打开软件后界面如下:

点击打开文件按钮打开之前的PDF文件后效果如下:
框选区域后,标题栏会自动显示当前框选的区域提取到的文字,还可以左右按钮切换:

实际我们需要提取文字的区域可能不止这一个,所以程序支持多区域框选:

完成区域框选后就可以点击保存文件,将PDF每页提取到的文本保存到一个csv文件中,当前选区的保存结果如下:

可以看到已经按框选顺序依次保存了每一个区域的字符串。
如果选择区域时发现提取结果不准确,可以撤销后重新选择:
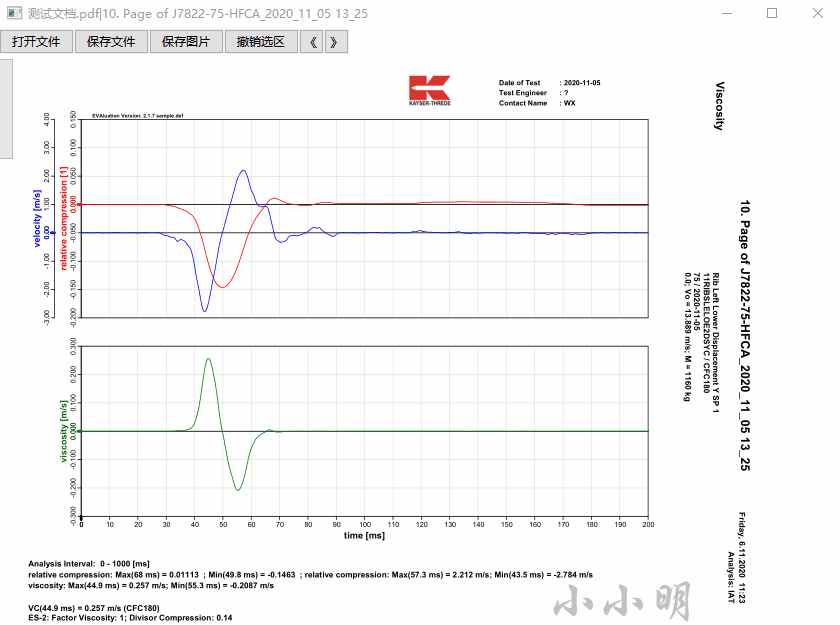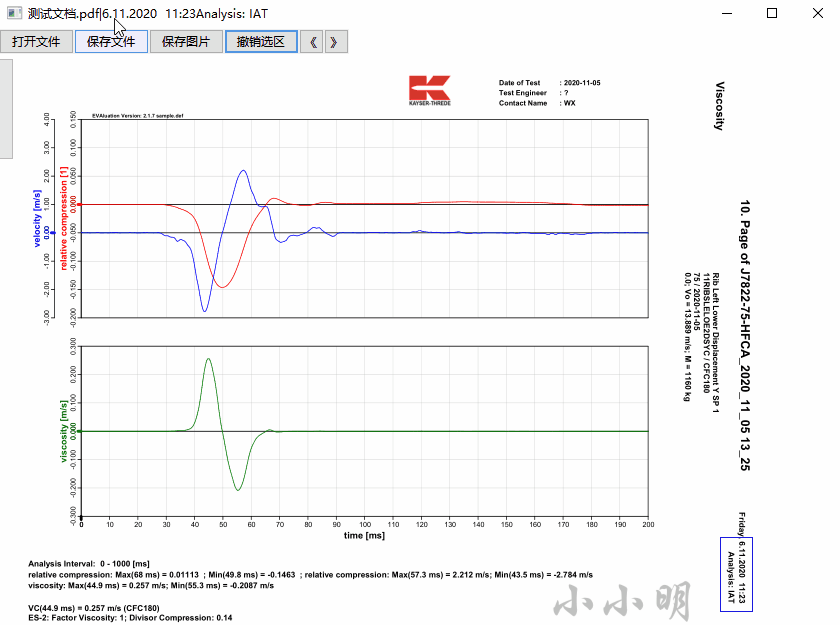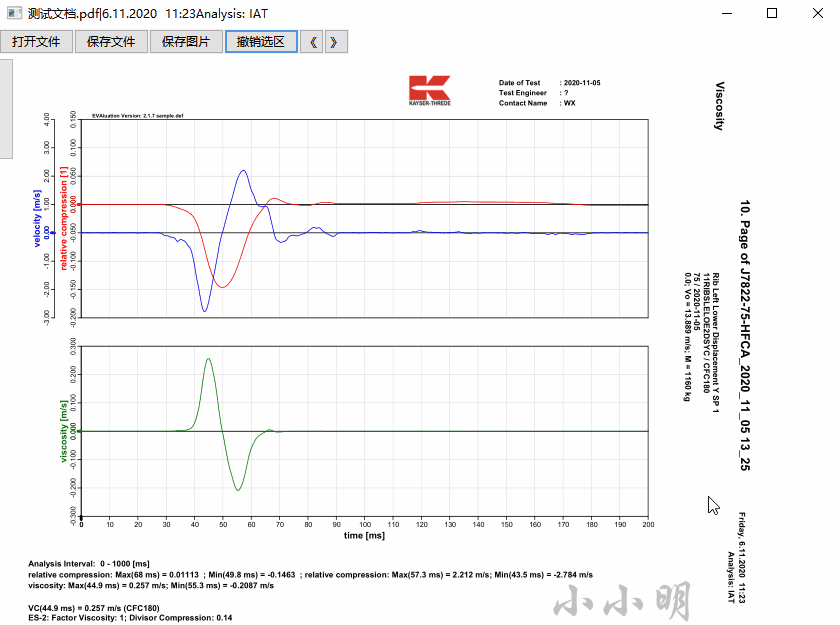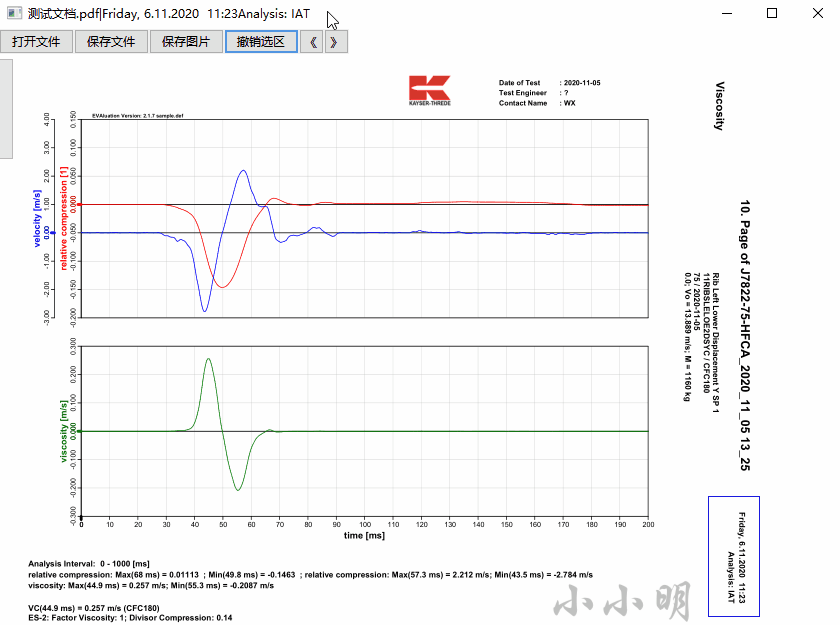
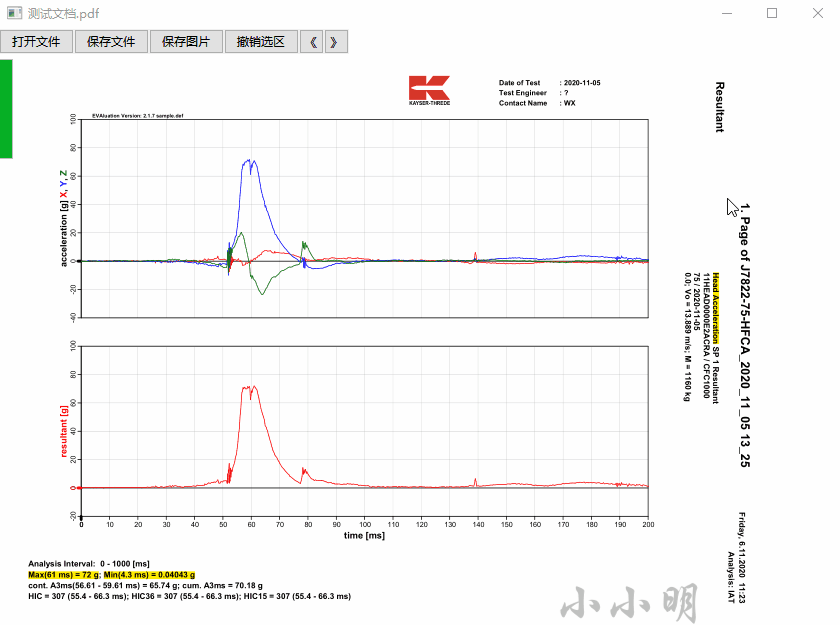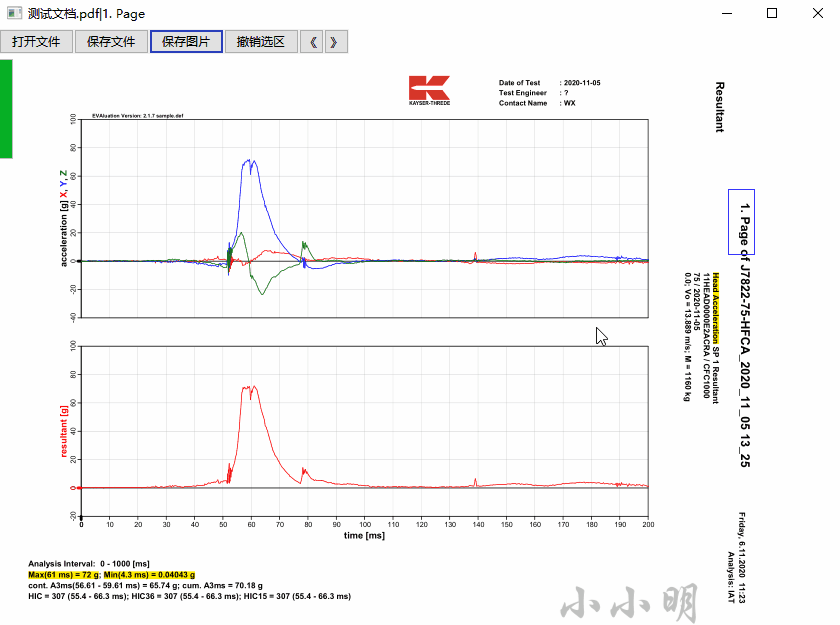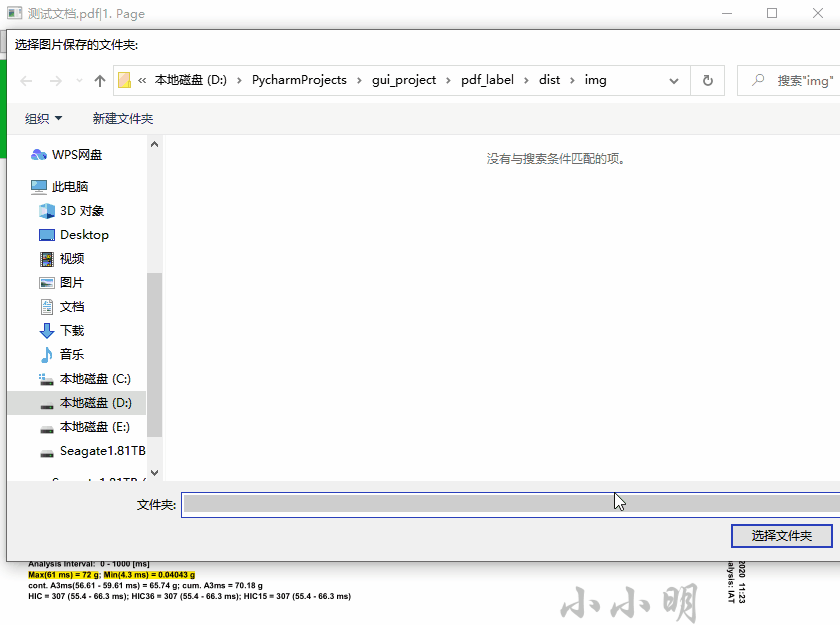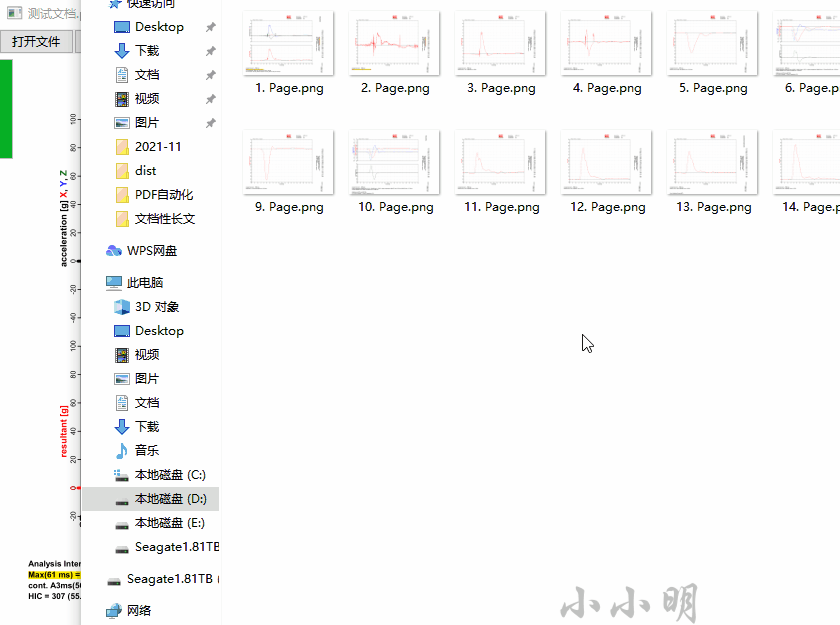
保存图片则会将PDF的每页的整体保存为一张图片,未选择区域时,以页码为文件名保存图片:

选择区域时,会自动提取最后一个区域提取的文本作为当前页的文件名:
当然这个项目由于本人是一次使用wxpython,功能非常简约,现在将完整代码开源出来期待各位大佬的改进。
源码和已编译工具下载地址:
https://codechina.csdn.net/as604049322/python_gui
完整代码:
"""
小小明的代码
CSDN主页:https://blog.csdn.net/as604049322
"""
__author__ = '小小明'
__time__ = '2021/11/24'
import csv
import wx
import os
import fitz
class MyCanvas(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
self.parent = parent
self.rects = []
self.Bind(wx.EVT_LEFT_DOWN, self.OnLeftButtonEvent)
self.Bind(wx.EVT_LEFT_UP, self.OnLeftButtonEvent)
self.Bind(wx.EVT_MOTION, self.OnLeftButtonEvent)
self.Bind(wx.EVT_PAINT, self.DoDrawing)
b = wx.Button(self, -1, "打开文件", (0, 0))
self.Bind(wx.EVT_BUTTON, self.OnButton, b)
b = wx.Button(self, -1, "保存文件", (75, 0))
self.Bind(wx.EVT_BUTTON, self.save_file, b)
b = wx.Button(self, -1, "保存图片", (150, 0))
self.Bind(wx.EVT_BUTTON, self.save_img, b)
b = wx.Button(self, -1, "撤销选区", (225, 0))
self.Bind(wx.EVT_BUTTON, self.back_select, b)
