作者:双鱼天脎 | 来源:互联网 | 2023-09-02 12:08
篇首语:本文由编程笔记#小编为大家整理,主要介绍了词向量与ELMo模型 词向量漫谈相关的知识,希望对你有一定的参考价值。
目录:
- 基础部分回顾(词向量、语言模型)
- NLP的核心:学习不同语境下的语义表示
- 基于LSTM的词向量学习
- 深度学习中的层次表示以及Deep BI-LSTM
- ELMo模型
- 总结
1. 基础部分回顾(词向量、语言模型)
1.1 独热编码-词的表示
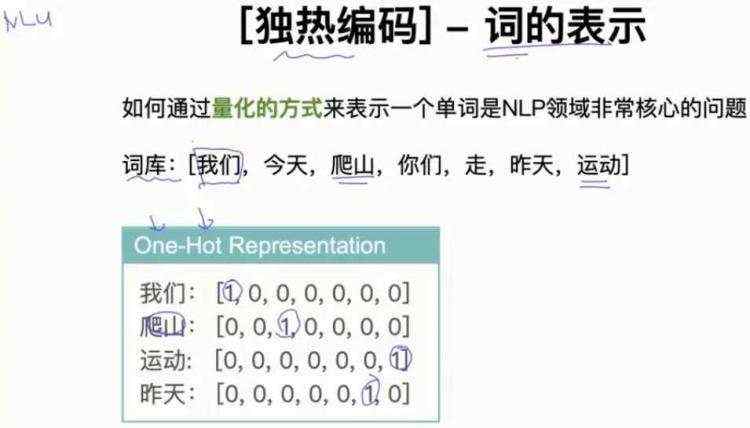
1.2 词向量-词的表示
- 我们为什么需要词向量?(One-hot向量的缺点?)
- 基于One-hot能否表示单词之间语义相似度?
1.2.1 基于One-hot能否表示单词之间语义相似度?
答:不可以。因为,我们不管是通过欧式距离还是通过余弦相似度,计算用One-hot表示的词编码都是一样的距离,不能区分单词之间语义的相似度。
比如,计算:我们、爬山的欧式距离、余弦相似度:

当然每个词之间的余弦相似度也都是相同的。词向量学习到的每个向量都是用不同的浮点数表示,计算每个单词的相似度是不一样的,可以表示单词之间语义相似度。
1.2.2 One-hot向量的缺点?
- One-hot向量稀疏性,词向量是稠密向量;
- One-hot向量不能表示单词之间语义相似度;
词向量从2013年提出开始,慢慢的发展成现在的Bert、XLNet等比较前言的技术。
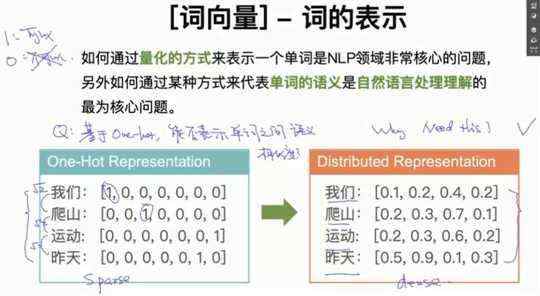
1.3 词向量-词向量的可视化
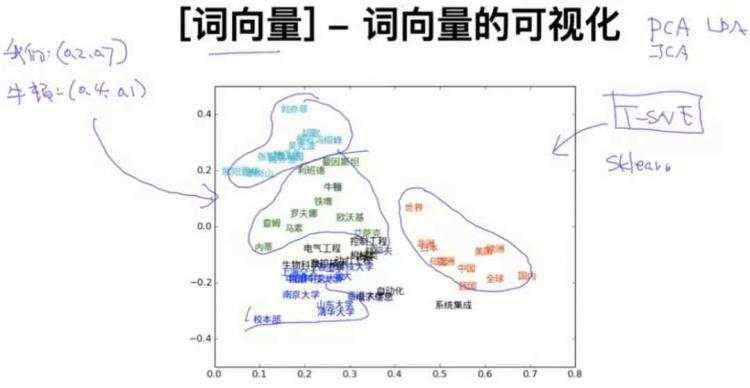
把词向量表示成二维数据后,可以发现类似的单词是聚在一起的,因此可以得出词向量可以区分单词之间语义的相似度。
词向量的可视化常用的算法是sklearn中的T-SNE,它是一种降维算法。降维算法还有PCA、ICA、LDA,针对词向量的降维我们通常使用T-SNE,Bengio在他文章中介绍T-SNE非常清楚。我自己找了一下Bengio的文章,没有找到介绍T-SNE的内容,谁找到告诉一下哈!
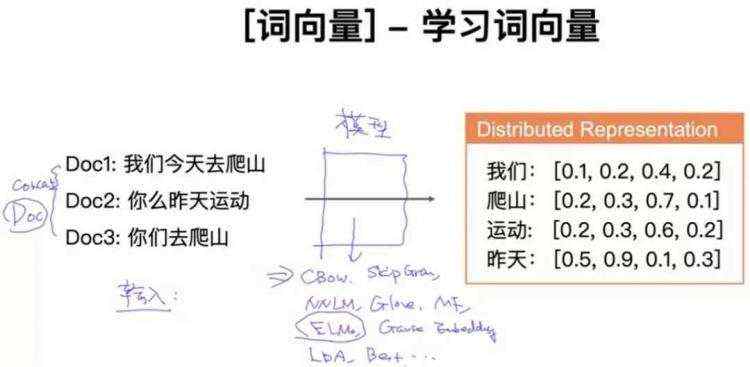
1.4 词向量-学习词向量
把一堆文本输入到某些模型中,我们可以得到词向量。模型包括:CBOW、Skip-Gram、NNLM、Glove、MF、ELMo、Gaus Embedding、LDA、Bert等。

