产品人都知道不要销售你能制造的产品,而是制造你能卖出去的产品。而弄清楚能卖出去的产品核心就是知道究竟人们想买什么。可是有时候用户自己也不知道自己需要什么。这个时候数据分析和快速迭代的能力就显得给重要,也避免了决策着由于个人的偏见影响了产品的判断。
所以皮尔森定律称,可衡量才有促进。你要找到你的第一关键指标以及如何划出底线,以帮助你快速前进,合适应该猛踩刹车。
但是有时候你也许会发现,同一批数据,不同的人分析后得出的结论完全不一样。因此,除了获得正确的数据,还要避免常见的数据误区。今天我要跟你说说有哪些常见的数据误区。

每个版本发布后,我们必须要做的数据工作就是对比分析新旧版本的数据情况,以判断新版本的改进是否更契合用户需求。如果直接提取两个版本的全量用户数据进行分析,绝大多数情况下我们会发现新版数据总是比旧版好。但事实是,直接对比全量数据的分析方法是错误的。因为新旧两个版本的用户群性质存在较大差异:
一般来说,对产品旧版本比较满意、相对活跃的那部分用户更愿意升级到新版本,而那些对产品不怎么满意的用户很多都流失了,自然也不会升级新版本进入新版用户池里。这就导致新旧版本数据池中有差异的两个群体一个是中性用户——首次下载产品的新用户,另一个却是负评价用户——旧版未升级到新版的用户。这样做对比分析得到的结论自然比真实情况乐观许多。
总结一下,凡对比必须控制变量,同基线的对比才有意义。
我们看数据的时候一定要对平均数提高警惕,因为它导出的结论常会掩盖一些重要的真相。其中最常见的误区有两种:
混淆不同级别的用户;忽视用户分布状况。
不同用户对产品的意义是不一样的。如果我们不对用户分级,混淆起来看总体的用户数据指标、看平均数,那么我们既不能看到真正的问题在哪儿,也无法知道真正的增长来自哪儿。
举个例子,一个视频类应用分析它缓冲超时与用户跳出率之间的关系。分析发现不管平均超时有多么严重,用户的跳出率都很低。从平均数据看用户似乎对缓冲超时并不在意。但当进一步分析数据才发现,原来有95%的用户是免费用户,这些用户不管超时多严重跳出率都很低,而另外5%的付费用户其实对超时很敏感,当超时严重时付费用户的跳出率明显上升。但由于付费用户在总用户中占比太低,这种状况就被总体平均数给掩盖掉了。如果产品负责人只看总平均数,他将看不出任何问题。
所以我们在分析产品数据时——尤其是电商类、游戏类、增值服务类等产品类型,一定要对产品的用户群进行分级。只要涉及“平均”指标的数据,都尽量到同级别用户里去做统计。比如平均访问时长、平均客单价、平均消费频次等,全部分开统计。
这样统计的好处是产品将越来越了解它的用户行为及构成,还可以对不同类型的用户提供差异性的功能设计。这在经济学里可以看作一种价格歧视,歧视不是带有色眼光的偏见,而是对用户进行差异化管理,有利于产品设计者更好地满足用户需求,助力产品健康成长。
另一个平均数的误区是:我们在谈论平均数据时总会下意识地忽略用户的分布状况。比如,当听到一个描述说"这个页面的日平均浏览量高达200万"时,你的直觉反应是什么?深谙数据分析之道的运营者一定会继续追问"这个数据的具体分布情况如何"。因为他们脑海中会立刻反射两张不同的图像出来: 均值相等的正态与长尾分布图
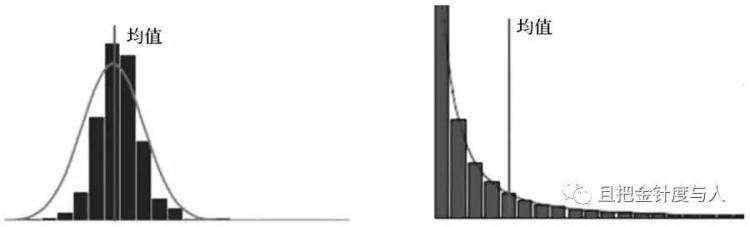
可见,左右两图的均值相等但用户分布完全不同。当数据呈左图的正态分布时,均值可以大致上代表整体情况,但当数据呈右图的长尾分布时则不然。遭遇这类情况时,我们最好截取数据最密集的一段进行分析,进而导出更具指导意义的结论。
与平均数类似,数据中另一个值得警惕的概念是占比,一个高占比在没有样本总量做参考的前提下很容易误导人。记住一条原则准没错:
谈平均不谈分布,谈比例不谈总量,都是耍流氓。
在产品成长阶段,我们会借助内外部不同渠道进行产品推广。内部渠道包括好友分享、赠券优惠等,外部渠道则包括各大应用市场、网站联盟、邮件短信营销、资源互换、SEM 、线下地推等等。这么多渠道每个都对应着推广成本,运营者常通过评估渠道价值来制定渠道的推广策略。
假设现在有两个渠道,渠道A和渠道B。它们的渠道引流能力如下:
A为产品带来50000个激活用户,1个用户成本10元;B为产品带来20000个激活用户,1个用户成本20元。
直接从渠道用户数量和单用户获取成本来看,A渠道量大成本低,显然优于B渠道。如果我们对渠道的价值评估仅止于此,就落入了价值误判的陷阱。
用户激活使用只能代表他们走进了产品,但这些用户是如何使用产品的?他们对产品感兴趣吗?愿意长久用下去吗?愿意付费吗?愿意向朋友推荐吗?所有这些问题我们都还不清楚,这批用户对我们来说还只是未知的黑盒。这样评估出来的渠道价值毫无意义。
没错,激活只是用户行为深度模型AA RRR的第二个层级。当我们评估一个渠道的价值时,本质上是要看这个渠道为我们带来的用户到底是谁,他们和产品契合度如何,在产品的哪一个层级上。即使都是付费用户,付费频率和平均客单价不同的用户对产品的价值也是不同的。
所以回到渠道A和B的比较上,按照A ARRR的路径依次向下追踪分析,看50000个和20000个激活用户最终走到付费阶段的有多少,走到推荐阶段的又有多少,再反向核算单个用户的成本才能做出正确评断。例如在这个案例分析下来,最后情况很可能是这样的:
A激活50000个,留存10000个,付费2000个,推荐1400个;B激活20000个,留存10000个,付费6000个,推荐4500个。
反向核算1个用户的成本:
A渠道1个用户的激活成本10元,留存成本50元,付费成本250元,推荐成本357元;B渠道1个用户的激活成本20元,留存成本40元,付费成本66元,推荐成本89元。
综合评价后结果显示:B渠道的用户质量反而高于A渠道。不过还有一点需要留意:分析渠道价值时,最好对比同期渠道数据。这一点我们在对比分析里已经提到过。渠道来源并非影响用户转化的唯一要素,不同时期不同版本,各环节运营手段总有不同,如果还是采用逆推判断不同时期的渠道付费成本显然不太合理。
最后总结一下渠道误判留给我们的教训:有多大流量不重要,重要的是产品最终能沉淀下多大的流量。
辛普森悖论(Simpson's Paradox),它是比例的另一种误区。描述的是某个条件下的两组数据,分别讨论时都会满足某种性质,可是一旦合并考虑,却可能导致完全相反的结论。
在我们的数据分析工作中,有时也会落入辛普森悖论的陷阱。比如,在统计付费用户的占比时,常有类似下表的状况发生:

总体看,小程序的付费率低于公众号,但实际上当我们进一步分解去看,无论是Android平台还是iOS平台,小程序的付费率都要高于公众号的付费率。
为了避免辛普森悖论出现,常规的解决方案建议分析者斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响,同时了解分析情境下是否存在其他潜在因素。在实际的产品分析工作中,不妨简单粗暴地记住:不仅谈比例不谈总量是耍流氓,谈比例不看细节也是耍流氓。
从系统思考的角度来看,避免局部优化,局部虽然有优势,但是放在系统发展的大图里,可能会产生误判。
避免了以上几个数据误区,在此基础上进行不断的"构建-衡量-学习",这个循环越快,越能很快的找到产品的问题和市场。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有