b = wx.Button(self, -1, "《", (300, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.previous, b)
b = wx.Button(self, -1, "》", (325, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.next, b)
self.g1 = wx.Gauge(self, -1, 100, (0, 30), (-1, 100), wx.GA_VERTICAL)
def previous(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i > 0:
self.i -= 1
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def next(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def back_select(self, evt):
if self.rects:
self.rects.pop()
self.DoDrawing(-1)
def OnButton(self, evt):
dlg = wx.FileDialog(
self, message="选择一个PDF文件",
defaultDir=os.getcwd(),
defaultFile="",
wildcard="PDF文件(*.pdf)|*.pdf",
wx.FD_CHANGE_DIR |
wx.FD_FILE_MUST_EXIST | wx.FD_PREVIEW
)
if dlg.ShowModal() == wx.ID_OK:
self.rects = []
path = dlg.GetPath()
self.pdfDoc = fitz.open(path)
self.i = 0
self.pageCount = self.pdfDoc.pageCount
self.change_pdf_page(self.i)
self.path = os.path.basename(path)
self.parent.SetTitle(self.path)
self.DoDrawing(-1)
dlg.Destroy()
def change_pdf_page(self, i, move=True):
page = self.pdfDoc[i]
rect = page.rect
print("pdf范围:", rect)
mat = fitz.Matrix(1, 1)
pix = page.get_pixmap(matrix=mat, alpha=False, clip=rect)
pix.save("tmp.png")
self.change_img("tmp.png", move)
def save_FileDialog(self, format="csv"):
dlg = wx.FileDialog(
self, message=f"保存一个{format}文件", defaultDir=os.getcwd(),
defaultFile="", wildcard=f"{format}文件(*.{format})|*.{format}", wx.FD_OVERWRITE_PROMPT
)
path = None