2. NLP的核心:学习不同语境下的语义表示
2.1 语言模型-概念

2.2 语言模型-对于句子的计算
2.2.1 Chain Rule
贝叶斯公式:
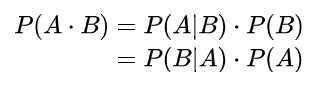
Chain Rule:
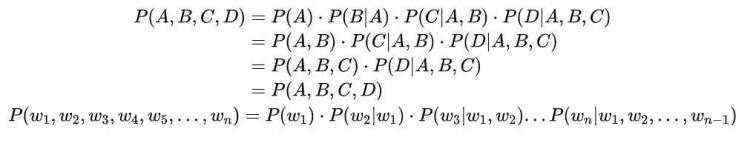
2.2.2 Chain Rule for Language Model
2.2.3 Markov Assumption

2.2.4 Language Model(Use 1st Order)
假设现在我们知道这些单词的概率:
P(是|今天) = 0.01
P(今天) = 0.002
P(周日|是) = 0.001
P(周日|今天) = 0.0001
P(周日) = 0.02
P(是|周日) = 0.0002
比较:“今天是周日 VS 今天周日是 ”两句话哪一句从语法上更通顺?
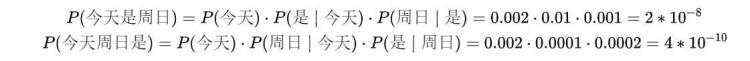
显然, P(今天是周日) >P(今天周日是) 。
ELMo是基于语言模型的目标函数进行训练的。

2.3 语言模型-相关必要知识点
- Chain Rule, Markov Assumption
- Unigram, Bigram, Ngram
- Add-one smoothing, Good-turning smoothing...
- Perplexity

图片来源于:网友
2.4 基于分布式表示的模型总览
介绍词向量的总览,各个词向量模型之间的联系和区别。
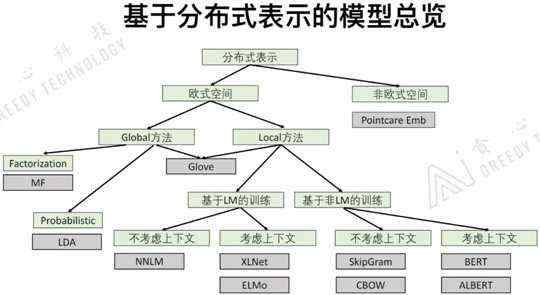
Global方法:把非常大的数据放到模型中学习,得到全局的数据信息。优势:可以从全局的角度考虑问题。劣势:1)计算量很大;2)不能在线学习。
Local方法:基于窗口式的方法进行训练,是一种局部的方法。优势:1)可以随时的增加数据进行训练,也就是可以在线学习;2)可以用在大数据里面。缺点:不能从全局的角度考虑问题。

