前言
我最近参与了公司的一个新项目,需要通过openapi接口把接入方的数据,比如:企业、订单、合同、物流等,同步到我们平台,然后我们平台给他们提供金融能力。
由于我方跟对接方不在同一个城市,为了提高工作效率,双方进行了多次在线视频沟通。刚开始比较顺利,没想到在沟通企业信息上传接口时,接口文档中有个非常不起眼的企业注册地id字段,让我们一下子进入了僵局。
到底是怎么回事呢?
1.地区问题
在我们平台的企业表中有一个企业注册地id字段,是必填的,用户在注册企业的页面需要选择一个地区,作为该企业的注册地,实际上数据库保存的是地区的id。
如果该企业注册成功了,会在企业详情页面上展示该地区名称。当然我们系统的后台逻辑是先通过地区id到地区表反查出地区名称,然后在用户界面中展示出来。
为了跟企业表保持一致,我方在定义接口文档时,企业注册地id字段也做成必填了。
当时的情况是这样的:我方地区表中有id、地区名称、国标码、等级等字段,但这里的id,是我方数据库的主键,对接方系统中肯定是没有的。对接方系统中也有一套地区表,不过id是他们的数据库id,他们的表中也有地区名称、国标码、等级等字段。
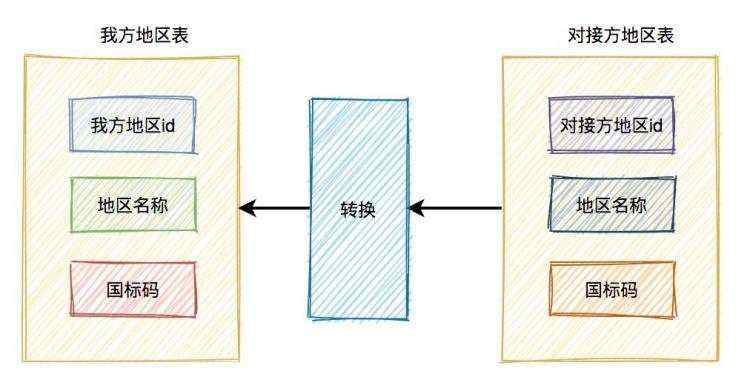
所以他们系统内部需要经过一番转换,才能把我们所需的地区id传给我们。
1.1 持久化本地地区表
其实这个项目我是中途才加入的,之前在处理别的事情,我加入的时候接口文档已经定义好了。
我方跟对接方进行第二次在线沟通的时候,双方一起过接口文档的细节,包括:接口的作用、每个参数的含义,以及他们是否有值传过来等等。
其中过到企业信息上传接口时,接口文档中有个企业注册地id字段,对方没法传值过来。为了解决这个问题,我方第一版的方案是:

- 对接方调用我方地区查询接口,通过多次分页查询,最终能获取我方所有地区数据,落库到他们本地的地区表。
- 他们在调用我方企业信息上传接口之前,先查询本地的地区表,转换成我方所需要的地区id。
在讨论的过程中,对接方觉得他们也是平台,不应该做这些额外的事情。所以在那次会议中,双方针对这个问题,谁也没有说服谁,最终也没能达成共识。
后来,我思考了一下,确实这个方案太过理想化了,没有真正站到用户的角度思考问题,忽略了很多细节。可能跟文档设计者不对地区表不太熟悉有关系。
1.2 按名称调用地区查询接口
那次会议当中,我们这边的几位同事,短暂的讨论了一下。既然对接方不愿意接受在他们本地持久化地区表,我们就退而求其次,不要求他们持久化了。这时我们这边有个同事提出,改成按名称调用地区查询接口,反查出地区id,具体方案如下:

这个方案表面上看起来没有问题,但我之前负责过区域相关功能,我知道,就怕出现如下情况:
- 如果对接方传的地区名称不完整,比如:本来是
成都市,实际上传的成都。这样,我们地区查询接口,需要做模糊匹配,如果并发调用接口可能影响接口性能。 - 如果输入关键字
北京市,在我们这边的地区表中,可以找到两条数据,一条是跟省级别一样的,另一条是跟市级别一样的。到底对应哪条数据呢?