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
dlg.Destroy()
return path
def save_img(self, evt):
if not hasattr(self, "pdfDoc"):
return
dlg = wx.DirDialog(self, "选择图片保存的文件夹:",
wx.DD_DIR_MUST_EXIST
# | wx.DD_CHANGE_DIR
)
mat = fitz.Matrix(1, 1)
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
clip = page.rect
pix = page.get_pixmap(matrix=mat, alpha=False, clip=clip)
if self.rects:
name = self.extract_pdf_text(page=page, rect=self.rects[-1])
else:
name = f"p{i:0>3d}"
pix.save(f"{path}/{name}.png")
self.g1.SetValue((i + 1) * 100 // self.pdfDoc.pageCount)
dlg.Destroy()
os.system(f"explorer {path}")
def save_file(self, evt):
if not hasattr(self, "pdfDoc"):
return
path = self.save_FileDialog()
if path is None:
return
data = []
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
row = [self.extract_pdf_text(page, rect)
for i, rect in enumerate(self.rects)]
data.append(row)
with open(path, "w") as f:
writer = csv.writer(f, lineterminator="\n")
row = [f"区域{i}" for i in range(1, len(row) + 1)]
writer.writerow(row)
for row in data:
writer.writerow(row)
os.system(f"cmd /c start {path}")
def extract_pdf_text(self, page=None, rect=None):
if page is None:
page = self.pdfDoc[self.i]
if rect is None:
rect = self.rects[-1]
a, b, c, d = rect
clip = fitz.Rect(a, b, a + c, b + d)
text = page.get_text(clip=clip).strip()
return text
def change_img(self, img_path, move=True):
self.bmp = wx.Bitmap(img_path)
self.SetSize(self.bmp.GetSize())
self.parent.SetSize(self.parent.GetBestSize())
if move:
self.parent.Center()