2.5 建议的学习路径
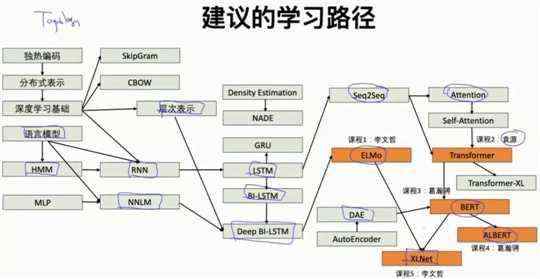
2.6 词向量训练常见的方法


- SkipGram方法:预测相邻单词的概率。
- CBOW方法:已知两边单词,预测中间单词。
- NNLM方法:基于语言模型和马尔科夫假设进行

基于SkipGram、CBOW和NNLM的方法,我们可以训练出每一个单词的固定词向量。但是在同一句话中,这些方法不能表示相同单词的不同语义。因此我们引出ELMo、Bert和XLNet。
即,如何学出一个单词在不同上下文中的词向量呢?


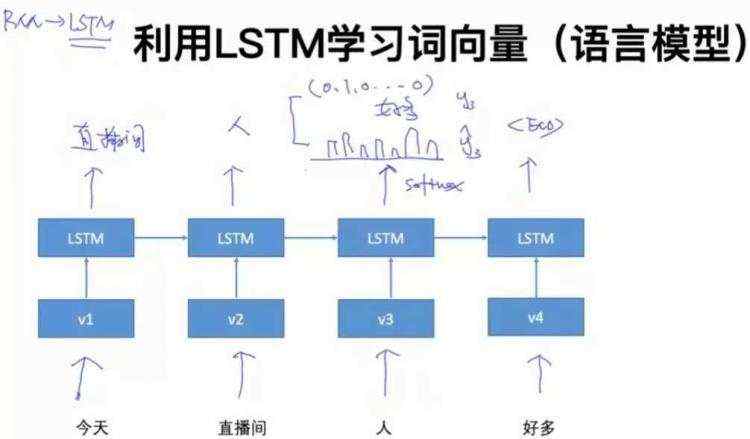
3. 基于LSTM的词向量学习
3.1 利用LSTM学习词向量(语言模型)
3.2 从单向LSTM到双向LSTM
单向LSTM只能从左到右的预测单词,有时我们想利用单词左右两边的信息,即双向信息,因此我们需要双向LSTM。
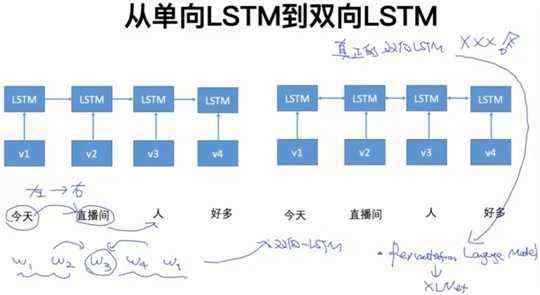
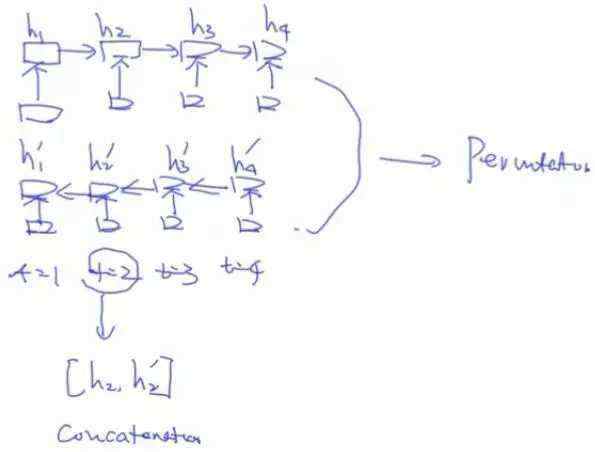
XLNet用Permutation language model 实现真正的双向LSTM模型。
以下这种形式不是完全双向的LSTM模型:
4. 深度学习中的层次表示以及Deep BI-LSTM
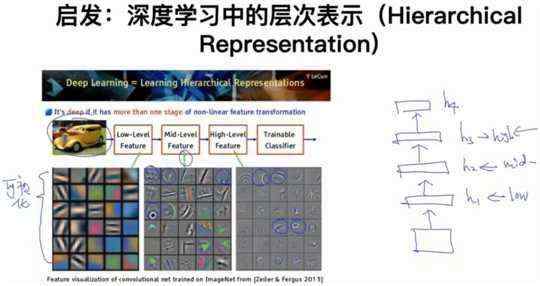
4.1 启发:深度学习中的层次表示(Hierarchical Representation)
越高级的特征表示越来越具体化。
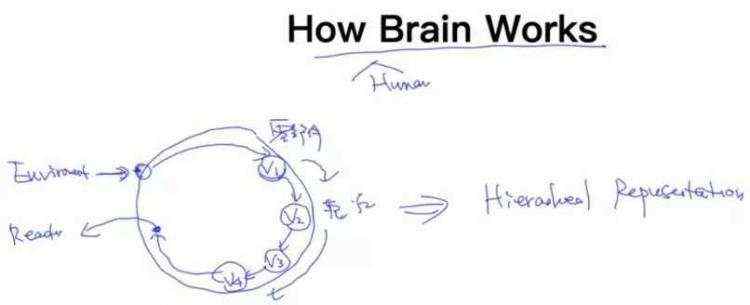
4.2 How Human Brain Works
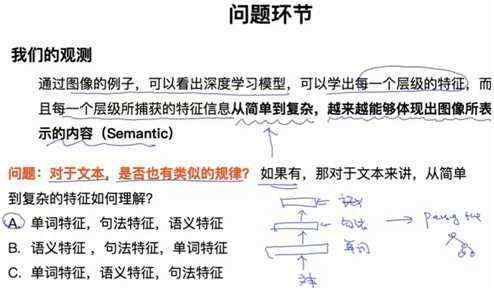
4.3 图像中有层次表示,NLP中是否也有?

