作者:手机用户2502895461 | 来源:互联网 | 2023-08-19 18:12
实验要求及步骤参考博客:https://blog.csdn.net/qq_41035588/article/details/90514824,但是创建的项目是Map/Red
实验要求及步骤
参考博客:https://blog.csdn.net/qq_41035588/article/details/90514824,但是创建的项目是Map/Reduce项目。其实创建Java项目也可以做,只是需要导入Map/Reduce项目所需要的jar包。
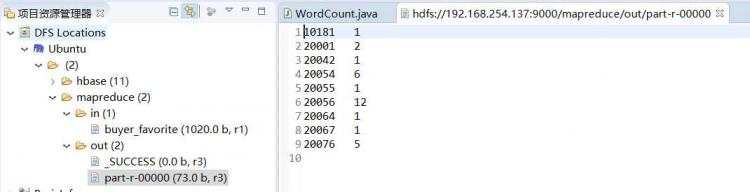
运行结果截图
出现的问题及解决办法
文件buyer_favorite在eclipse上打开会出现空格乱码的情况,但是不影响本次实验,可以忽略不计。或者也可以将空格改为其它间隔符,如“|”。
eclipse里不能对Hadoop上的文件进行创建操作(创建新文件夹,上传文件和文件夹),只能查看和删除。原因是权限不够,需要关闭Hadoop后修改hdfs-site.xml文件再开启Hadoop。
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/hadoop/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/hadoop/local/hadoop/tmp/dfs/datavalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
林子雨的Hadoop配置教程里只有前三项,需要再加上高亮区域那一项。







 京公网安备 11010802041100号
京公网安备 11010802041100号