def DoDrawing(self, evt):
if not hasattr(self, "bmp"):
return
dc = wx.ClientDC(self)
dc.DrawBitmap(self.bmp, 0, 0, True)
dc.SetPen(wx.Pen('blue'))
dc.SetBrush(wx.Brush('white', wx.BRUSHSTYLE_TRANSPARENT))
dc.DrawRectangleList(self.rects)
def OnLeftButtonEvent(self, event):
if event.LeftDown():
self.x, self.y = event.GetPosition()
self.rects.append([self.x, self.y, 0, 0])
elif event.Dragging():
x, y = event.GetPosition()
self.rects[-1][2] = x - self.x
self.rects[-1][3] = y - self.y
self.DoDrawing(-1)
elif event.LeftUp():
print(self.rects)
if self.rects[-1][2] <5 or self.rects[-1][3] <5:
self.rects.pop()
else:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
app = wx.App()
frm = wx.Frame(None)
pnl = MyCanvas(frm)
frm.Center()
frm.Show()
frm.SetTitle("PDF文本提取器")
app.MainLoop()
打开软件后界面如下:
点击打开文件按钮打开之前的PDF文件后效果如下:
框选区域后,标题栏会自动显示当前框选的区域提取到的文字,还可以左右按钮切换:
实际我们需要提取文字的区域可能不止这一个,所以程序支持多区域框选:
完成区域框选后就可以点击保存文件,将PDF每页提取到的文本保存到一个csv文件中,当前选区的保存结果如下:
可以看到已经按框选顺序依次保存了每一个区域的字符串。
如果选择区域时发现提取结果不准确,可以撤销后重新选择:
保存图片则会将PDF的每页的整体保存为一张图片,未选择区域时,以页码为文件名保存图片:
选择区域时,会自动提取最后一个区域提取的文本作为当前页的文件名:
当然这个项目由于本人是一次使用wxpython,功能非常简约,现在将完整代码开源出来期待各位大佬的改进。
源码和已编译工具下载地址:
https://codechina.csdn.net/as604049322/python_gui
完整代码:
"""
小小明的代码
CSDN主页:https://blog.csdn.net/as604049322
"""
__author__ = '小小明'
__time__ = '2021/11/24'
import csv
import wx
import os
import fitz
class MyCanvas(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
self.parent = parent
self.rects = []
self.Bind(wx.EVT_LEFT_DOWN, self.OnLeftButtonEvent)
