一、什么是ELK?
通俗来讲,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组 成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称 为 ELK stack,官方域名为 stactic.co,ELK stack 的主要优点有如下几个:
- 处理方式灵活: elasticsearch 是实时全文索引,具有强大的搜索功能
- 配置相对简单:elasticsearch 全部使用 JSON 接口,logstash 使用模块配置, kibana 的配置文件部分更简单。
- 检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百 亿级数据的查询秒级响应。
- 集群线性扩展:elasticsearch 和 logstash 都可以灵活线性扩展 前端操作绚丽:kibana 的前端设计比较绚丽,而且操作简单
1.什么是Elasticsearch?
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索 搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比 如 nginx、Tomcat、系统日志等功能。

2.什么是 Logstash?
可以通过插件实现日志收集和转发,支持日志过滤,支持普通 log、自定义 json格式的日志解析。

3.什么是kibana?
主要是通过接口调用 elasticsearch 的数据,并进行前端数据可视化的展现。

二、Elasticsearch 部署
ELK使用场景:
日志平台:利用elasticsearch的快速检索功能,在大量的数据当中可以快速查询需要的日志。
订单平台:利用elasticsearch的快速检索功能,在大量的订单当中检索我们所需要的订单。
搜索平台:利用elasticsearch的快速检索功能,在大量的数据中检索出我们所需要的数据。
1.部署
一般部署elasticsearch有三种方式:
- rpm包安装
- 源码包安装
- docker安装
官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
官网其他版本安装包下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
2.rpm包安装
1)集群规划
2)集群配置
官方推荐集群配置30G。本地使用2核2G
3)系统优化 (两台节点)
[root@es-01 ~]
[root@es-01 ~]
[root@es-01 ~]
[root@es-01 ~]
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
reboot
4)下载安装包 (两台节点)
[root@es-01 ~]
[root@es-02 ~]
5)安装 (两台节点)
[root@es-01 ~]
[root@es-01 ~]
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
[root@es-01 ~]
6)elastcsearch设置内存锁定(两台节点)
[root@es-01 ~]
LimitAS=infinity
LimitMEMLOCK=infinity
[root@es-01 ~]
7)修改elasticsearch锁定内存大小
[root@es-01 ~]
-Xms1g
-Xmx1g
8)修改elasticsearch的配置文件
[root@es-01 ~]
[root@es-01 ~]
cluster.name: elaina-es
node.name: elaina-node-01
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["172.16.1.20"]
[root@es-01 ~]
cluster.name: elaina-es
node.name: elaina-node-02
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["172.16.1.21"]
9)启动
[root@es-01 ~]

3.源码包安装
[root@es-01 ~]
[root@es-01 ~]
[root@es-01 /opt]
[root@es-01 ~]
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
[root@es-01 /opt]
4.docker安装 (主节点安装)
docker run -p 9200:9200 -p 9300:9300 -e "cluster.name=xxx" docker.elastic.co/elasticsearch/elasticsearch:7.12.1
5.安装集群head插件 (主节点安装)
head插件主要是图形化elastic search
1)安装docker (主节点安装)
yum remove docker docker-common docker-selinux docker-engine -y
sudo yum install -y gcc gcc-c++ yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum clean all
yum makecache
yum install docker-ce -y
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-&#39;EOF&#39;
{
"registry-mirrors": ["https://xj6uu5rz.mirror.aliyuncs.com"]
}
EOF
systemctl start --now docker
2&#xff09;拉取镜像并后台运行 (主节点)
[root&#64;es-01 ~]
e9c8f62358c1ddae141ab4eff64d19d3cce1b4944a4ed75d4907541f6a0f33e6
2&#xff09;设置elasticsearch跨域访问 &#xff08;两节点&#xff09;
[root&#64;es-01 ~]
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
[root&#64;es-01 ~]

6.部署elasticsearch主从
elasticsearch是主从数据节点分离的&#xff0c;按照节点还可以分为热数据节点和冷数据节点。
1&#xff09;部署主节点
参考上述4、5.主节点操作
[root&#64;es-01 ~]
cluster.initial_master_nodes: ["172.16.1.20"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["172.16.1.20","172.16.1.21"]
node.master: true
[root&#64;es-01 ~]
2&#xff09;部署从节点
从节点系统优化与主节点一样
[root&#64;es-02 ~]
cluster.initial_master_nodes: ["172.16.1.20"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: ["172.16.1.20","172.16.1.21"]
node.master: false
[root&#64;es-02 ~]

