B:
... def __call__(self):
... return 0
...
>>> callable(B)
True
>>> b = B()
>>> callable(b) # 实现 __call__, 返回 True
>>>dir() # 获得当前模块的属性列表
[\'__builtins__\', \'__doc__\', \'__name__\', \'__package__\', \'arr\', \'myslice\']
>>> dir([ ]) # 查看列表的方法
[\'__add__\', \'__class__\', \'__contains__\', \'__delattr__\', \'__delitem__\', \'__delslice__\', \'__doc__\', \'__eq__\', \'__format__\', \'__ge__\', \'__getattribute__\', \'__getitem__\', \'__getslice__\', \'__gt__\', \'__hash__\', \'__iadd__\', \'__imul__\', \'__init__\', \'__iter__\', \'__le__\', \'__len__\', \'__lt__\', \'__mul__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__reversed__\', \'__rmul__\', \'__setattr__\', \'__setitem__\', \'__setslice__\', \'__sizeof__\', \'__str__\', \'__subclasshook__\', \'append\', \'count\', \'extend\', \'index\', \'insert\', \'pop\', \'remove\', \'reverse\', \'sort\']
it = iter([1,2,3]) #将列表[1,2,3]将列表转化成迭代器
while True:
try:
x = next(it) # 利用循环获取下一个值
print(x)
except Exception:
break #遇到报错就直接跳出循环。
from collections import Iterable
from collections import Iterator
l = [1,2,3]
print(isinstance(l,Iterable)) # True
print(isinstance(l,Iterator)) # False
l1 = iter(l)
print(isinstance(l,Iterable)) # True
print(isinstance(l,Iterator)) # True
a = 3 b = \'10\' print(float(a)) # 3.0 print(float(b)) # 10.0
print(complex(1,2)) # (1+2j)
print(complex(1)) # (1+0j)
print(complex(\'1\')) # (1+0j)
print(complex(\'1+2j\')) # (1+2j) ## 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",\\应该是"1+2j",否则会报错
print(complex(1+2j)) # (1+2j)
print(bin(10),type(bin(10))) # 0b1010
print(oct(10),type(oct(10))) # 0o12
print(hex(10),type(hex(10))) # 0xa
print(abs(-5)) #5
print(divmod(8,3)) #(2,2)
print(round(3.1415,2)) # 3.14
print(pow(2,3)) # 8
print(pow(2,3,3)) # 2
l = [1,2,3]
print(sum(l)) # 6
print(max(l)) # 3
print(min(l)) # 1
l = [1,2,3]
l2 = reversed(l)
print(l2) # #
print(\'__iter__\'in dir(l2)) # True
print(\'__next__\'in dir(l2)) # True
l1 = [1,2,3,4,5]
l2 = [\'1\',\'2\',\'3\',\'4\',\'5\']
sli_l = slice(3) # 相当从索引0切到3不包括3.
print(l1[sli_l]) # [1, 2, 3]
print(l2[sli_l]) # [\'1\', \'2\', \'3\']
print(format(\'顾清秋\',\'<30\')) #左对齐
print(format(\'顾清秋\',\'^30\')) # 居中
print(format(\'顾清秋\',\'>30\')) # 右对齐
# 顾清秋
# 顾清秋
# 顾清秋
s = \'顾清秋\'
bs1 = s.encode(\'utf-8\')
print(bs1) # b\'\\xe9\\xa1\\xbe\\xe6\\xb8\\x85\\xe7\\xa7\\x8b\'
bs2 = bytes(s,encoding=\'utf-8\')
print(bs2) # b\'\\xe9\\xa1\\xbe\\xe6\\xb8\\x85\\xe7\\xa7\\x8b\'
ret = bytearray(\'alex\',encoding=\'utf-8\')
print(ret) # bytearray(b\'alex\')
print(id(ret)) # 2250540703504
print(ret[0]) # 97 (\'a\' = 97)
ret[0] = 65
print(ret) # bytearray(b\'Alex\') (\'A\' = 65)
ret = memoryview(\'顾清秋\'.encode(\'utf-8\'))
print(len(ret)) # 9 #字节长度
print(ret) #
print(bytes(ret[:3]).decode(\'utf-8\')) # 顾
print(ord(\'a\')) # 97
print(ord(\'中\')) # 20013
print(chr(97)) # \'a\'
print(chr(20013)) # \'中\'
print(ascii(\'a\')) # \'a\'
print(ascii(\'中\')) # \'\\u4e2d\'
print(repr(\'{"顾清秋"}\')) # \'{"顾清秋"}\'
l = [1,8,3,5,4,9]
l2 = sorted(l)
l3 = sorted(l,reverse=True)
print(l2) # [1, 3, 4, 5, 8, 9]
print(l3) # [9, 8, 5, 4, 3, 1]
l = [\'a\',\'b\',\'c\']
print(enumerate(l))
for i in enumerate(l,1):
print(i,type(i))
for k,v in enumerate(l,1):
print(k,v)
# (1, \'a\')
# (2, \'b\')
# (3, \'c\')
# 1 a
# 2 b
# 3 c
print(all([1,2,True,0])) # False
print(any([0,False,1,\'\'])) # True
l1 = [1,2,3]
l2 = [\'a\',\'b\',\'c\',\'d\']
l3 = (\'*\',\'**\',\'***\')
l4 = zip(l1,l2,l3)
for i in l4:
print(i)
# (1, \'a\', \'*\')
# (2, \'b\', \'**\')
# (3, \'c\', \'***\')
def func(x):
return x % 2 == 0
ret = filter(func,[1,2,3,4,5,6]) # 通过一个函数,过滤一个可迭代对象返回的是迭代器。
print(\'__iter__\'in dir(ret)) # True
print(\'__next__\'in dir(ret)) # True
# print(ret.__next__()) # 2
for i in ret:
print(i)
# 2
# 4
# 6
def func(x):
return x**2
ret = map(func,[1,2,3,4])
for i in ret:
print(i)
# 1
# 4
# 9
# 16
l1 = [1,3,5,7,9]
l2 = [2,4,6,8,10]
ret = map(lambda x,y:x+y,l1,l2)
for i in ret:
print(i)
# 3
# 7
# 11
# 15
# 19
def cal(n):
return n**n
print(cal(2)) # 4
# 换成匿名函数
cal = lambda n:n**n
print(cal(2)) # 4
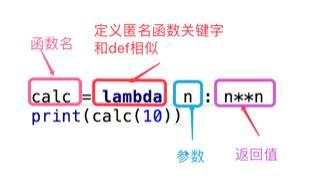
函数名 = lambda 参数 :返回值
1,参数可以有多个,用逗号隔开。
2,匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值。
3,返回值和正常函数一样可以是任意数据类型。
匿名函数并不是真的不能有名字。
匿名函数的调用和正常的调用也没什么分别,就是函数名(参数)就可以了...
匿名函数与内置函数举例:


l = [3,2,100,123]
print(max(l)) # 123
dic = {\'k1\':10,\'k2\':30,\'k3\':20}
print(max(dic)) # k3
print(dic[max(dic,key = lambda x:dic[x])]) # 30
res = map(lambda x:x**2,[1,2,3])
for i in res:
print(i)
# 1
# 4
# 9
res = filter(lambda x:x>3,[1,2,3,4,5])
for i in res:
print(i)
# 4
# 5





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 ![扫描线三巨头 hdu1928hdu 1255 hdu 1542 [POJ 1151]](https://img.php1.cn/3c972/245b5/42f/19446f78530d3747.jpeg)
