JVET-U0054
在本提案中,提供了一个基于神经网络的环路滤波器(neural network based loop filter,NNLF)的初步结果。初步结果表明,在HD序列的RA配置下,NNLF对Y、U和V分量的编码增益分别比VVC高5.57%、12.55%和13.62%。
网络结构
本提案使用残差网络结构(ResNet),如图左所示,主要有m层的resblock组成,resblock的结果如右图所示,其中act指的是active function,即激活函数。网络总共64层,采用3x3x64的卷积核,使用ReLU作为激活函数

网络的输入是YUV444格式的,对于YUV420格式需要对色度分量进行上采样,上采样的方式是直接从相邻像素中进行复制。
网络的输出也是YUV444格式的,从YUV444到YUV420需要下采样,下采样的方式是为每个2x2色度块保存左上角位置处的像素值
训练
训练使用的是Vimeo90K数据集。利用VTM9.3对原始视频进行RA压缩,得到重建帧作为训练数据集。在我们的实现中,使用了32个res块,并且每个卷积层的通道数设置为64。对于卷积过程,使用3x3的卷积核。因此,总共大约有240万个模型参数。
根据Qp的不同,总共训练四个模型:{20-27, 28-32, 33-37, 38-45}
在训练过程中,首先将加载的帧裁剪成128x128的大小,以增加数据的多样性,同时降低复杂度。batch大小被设置为32,模型训练大约384000次迭代。使用Adam优化器,learning rate设置为0.0001
实验
在VTM9.3中SAO和ALF之间加入训练好的NNLF,基于帧级QP选择模型,整个帧都会进行滤波,每一个CTU存在一个flag控制是否使用滤波后的像素。

JVET-U0055
在JVET-U0054中,提出了一种基于神经网络的环路内滤波器(NNLF,neural network based in-loop filter)方案。为了进一步提高编码性能,本文提出了一种用于NNLF的多密度网络(MDN,multi-density network )。NNLF位于Deblock和SAO之间,执行CTU级信令。
对于进行NN滤波前的重建帧,如果原始颜色平面大小不同,则首先对色度分量进行上采样,将其转换为YUV444。直接复制相邻样本以简化上采样过程。在推断过程中,仅保存每个2x2色度块的左上角样本。
下图展示了所提出的多密度网络的总体架构,它包括三个部分:预处理、密度学习density learning和后处理。核心设计在于多密度块(multi-density block),由一个基本分支和一个密度分支组成。基本分支包含一些残差块以全分辨率处理特征图。加入密度分支,学习特征样本之间的密度相关性,生成权重图。在密度分支中,首先采用下采样层获得半分辨率表示。一个Resblock跟随,然后一个上采样层被连接以生成与基本分支中的特征图大小相同的权重图。最后,将密度分支的权值图与基本分支的特征图进行元素乘积融合。

下采样程序、上采样程序和Resblock的结构如下图所示。在下采样过程中,采用步长为2的3x3卷积实现半下采样过程。在ReLU激活之后,进一步应用1x1卷积层和激活函数来增强非线性学习能力。在上采样过程中,采用像素Shuffle扩展空间分辨率,再进行ReLU激活。在上采样层还增加了1x1卷积;然后,在激活步骤中采用sigmoid函数来生成介于0和1之间的密度表示。我们实现中Resblock的结构如图2-(c)所示,它包含两个卷积层和旁路映射。

