
向AI转型的程序员都关注了这个号????????????
机器学习AI算法工程 公众号:datayx
由于市面上的文本标注工具无法满足实际项目的标注场景需求,因此本项目自主开发了基于web的文本标注工具用于构建高质量的语料库。该工具需要支持实体标注、关系标注、事件抽取、文本分类等基础标注功能,要求标注规范可自定义,文本可迭代标注,适用于大规模实体类型的标注任务,可拓展嵌套实体标注、标准名标注和基于字典匹配和正则匹配的预标注功能。在满足标注功能的前提下,尽可能优化标注体验,减少用户的工作量和成本消耗,同时保证标注结果的准确性。标注工具需满足在主流操作系统Windows、Linux和Mac上正常运行。
技术难点
(1).最基础的实体标注功能需要实时可视化显示每次的标注结果,每次标注时需要支持可选择大量实体类型。
(2).两个实体之间的关系标注实现方式,多个实体之间的事件抽取实现方式。
(3).嵌套实体标注的实时可视化展示。
(4).文本支持迭代标注中,对已标注文本的标注内容识别导入数据库。
(5).基于正则匹配和字典匹配的自动标注的结果缓存与显示,以及结果的确认并导入数据库。
(6).优化用户标注体验、提高标注效率。
(7).为了提高标注结果的正确率,增设审核环节。
(8).允许在多种系统环境上部署运行。
MarkTool 基于web的通用文本标注工具
华东理工大学-自然语言处理与医疗大数据实验室
项目代码 获取:
关注微信公众号 datayx 然后回复 文本标注 即可获取。
AI项目体验地址 https://loveai.tech
完整版特性:
高效的标注方式:它对每个实体的标注不需要鼠标的多次点击或者大范围移动,并且支持实体嵌套标注、文本迭代标注和基于预标注功能的半自动标注方式。
强大的标注功能:它支持多种类型的标注任务,包括命名实体识别的实体标注、两个实体之间的关系标注、多个实体集合的事件抽取、文本分类、归一化任务的标准名标注以及通过字典匹配和正则匹配实现的自动标注功能。