self.Bind(wx.EVT_LEFT_UP, self.OnLeftButtonEvent)
self.Bind(wx.EVT_MOTION, self.OnLeftButtonEvent)
self.Bind(wx.EVT_PAINT, self.DoDrawing)
b = wx.Button(self, -1, "打开文件", (0, 0))
self.Bind(wx.EVT_BUTTON, self.OnButton, b)
b = wx.Button(self, -1, "保存文件", (75, 0))
self.Bind(wx.EVT_BUTTON, self.save_file, b)
b = wx.Button(self, -1, "保存图片", (150, 0))
self.Bind(wx.EVT_BUTTON, self.save_img, b)
b = wx.Button(self, -1, "撤销选区", (225, 0))
self.Bind(wx.EVT_BUTTON, self.back_select, b)
b = wx.Button(self, -1, "《", (300, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.previous, b)
b = wx.Button(self, -1, "》", (325, 0), size=(25, 25))
self.Bind(wx.EVT_BUTTON, self.next, b)
self.g1 = wx.Gauge(self, -1, 100, (0, 30), (-1, 100), wx.GA_VERTICAL)
def previous(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i > 0:
self.i -= 1
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def next(self, evt):
if not hasattr(self, "pdfDoc"):
return
if self.i
self.change_pdf_page(self.i, False)
self.DoDrawing(-1)
if self.rects:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
def back_select(self, evt):
if self.rects:
self.rects.pop()
self.DoDrawing(-1)
def OnButton(self, evt):
dlg = wx.FileDialog(
self, message="选择一个PDF文件",
defaultDir=os.getcwd(),
defaultFile="",
wildcard="PDF文件(*.pdf)|*.pdf",
wx.FD_CHANGE_DIR |
wx.FD_FILE_MUST_EXIST | wx.FD_PREVIEW
)
if dlg.ShowModal() == wx.ID_OK:
self.rects = []
path = dlg.GetPath()
self.pdfDoc = fitz.open(path)
self.i = 0
self.pageCount = self.pdfDoc.pageCount