所以我当时把这两个问题抛出来了,不建议使用地区名称查询。
1.3 按国标码调用地区查询接口
那个同事听完之后,也觉得用地区名称查询有点不靠谱。他马上修改方案,改成使用地区的国标码查询地区id,具体方案如下:

由于当时讨论时间非常短,我们没来得及考虑太多,暂且打算用这套方案。
1.4 企业上传接口入参传国标码
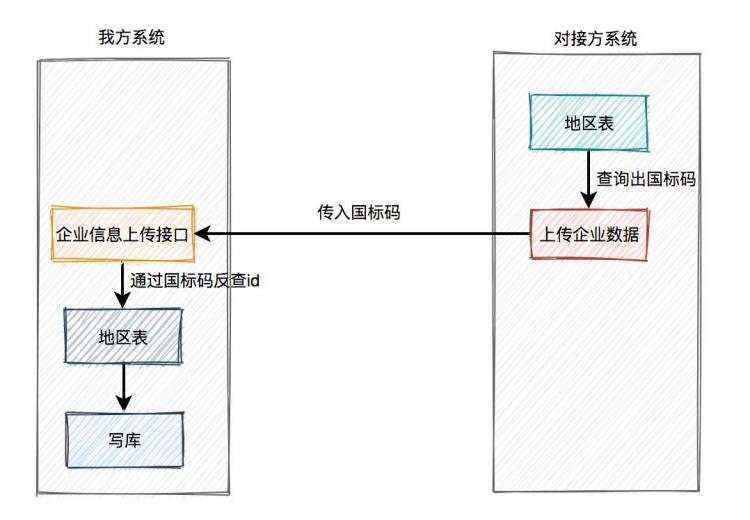
过了一会儿,双方继续过接口文档,重新讨论企业信息上传接口中企业注册地id字段传值问题。
他们在调企业信息上传接口之前,先调一下我们地区查询接口,查出地区id,入参是国标码。然后再将这个地区id,在企业信息上传接口中传过来。
对接方仔细听了我们的方案,犹豫了一下,他们觉得没有必要再调一次地区查询接口,双方都使用国标码不就行了?
他们的想法是:在企业信息上传接口中,入参由企业注册地id改成企业注册地国标码,由于国标码是国家统一的唯一编码,双方肯定是一样,能保证数据的一致性。
2.想起了一个问题
说实话,如果你没接触过地区功能的话,大部分人可能会同意这套方案的。
但比较巧合的是我之前正好接触过类似的功能,当时我突然想起了一个问题:双方数据的一致性如何保证?
我们都知道,由于国家的发展,有些城市可能会改名,比如:襄樊改成了襄阳,另外有时候多个地级市合并成一个市,这样国标码会变化,所以国家统计网每年都会调整地区名称和国标码。
我方的地区表是两年之前创建的,数据初始化好之后没有就更新过。
而对接方不是跟我们在同一时刻初始化的数据,而且他们会定期更新地区数据,这样就导致了两边的数据不一致。如果对接方的业务表单中使用了新加的城市名和国标码,而这些信息在我方的地区表中没有,就无法查询出我方所需的地区id。
这种情况该怎么办?
2.1 双方同一时刻更新地区表
显然上面的问题是一个非常棘手的问题,这时候有些小伙伴可能会说:双方使用job同一时刻更新地区表,不就能解决问题了?
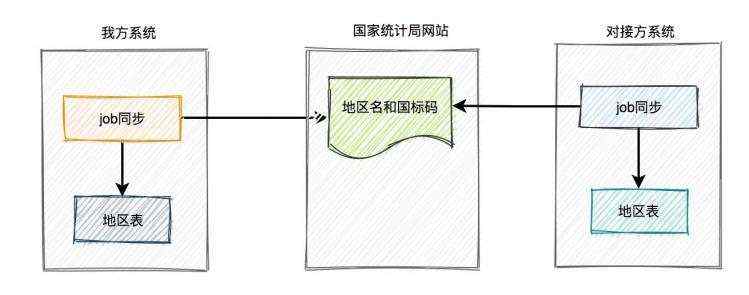
我不太赞成这种方案,主要原因如下:
- 我方仅跟这个对接方有个同步执行的job,没问题。但如果还有其他的对接方,也需要调用企业信息上传接口,是不是也要整一个job,而且还要求大家都同一时刻执行,耦合性太大了。
- 如果我方和对接方同时执行job,但万一有任意一方执行失败了,也会导致数据不一致的情况。如果恰好这时候对接方在调用企业信息上传接口,会不会出问题?
2.2 以一方的地区数据为准?
上面的双方同一时刻更新地区表的方案确实有点不靠谱,但有些读者可能会问,以一方的地区数据为准,另一方把数据同步过来不就行了。具体方案如下:
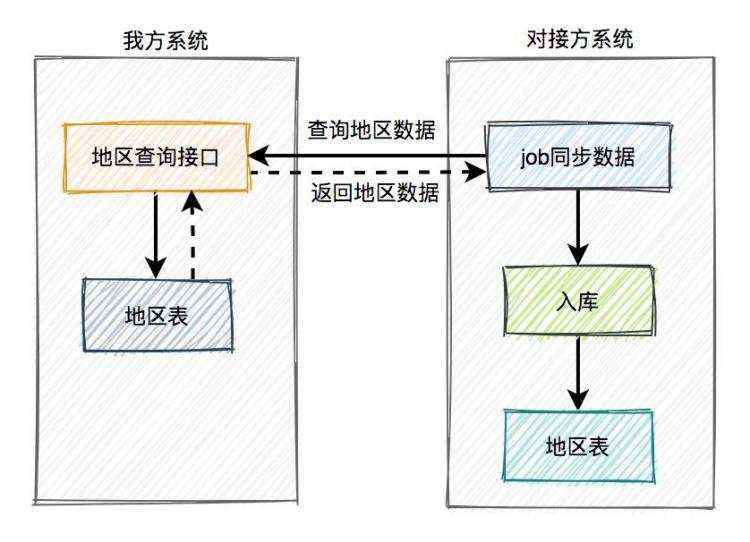
这个方案其实跟之前我方给出的第一个方案很相似,已经被对接方拒绝了。站在他们的角度来说,确实没有必要因为上传企业信息,而保存我们的地区数据。
说实话,即使他们同意了,这种跨公司跨系统的数据一致性问题,也不好保证,因为如果对接方调用我们的地区接口失败了,此时,正好在上传企业信息,是不是也有问题?