优雅的标注界面:它通过创建实体分级的标注规范可以保证在使用大规模的实体类型的同时避免标注界面中实体选择栏的爆炸显示。此外,它还具有实体统计模块,可以直观地显示已标注的实体类型及其数量。当你将鼠标箭头在文本中所标注的实体上悬浮1秒就会显示该实体所对应的的实体类型,这一设计非常方便用户进行回顾和检查已标注实体。
通用的标注平台:它支持对所有序列文本的标注,具有语言无关性和领域无关性,现已在多个领域包括军工、医疗和公共治安领域投入应用。
独特的质检模式:它支持多人协同标注(默认为2人)。尽管有详细的标注规范和规则说明,但是由于人为的错误、标注规则未涵盖的语言现象以及词语本身的歧义,标注者之间的分歧仍不能完全避免,因此对标注结果的质检就显得不可或缺。MarkTool通过添加审核阶段对多个标注者的标注结果进行一致性检验和微调,从而提高标注结果的正确率和可靠性。
便捷的获取途径:它不依赖于特定的操作系统,只需要导入docker镜像,并在工作目录下输入命令docker-compose up启动服务,即可在浏览器进行标注工作。
标注的总框架
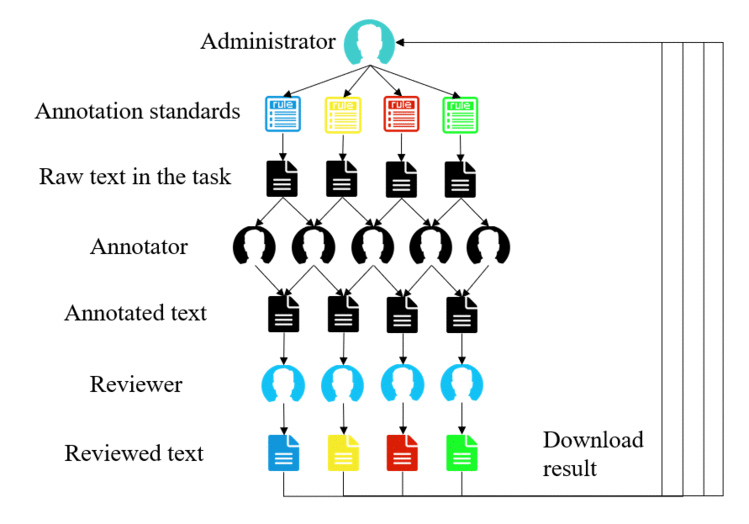
首先,管理员需要创建所需的标注规范。如果所需的标注规范已存在则可以直接创建标注任务,否则管理员需要新建该标注规范。
其次,管理员可以根据实际需求创建多个不同类型的标注任务,每个任务对应一种标注规范,填写任务的基本信息并上传相关文件(待标注的原文件filename.txt是必须的),选择该任务所要分配的标注者(默认2个)和审核者(默认1个)即可完成任务的创建。
再次,标注者可以查看自己所分配到的任务并进行相应的标注。当一个任务的所有标注者都完成标注并点击提交之后,该任务的审核者就会看到系统自动合并之后的标注结果并进行审核。在审核环节中,审核者可以对已标注的内容进行调整从而得到最终的标注结果。
最后,管理员可以在任务总览页面中下载标注结果(json格式的文件)。
解决方案及效果展示
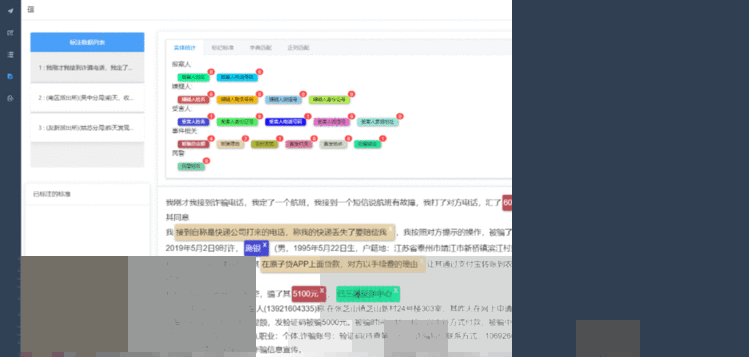
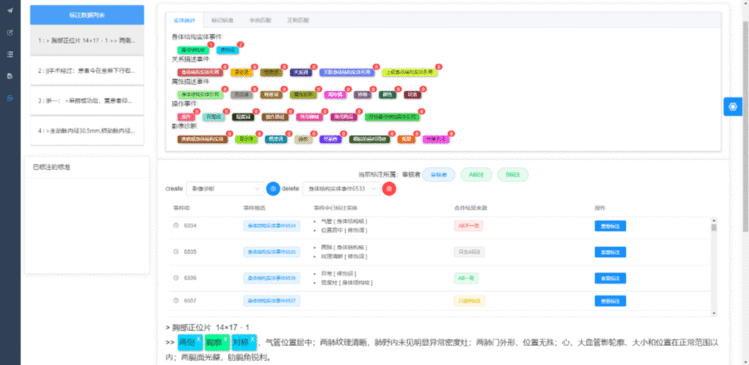