self.change_pdf_page(self.i)
self.path = os.path.basename(path)
self.parent.SetTitle(self.path)
self.DoDrawing(-1)
dlg.Destroy()
def change_pdf_page(self, i, move=True):
page = self.pdfDoc[i]
rect = page.rect
print("pdf范围:", rect)
mat = fitz.Matrix(1, 1)
pix = page.get_pixmap(matrix=mat, alpha=False, clip=rect)
pix.save("tmp.png")
self.change_img("tmp.png", move)
def save_FileDialog(self, format="csv"):
dlg = wx.FileDialog(
self, message=f"保存一个{format}文件", defaultDir=os.getcwd(),
defaultFile="", wildcard=f"{format}文件(*.{format})|*.{format}", wx.FD_OVERWRITE_PROMPT
)
path = None
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
dlg.Destroy()
return path
def save_img(self, evt):
if not hasattr(self, "pdfDoc"):
return
dlg = wx.DirDialog(self, "选择图片保存的文件夹:",
wx.DD_DIR_MUST_EXIST
# | wx.DD_CHANGE_DIR
)
mat = fitz.Matrix(1, 1)
if dlg.ShowModal() == wx.ID_OK:
path = dlg.GetPath()
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
clip = page.rect
pix = page.get_pixmap(matrix=mat, alpha=False, clip=clip)
if self.rects:
name = self.extract_pdf_text(page=page, rect=self.rects[-1])
else:
name = f"p{i:0>3d}"
pix.save(f"{path}/{name}.png")
self.g1.SetValue((i + 1) * 100 // self.pdfDoc.pageCount)
dlg.Destroy()
os.system(f"explorer {path}")
def save_file(self, evt):
if not hasattr(self, "pdfDoc"):
return
path = self.save_FileDialog()
if path is None:
return
data = []
for i in range(self.pdfDoc.pageCount):
page = self.pdfDoc[i]
row = [self.extract_pdf_text(page, rect)
for i, rect in enumerate(self.rects)]