训练
严格遵循JVET-T2006中规定的训练条件。在BVI-DVC中随机选取200个序列,采用RA配置的VTM10.0进行编码。每个选定的序列用4个输入qp(22、27、32、37、42)编码5次。然后将重建图像转换成YUV444格式,并根据帧级QP{(min-34、35-40、41-46、47 max)}将其分为四个子集。对于每一个子集,将训练一个模型,详细信息总结在下表中。
| Training information |
| Mandatory | GPU Type | 4x Telsa-V100-32G |
| CPU Type | Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz |
| Framework: | Pytorch 1.2.0 |
| Epoch: | 2000 |
| Batch size: | 32 |
| | Training time | 70 hours |
| | Total Parameter Number | 3.44M/model |
| | Parameter Precision (Bits) | 32 (F) |
| | Training set | BVI-DVC |
| Optional | Patch size | 128x128x3 |
| Learning rate: | 1e-4 |
| Optimizer: | ADAM |
| Loss function: | L2 |
实验结果
| | Random access Main10 |
| | Over VTM-10.0 |
| | Y | U | V | EncT | DecT |
| Class A1 | -5.60% | -9.07% | -9.67% | 99% | 1750% |
| Class A2 | -5.14% | -15.55% | -10.66% | 97% | 1696% |
| Class B | -5.47% | -13.39% | -15.04% | 96% | 1938% |
| Class C | -4.83% | -17.44% | -17.17% | 91% | 2071% |
| Class D | -6.85% | -18.22% | -21.18% | 103% | 2500% |
| Overall | -5.60% | -14.92% | -15.24% | 97% | 1998% |
| | Random access Main10 |
| | Over VVenC-0.1.0.0 |
| | Y | U | V | EncT | DecT |
| Class A1 | -5.84% | -9.10% | -9.70% | 171% | |
| Class A2 | -5.15% | -13.85% | -9.43% | 160% | |
| Class B | -5.43% | -12.50% | -14.22% | 160% | |
| Class C | -4.82% | -17.26% | -17.24% | 141% | |
| Class D | -6.63% | -19.20% | -20.81% | 217% | |
| Overall | -5.57% | -14.59% | -14.77% | 174% | |
JVET-V0074
本文提出了一种新的SDAN(Separate density attention network ),以在模型性能和复杂性之间实现更好的折衷。该模型总共只有100万个参数,与JVET-U0055[1]中的MDN相比,参数减少了70%。
提出的网络总体架构如下图1所示。网络包括主分支、一个密度分支和三个注意力分支,如图2所示。主分支由26个块组成,在特征提取和处理中起着关键作用。密度分支由一个下采样块、三个resblock和一个上采样块组成,旨在利用不同采样密度下的多尺度特征。在注意力分支方面,采用空间注意机制来降低复杂度。具体地,首先应用通道方向的下采样,然后再进行空间方向的下采样。在达到目标较小分辨率后,进一步采用空间向上采样,最后利用sigmoid函数生成权重图。将权重图融合到主分支和密度分支的特征图上,对特征进行软加权。更多的设计原则和细节可以参考论文:Z. Wang, C.Y. Ma, R.-L. Liao, Y. Ye, Multi-Density Convolutional Neural Network for In-Loop Filter in Video Coding, DCC 2021.

数据集为BVI-DVC,严格遵循JVET-T2006中规定的训练条件。根据帧QP(0-31、32-36、37-41、42-46、47 max)分别训练5个模型。在推理过程中,首先通过直接复制相邻样本将要送入网络的重建帧转换为YUV444格式。对于输出,只保存每个2x2色度块的左上角样本。基于神经网络的环路滤波位于Deblock和SAO之间。
对于网络的输出帧,将进一步发出帧级比例因子和CTU级开/关标志。缩放过程为:
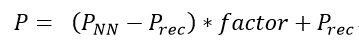
PNN和Prec分别是网络的输出和输入。
实验结果
| | Random access Main10 |
| | Over VTM-10.0 |
| | Y | U | V | EncT | DecT |
| Class A1 | -6.16% | -10.60% | -11.27% | 1.04 | 67.48 |
| Class A2 | -4.69% | -14.97% | -12.21% | 1.02 | 65.23 |
| Class B | -5.08% | -13.41% | -14.69% | 1.02 | 108.14 |
| Class C | -4.29% | -16.62% | -15.45% | 0.99 | 125.78 |
| Overall | -5.01% | -14.02% | -13.71% | 1.02 | 95.83 |
| Class D | -5.88% | -15.76% | -18.28% | 1.18 | 362.50 |
| | Random access Main10 |
| | Over VTM-10.0 |
| | Y | U | V | EncT | DecT |
| Class A1 | -6.44% | -11.55% | -11.89% | 1.04 | 84.15 |
| Class A2 | -5.23% | -15.88% | -13.16% | 1.02 | 71.77 |
| Class B | -5.73% | -14.46% | -15.82% | 1.03 | 97.67 |
| Class C | -4.76% | -17.44% | -16.43% | 0.99 | 127.32 |
| Overall | -5.52% | -14.96% | -14.67% | 1.02 | 99.49 |
| Class D | -6.37% | -16.54% | -18.98% | 1.19 | 473.19 |






 京公网安备 11010802041100号
京公网安备 11010802041100号