😊昨天我们学习了数据库的DML语言,主要包括数据的导入、导出和查询,💘有兴趣的小伙伴可以看看👇:
- 第一篇: Hadoop之Hive数据的导入与导出(DML).
- 第二篇: Hadoop之Hive查询语句.
🐶今天我们来继续学习Hive的Join部分。听说Join有7种哦!
目录:
- 1.内连接
- 2.左外连接
- 3.右外连接
- 4.全外连接
- 5.差值
- 6.左右表独有
- 参考资料
1.内连接
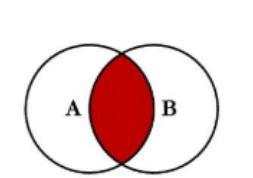
Hive支持通常的SQL JOIN语句,等值连接是将两张表中的相同字段信息连接起来
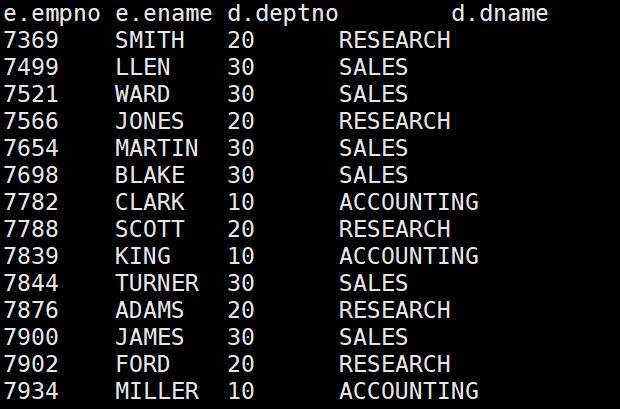
- 根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
select e.empno, e.ename, d.deptno, d.dname
from emp e join dept d
on e.deptno=d.deptno;
2.左外连接
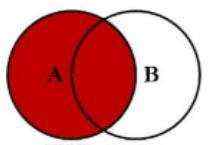
左外连接会将左表的数据全部展示,没有连接的部分将会补null值
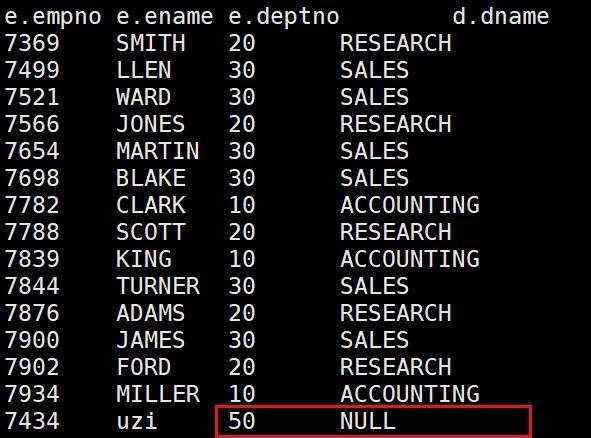
- 根据员工表和部门表中的部门编号相等,查询员工编号、员工名称、部门编号和部门名称;如果没有则用null补充
select e.empno,e.ename,e.deptno,d.dname
from emp e left join dept d
on e.deptno=d.deptno;
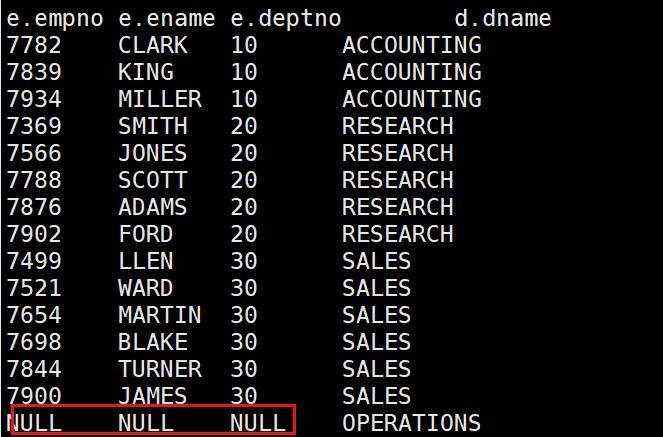
3.右外连接
select e.empno,e.ename,e.deptno,d.dname
from emp e right join dept d
on e.deptno=d.deptno;
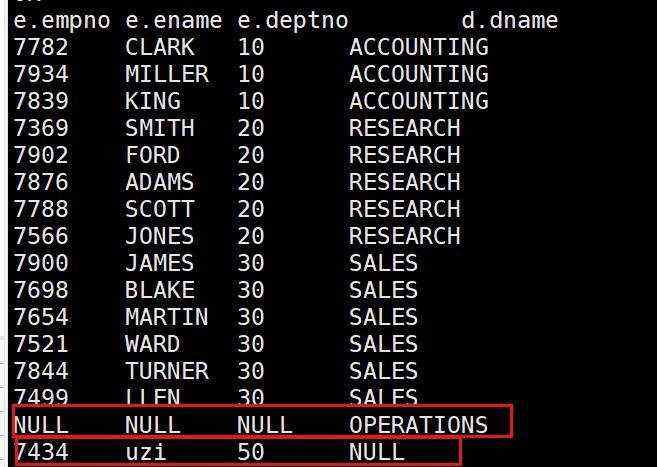
4.全外连接
select e.empno,e.ename,e.deptno,d.dname
from emp e full join dept d
on e.deptno=d.deptno;
5.差值
5.1 左表独有
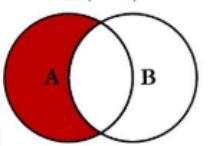
这里的差值就是A左连接B的结果在减去A和B的交集。
select e.empno,e.ename,e.deptno,d.dname
from emp e left join dept d
on e.deptno=d.deptno
where d.deptno is null;