我们一下子进入了困境,但为了不影响整体进度,只能先记录一下问题,然后跳过这个问题,继续讨论其他字段了。
3.如何解决这个问题?
我当天晚上思考了良久,第二天早上,发现跟我们老大的想法不谋而合。得出的结论是,既然存在差异化,没办法避免,我们就要从系统设计上接受差异化。在企业信息上传接口中增加两个字段:企业注册地国标码 和 地区名称,对接方改成传入这两个字段,具体方案如下:
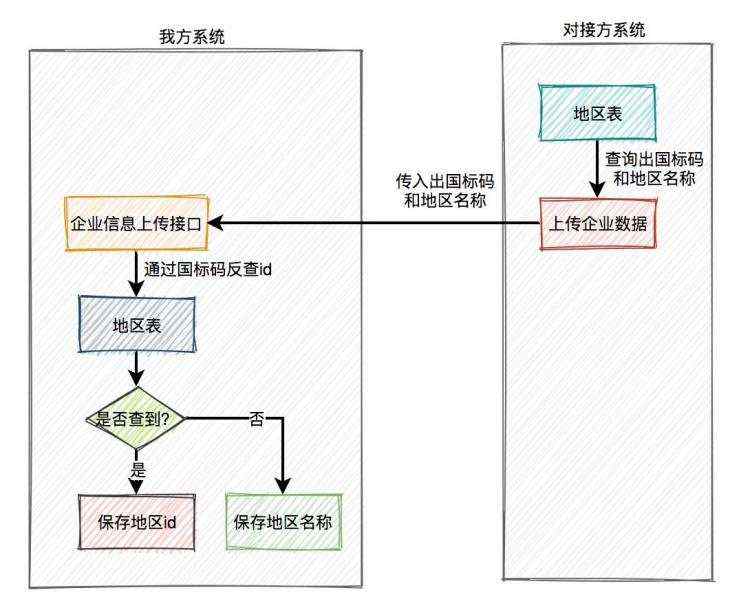
- 在我方的企业表中增加地区名称字段,是非必填的,同时把之前的地区id字段也改成非必填。
- 对接方在调用我方企业信息上传接口时,同时传入地区国标码和地区名称。
- 我方企业信息上传接口中判断,如果通过国标码能够找到地区id,则将地区id写入db,如果找不到,则将地区名称写入db。
我们评估了一下影响范围,在企业表中的地区字段,只做展示用,没有修改入口,所以上面的这套方案是可行的。
后来,再次跟对接方在线沟通时,把我们的这套方案告诉他们了,他们非常赞同。
4 总结
虽说这个地区问题,在众多技术问题中不值得一提。但是我仔细思考了一下,还是有一些宝贵的经验值得总结一下的,给有需要的小伙伴一个参考。
4.1 要从用户的角度设计接口
在设计接口文档时,要真正做到从用户的角度出发。
尤其是像这种openapi接口,定义的参数应该尽量选择通用的,大家都认可的参数,避免出现我方定制化的参数,比如:地区id。
尽量减少用户的复杂度,让他们调用接口时更简单一些。
4.2 技术方案要有包容性
技术方案要有包容性,不是非黑即白,需要有柔性的思想。在分布式环境中,如果去一味地追求数据的强一致性,不会有太好的结果。就像高并发下的商品秒杀系统,如果非要用同步方案去实现,系统最终可能会挂掉,更好的方案其实是改成异步队列处理。
我方和对接方都有地区表,数据很难保证完全一致,我们不要为了一致性而一致性,这样会适得其反。为了工作能够顺利进行下去,必然有一方要妥协,我的建议是openapi接口方做妥协,这种技术方案才够通用。
4.3 没有最好的方案,只有最适合的
我方最后的那个方案,其实并没有完全解决地区id找不到的问题,但是从业务的角度来看,即使没有地区id,有地区名称也是一样的。很显然,最后的方案是非常适合我们实际业务场景的。
所以没有最好的方案,只有最适合业务场景的。
4.4 进行有效的沟通
在跟对接方在线沟通时,不要因为某个问题卡壳了,而一直僵持下去。如果当时没有好的技术方案,可以先选择暂时跳过这个问题,而沟通其他的内容。后面我们再私下单独花时间,仔细思考当时的问题,从而能够提出更合理的方案。



 京公网安备 11010802041100号
京公网安备 11010802041100号