data.append(row)
with open(path, "w") as f:
writer = csv.writer(f, lineterminator="\n")
row = [f"区域{i}" for i in range(1, len(row) + 1)]
writer.writerow(row)
for row in data:
writer.writerow(row)
os.system(f"cmd /c start {path}")
def extract_pdf_text(self, page=None, rect=None):
if page is None:
page = self.pdfDoc[self.i]
if rect is None:
rect = self.rects[-1]
a, b, c, d = rect
clip = fitz.Rect(a, b, a + c, b + d)
text = page.get_text(clip=clip).strip()
return text
def change_img(self, img_path, move=True):
self.bmp = wx.Bitmap(img_path)
self.SetSize(self.bmp.GetSize())
self.parent.SetSize(self.parent.GetBestSize())
if move:
self.parent.Center()
def DoDrawing(self, evt):
if not hasattr(self, "bmp"):
return
dc = wx.ClientDC(self)
dc.DrawBitmap(self.bmp, 0, 0, True)
dc.SetPen(wx.Pen('blue'))
dc.SetBrush(wx.Brush('white', wx.BRUSHSTYLE_TRANSPARENT))
dc.DrawRectangleList(self.rects)
def OnLeftButtonEvent(self, event):
if event.LeftDown():
self.x, self.y = event.GetPosition()
self.rects.append([self.x, self.y, 0, 0])
elif event.Dragging():
x, y = event.GetPosition()
self.rects[-1][2] = x - self.x
self.rects[-1][3] = y - self.y
self.DoDrawing(-1)
elif event.LeftUp():
print(self.rects)
if self.rects[-1][2] <5 or self.rects[-1][3] <5:
self.rects.pop()
else:
self.parent.SetTitle(self.path + "|" + self.extract_pdf_text())
app = wx.App()
frm = wx.Frame(None)
pnl = MyCanvas(frm)
frm.Center()
frm.Show()
frm.SetTitle("PDF文本提取器")
app.MainLoop()








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 