前端采用VUE框架实现数据与视图绑定,可实时将后端传过来的实体标注的结果进行可视化显示,用户能够在文本上看到每个实体的颜色、类型(及其标准名),并且进行标注数量的实时统计,在实体统计区域显示每种实体类型的已标注数量,其效果如图1所示。
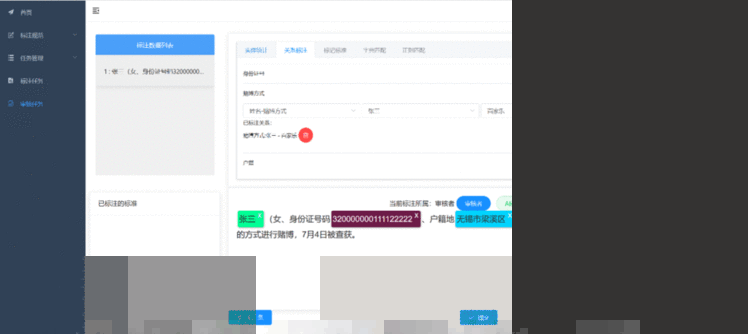
为了能够满足大规模实体类型的标注任务需求,该工具设计了一种全新的分级实体选择方式,通过二级实体将可选的实体类型总数从原有的n种大大提高到n2种,并且第一次和第二次都只需要浏览n种选择即可。在每次的实体标注中用户不需要多次点击鼠标和大范围移动,在数千上万的标注工作中极大地提升了用户的工作效率。其效果如图2所示。

关系标注的核心是在已标注的实体集上进行一一映射,因此该工具在关注标注模块中设计为第一步选择前实体,第二步选择后实体、第三步确定这二者之间的关系名,其效果如图3所示。
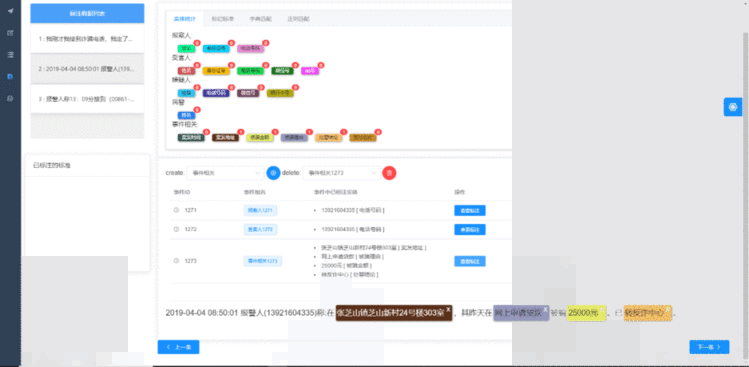
事件抽取的本质是多个实体的集合,因此该工具在事件标注任务中通过先建立相应的事件标注规范对需要抽取的事件组类型以及事件组的实体构成再选择添加某个事件组类型并进行事件组内部实体的标注。在事件统计列表中可以看到每个已标注事件的具体标注情况,包括每个实体的内容和类型,并且通过点击“查看标注”按钮可以切换对不同事件的查阅与修改。事件标注的示例图如图4所示。
嵌套实体标注首先记录每个实体的始末位置以及实体内容、实体颜色,通过对不同实体的位置进行计算,在长实体的基础上将短实体的所在的位置进行显示覆盖,如果删除该实体则需要将文本该始末位置之间的显示内容进行还原。嵌套实体标注的示例图如图5所示。
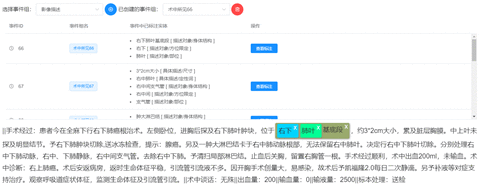
迭代标注时首先需要保证已标注的文本(答案文件)的传入顺序与之间首次标注时传入的顺序相同,利用python的pickle 模块将答案文件的标注内容反序列化,并将结果存入数据库中以实现再标注。创建任务时要在步骤6中按序上传对应的答案文件,如图6所示。

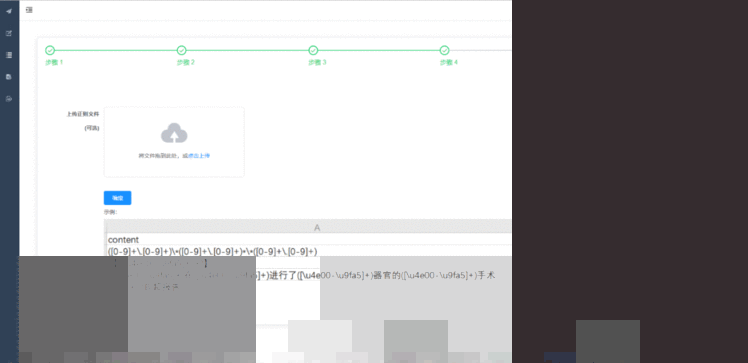