做到这一步极其容易出现数据不一致的问题&#xff0c;反应到登录网页上就上明明好像能正常访问&#xff0c;其实它的的UUID是错误的。为此可以先删除/var/lib/elasticsearch/*下面的东西&#xff0c;然后再重启elasticsearch。这样就可以了。
[root&#64;es-02 ~]
[root&#64;es-02 ~]
[root&#64;es-02 ~]
[root&#64;es-02 ~]
三、测试集群性能
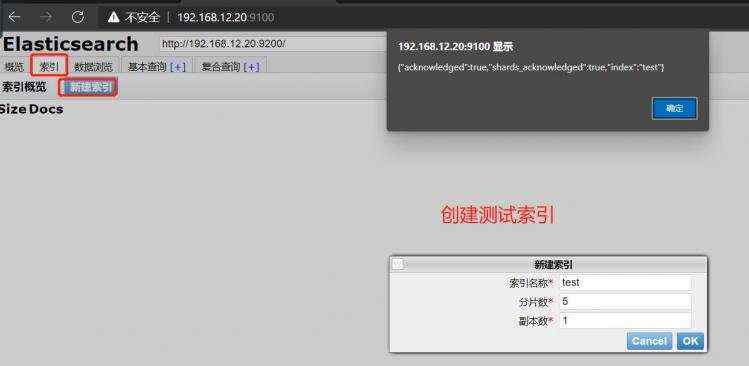
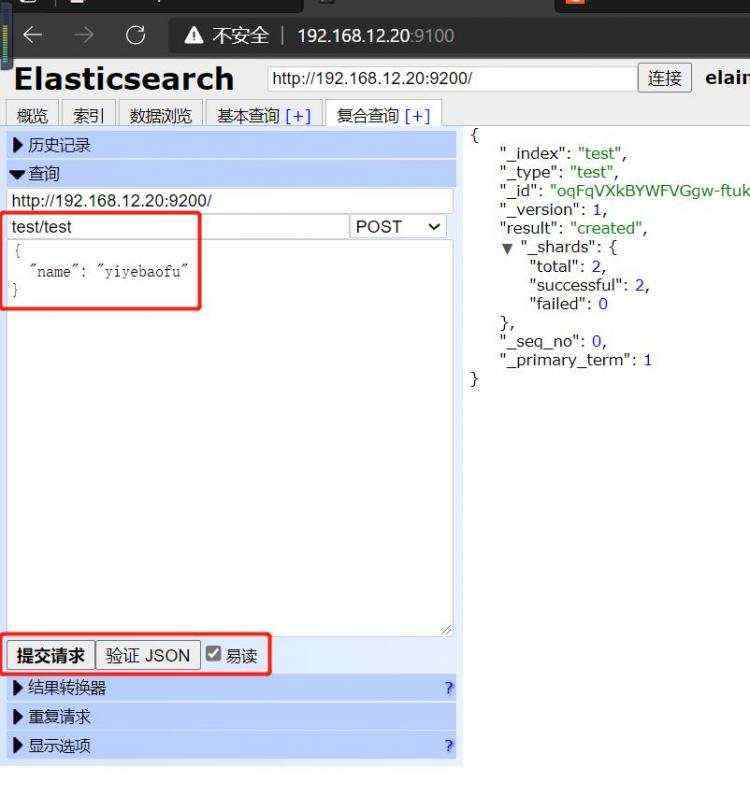
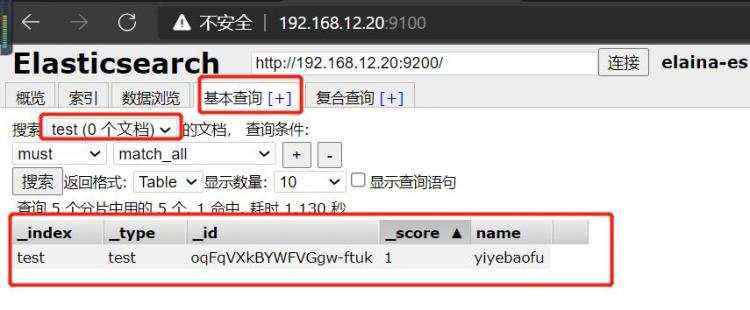
1.elasticsearch监控
通过浏览器访问:http://192.168.15.20:9200/_cluster/health?pretty&#61;true, 例如对 status 进行分析&#xff0c;如果等于green(绿色)就是运行在正常&#xff0c;等于yellow(黄色)表示副本分片丢失&#xff0c;red(红色)表示主分片丢失。










 京公网安备 11010802041100号
京公网安备 11010802041100号