我们也可以采用子查询,不过效率太低了
select e.empno,e.ename,e.deptno,d.dname
from emp e
where e.deptno not in (select deptno from dept);
5.2右表独有
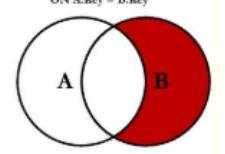
select d.deptno,d.dname
from emp e right join dept d
on e.deptno=d.deptno
where e.deptno is null;

6.左右表独有
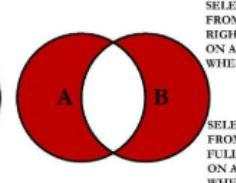
select e.empno,e.ename,e.deptno,d.dname
from emp e full join dept d
on e.deptno=d.deptno
where e.deptno is null or d.deptno is null;

也可以使用左右差值的结果做并集
select * from(
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp e left join dept d
on e.deptno=d.deptno
where d.deptno is null
union
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp e right join dept d
on e.deptno=d.deptno
where e.deptno is null)tmp;

8.多表连接
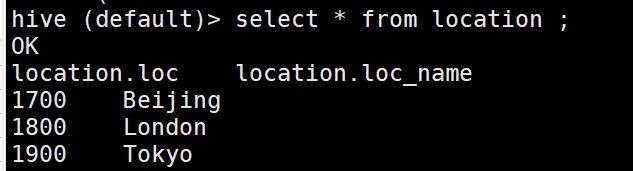
我们准备添加一个表的数据
1700 Beijing
1800 London
1900 Tokyo
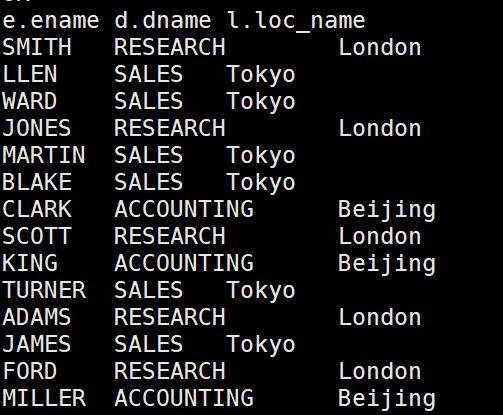
- 查询员工姓名,部门名称和部门所在城市名称
select e.ename,d.dname,l.loc_name
from emp e join dept d on e.deptno=d.deptno
join location l on d.loc=l.loc;
优化:当对 3 个或者更多表进行 join 连接时,如果每个 on 子句都使用相同的连接键的话,那么只会产生一个 MapReduce job
9.笛卡尔积
笛卡尔积会在什么情况下产生呢?
案例:
select empno,dname from emp,dept;
结果如下:
参考资料
《大数据Hadoop3.X分布式处理实战》









 京公网安备 11010802041100号
京公网安备 11010802041100号