基于正则匹配和字典匹配的自动标注需要对标注临时结果进行可视化显示,并且允许在浏览完临时结果后选择不保存。因此需要前端进行缓存结果并显示,但是不传入后端数据库,只有在用户点击确认保存之后才会将结果存入后端数据库。进行正则匹配和字典匹配之前可以选择上传相应的字典文件和正则文件。创建任务时可在步骤3中上传对应的字典文件,如图7所示;可在步骤4中上传对应的正则文件,如图8所示。如果在创建任务时选择不上传相应的字典文件和正则文件也可以在后续的标注过程中逐条添加所需的字典和正则规则。
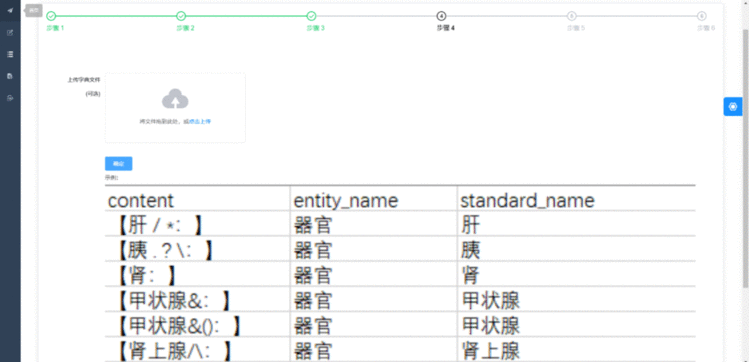
该工具还支持实体的标准名标注,如图9所示。用户可以通过上传标准文件或者在标注过程中选择管理标准名称进行添加

为了提高标注效率,在系统设计中允许自定义的标注规范可复用,实现“一次建立多次复用”的目标,极大地减少了用户在同类型标注任务中对标注规范的反复创建。标注规范的示例如图10所示
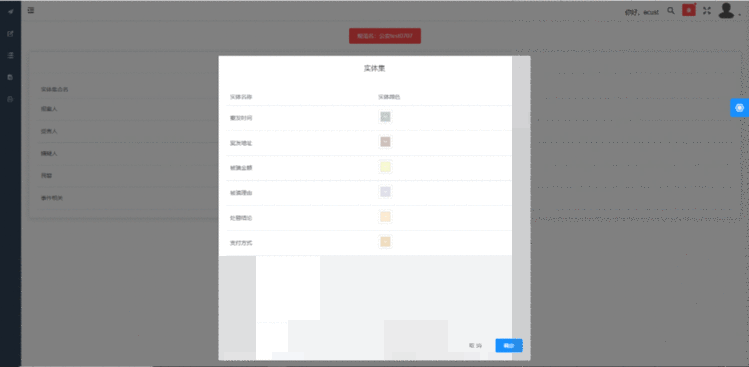
该系统还设计了审核环节用以保证标注结果的准确率与可靠性。审核环节中会对标注者的标注结果进行一致性检验,对于通过检验的文本会对标注结果进行合并,并显示合并结果来源,同时还支持切换查看不同角色的标注结果,帮助审核者快速分析与调整,其页面效果如图11所示。
该工具采用docker镜像进行部署,只需系统上有docker环境即可一键导入工具的镜像,无需复杂的配置步骤和系统操作,对操作系统类型没有限制,即使在不联网的环境也能正常使用。导入镜像并在工作目录下执行命令docker-compose up启动本地服务即可访问浏览器地址 http://127.0.0.1:18080/ 进行标注。
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

机大数据技术与机器学习工程
搜索公众号添加: datanlp

长按图片,识别二维码









 京公网安备 11010802041100号
京公网安备 11010802041100号