4.4 Deep BI-LSTM
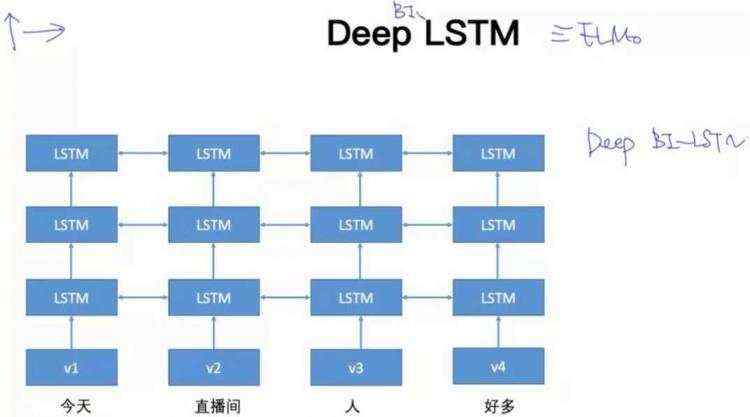
4.5 训练以及使用
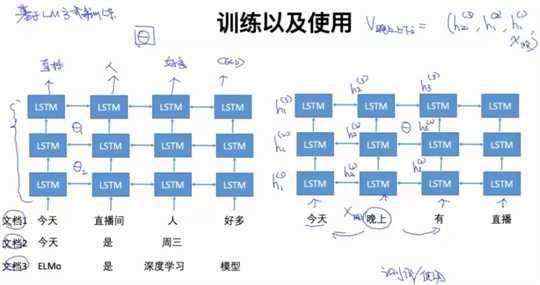
ELMo具体细节可以翻阅论文:Peters M E , Neumann M , Iyyer M , et al. Deep contextualized word representations[J]. 2018.
5. ELMo模型
5.1 ELMo的数学表达

5.2 实验
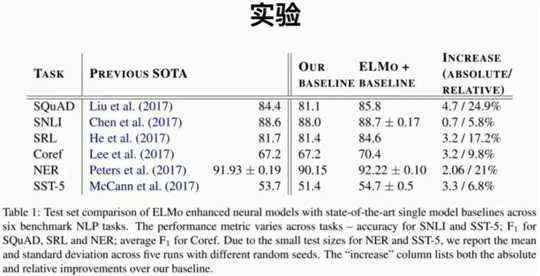
这一部分展示了ELMo模型论文中的实验结果。
6. 总结

本文是Microstrong在观看李文哲在B站上讲解的直播课程《词向量与ELMo模型》的笔记。直播地址:https://live.bilibili.com/11869202
原文地址:词向量漫谈,欢迎大家关注Microstrong公众号!!!




![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号