1.生产者发送消息如果没有key值,要设置成null,不能设置成空字符串,否则会认为空字符串是key值,会把所有消息发送到一个分区上。
2.生产者设置消息批量发送,需要设置两个属性:batch.size和linger.ms。前者是消息积攒到多大时,发送给broker。后者是超过多少毫秒时,发送给broker。两者只要触发一个条件,就会把积攒的消息批量发送给broker。
需要注意的是,不管是否批量发送消息,produce都要显式调用close方法,只不过批量发送消息时,KafkaProducer会把消息存起来,触发条件后,才统一发送给broker。
当还没有到达batch.size的阈值,也没有到达linger.ms的阈值时,如果此时线程突然中断了,那么这批次的消息就会丢失,不会发送给broker。当这两个条件都没触发时,但是调用了produce的close方法,会把这个批次的消息提交至broker的。
3.batch.size的值,设置大小要合理,设置太大,会造成阻塞,效率反而更慢,下面复原一下问题。
本来想测试一下消费端的数据处理能力,所以在生产者端,我把batch.size的值设置成了21300000,不要问为什么设置成这个值,随便瞎写的。把linger.ms设置成了20000,即20秒发送一批数据。生产者通过循环产生数据。
运行的时候,产生了令人费解的一幕。生产者生产数据的速度非常慢,几秒钟,才会进入下一次循环。
然后经过了多次测试发现了更神奇的现象。当消息的key值设置为null或动态变化时,生产消息的速率非常慢。而当把消息的key值设置成固定的时,生产消息的速率又恢复了正常。并且,把batch.size的值设置小一些的时候(4096),生产速率也是正常的。
由上面的现象可知。batch.size设置很大,会影响生产者的效率,具体为什么影响,不得而知,需要追溯源码。 而batch.size设置很大时,效率也跟消息的key值有关系。key值固定不变时,效率快的原因猜测是因为不用进行分区的负载计算,只是一个往一个分区发,所以快。而key是null或者动态变化时,效率慢的原因猜测是因为需要计算不同key值的分区负载,所以影响了效率。那为什么当batch.size值小的时候,不会受key值的影响呢?这就说明batch.size和key值之间,有相互关系,但是还不是完全的影响关系。
带着上面的猜想和疑问,我们来看producer的源码。问题的根本,都集中在了producer的send方法里,所以,我们看send方法的源码。
这里,我们看源码的目的是找到为什么生产效率慢。所以,我采用了断点的方式,来定位到底是哪块代码,影响了速率。下面记录一下寻找过程。
由send方法经过一顿点入,进入了doSend方法,经过一番分析,初步猜测,是这个方法影响了效率,如下:
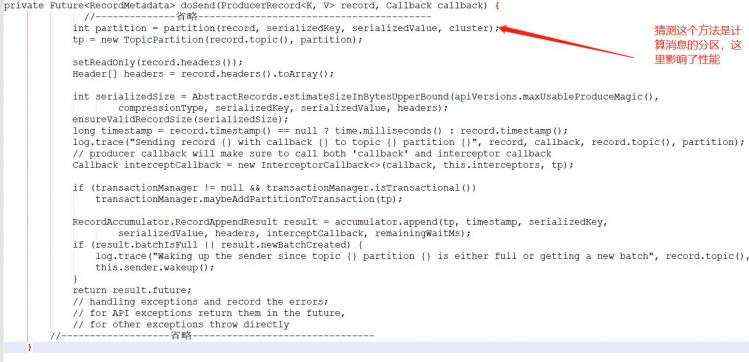
然后就在这里打个断点,然后再在它的下一行打个断点,用断点法验证是不是这里影响了性能。通过测试发现,从这个方法到下一个方法断点走的速度很快。而下一个断点到返回的send方法的时间,反而很慢。这就说明,我们猜测的这个断点,不是影响效率的地方。而是在这个断点的后面,某段代码,影响了效率。
索性把后面的代码,每行都打上断点,来测试到底哪行代码性能慢,如下图所示:

然后继续采用断点发,一个断点一个断点走,看哪个断点执行时间长。最终,发现是这个代码执行时间长:
 我们点进去这个方法,可以继续采用断点发一个一个排查哪个代码影响了性能,也可以大体看一遍方法,猜测一下可能哪里影响性能,缩小定位范围,最终,定位到是这里影响了性能:
我们点进去这个方法,可以继续采用断点发一个一个排查哪个代码影响了性能,也可以大体看一遍方法,猜测一下可能哪里影响性能,缩小定位范围,最终,定位到是这里影响了性能:

这个方法就是最终的原因所在,我们把其全部代码贴出来:
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
this.lock.lock();
try {
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
int freeListSize = freeSize() * this.poolableSize;
if (this.nonPooledAvailableMemory + freeListSize >= size) {
freeUp(size);
this.nonPooledAvailableMemory -= size;
} else {
int accumulated = 0;
Condition moreMemory = this.lock.newCondition();
try {
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);
while (accumulated < size) {
long startWaitNs &#61; time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
waitingTimeElapsed &#61; !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs &#61; time.nanoseconds();
timeNs &#61; Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
if (waitingTimeElapsed) {
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " &#43; maxTimeToBlockMs &#43; " ms.");
}
remainingTimeToBlockNs -&#61; timeNs;
if (accumulated &#61;&#61; 0 && size &#61;&#61; this.poolableSize && !this.free.isEmpty()) {
buffer &#61; this.free.pollFirst();
accumulated &#61; size;
} else {
freeUp(size - accumulated);
int got &#61; (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -&#61; got;
accumulated &#43;&#61; got;
}
}
accumulated &#61; 0;
} finally {
this.nonPooledAvailableMemory &#43;&#61; accumulated;
this.waiters.remove(moreMemory);
}
}
} finally {
try {
if (!(this.nonPooledAvailableMemory &#61;&#61; 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
lock.unlock();
}
}
if (buffer &#61;&#61; null)
return safeAllocateByteBuffer(size);
else
return buffer;
}
结合注释看代码&#xff0c;可以得知&#xff0c;核心原因如下图:

当超出size时&#xff0c;会进入阻塞&#xff0c;这就解释了为什么batch.size很大时&#xff0c;效率反而慢了。
那么还有一个疑问没解决&#xff0c;为什么key值设置成固定值时&#xff0c;效率很快呢&#xff0c;它没有阻塞吗&#xff1f;
通过断点可知&#xff0c;当key值固定时&#xff0c;代码没走进阻塞方法&#xff0c;它走了其他分支&#xff0c;所以效率很快&#xff0c;如下图:

总结
batch.size的值需要合理设置&#xff0c;否则会进入阻塞&#xff0c;效率很慢。




 京公网安备 11010802041100号
京公网安备 11010802041100号