文章目录
- 1 实验内容
- 2 实验原理
- 3 具体实现
- 基于PaddlePaddle实现LeNet
- 加载数据:
- 建立模型:
- 模型训练:
- 模型测试:
- 基于Pytorch实现LeNet5
- 加载数据:
- 建立模型:
- 模型训练:
- 拍摄手写数字识别
- 图片平移、旋转和伸缩处理后
1 实验内容
-
实现MNIST 数据加载和可视化
-
阅读LeNet-5 的相关资料和论文,在Keras,Tensorfolow 或Pytorch 任意框架下逐层实现网
络模型的构建
-
在MNIST 数据集上实现模型训练,评估模型性能指标
-
拍摄一张包含多个自己手写数字的照片,在经过图像裁剪、二值化等图像预处理后,使用
在MNIST 数据集上训练得到的CNN 模型进行分类预测
-
(选做)对MNIST 或自己手写的数据进行不同程度的平移、旋转、(长宽等比例或不等比
例)伸缩等处理后,观察神经网络的性能变化
-
PPT 汇报(每组3min),提交3-5 页实验报告,需简要叙述方法原理、实验步骤、方法参
数讨论、实验结果;需明确说明组员分工、给出组内排名(可标注同等贡献#)。
2 实验原理
LeNet:

LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。
LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。
以上图为例,对经典的LeNet做深入分析:
首先输入图像是单通道的28*28大小的图像,用矩阵表示就是[b, 1,28,28]
-
第一个卷积层conv1所用的卷积核尺寸为5*5,滑动步长为1,卷积核数目为6,那么经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[b, 6,24,24]。
-
第一个池化层pool核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为14×14,输出矩阵为[b, 6,14,14]。
-
第二个卷积层conv2的卷积核尺寸为5*5,步长1,卷积核数目为16,卷积后图像尺寸变为10,输出矩阵为[b,16,10,10].
-
第二个池化层pool2核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为4×4,输出矩阵为[b,16 ,5, 5]。
-
pool2后面接全连接层fc1,神经元数目为120,再接relu激活函数。
-
再接fc2,神经元个数为84,再接relu激活函数。
-
输出层得到10维的特征向量,用于10个数字的分类训练,送入softmax分类,得到分类结果的概率output。
3 具体实现
基于PaddlePaddle实现LeNet
加载数据:
用飞桨框架自带的 paddle.vision.datasets.MNIST 完成mnist数据集的加载与预处理归一化。
transform = Compose([Normalize(mean=[127.5],std=[127.5],data_format='CHW')])
print('download training data and load training data')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('load finished')
这里尝试取训练集中的第666条数据看一下:
import numpy as np
import matplotlib.pyplot as plt
train_data0, train_label_0 = train_dataset[0][0],train_dataset[0][1]
train_data0 = train_data0.reshape([28,28])
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
print('train_data0 label is: ' + str(train_label_0))
结果如下:

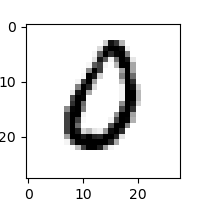
可见数据加载成功。
建立模型:
我们直接用paddle.nn下的API,如Conv2D、MaxPool2D、Linear完成LeNet的构建。
代码如下:
import paddle
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):def __init__(self):super(LeNet, self).__init__()self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.max_pool1(x)x = F.relu(x)x = self.conv2(x)x = self.max_pool2(x)x = paddle.flatten(x, start_axis=1,stop_axis=-1)x = self.linear1(x)x = F.relu(x)x = self.linear2(x)x = F.relu(x)x = self.linear3(x)return x
模型训练:
通过paddle提供的Model 构建实例,使用封装好的训练与测试接口,快速完成模型训练与测试。
from paddle.metric import Accuracy
model = paddle.Model(LeNet())
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
model.prepare(optim,paddle.nn.CrossEntropyLoss(),Accuracy())
model.fit(train_dataset,epochs=2,batch_size=64,verbose=1)
训练过程如下所示:

模型测试:
使用 Model.evaluate 来预测模型:
结果如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8eap7pPC-1634528724500)(https://i.loli.net/2021/10/13/h5jz6xHeRAOEZqL.png)]
基于Pytorch实现LeNet5
加载数据:
batch_size = 256
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=1, shuffle=True)
建立模型:
class LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5, padding=2)self.pooling = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(6, 16, 5)self.AF = nn.ReLU()self.fc1 = nn.Linear(16*5*5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)for m in self.modules():if isinstance(m, (nn.Conv3d, nn.Conv2d, nn.Conv1d)):nn.init.xavier_uniform_(m.weight.data)elif isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight.data)nn.init.constant_(m.bias.data, 0.0)def forward(self, x):x = self.AF(self.conv1(x))x = self.pooling(x)x = self.AF(self.conv2(x))x = self.pooling(x)x = x.view(x.size(0), -1)x = self.AF(self.fc1(x))x = self.AF(self.fc2(x))x = self.fc3(x)return x
模型训练:
if __name__=="__main__":batch_size = 256train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=1, shuffle=True)loss = nn.CrossEntropyLoss()loss.to(device)net =LeNet5()net.to(device)net.train()epoch = 10lr = 1e-2optimizer = optim.SGD(net.parameters(), lr=lr, momentum = 0.9)for i in range(epoch):net.train()for j, (X, y) in enumerate(train_loader):optimizer.zero_grad()X,y = autograd.Variable(X).to(device), autograd.Variable(y).to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()test_acc = evaluate_accuracy(net, test_loader)print("epoch:{}, test_acc:{}".format(i,test_acc))
训练过程:

拍摄手写数字识别
拍照采集手写数字
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gIOYbwtf-1634528724502)(https://i.loli.net/2021/10/12/OnFLr1f3xiJPuW7.jpg)]
通过截图裁剪保存为单个图片
图片处理
转为灰度图、改变图像大小
from PIL import Image
import numpy as np
import matplotlib.pyplot as pltdef load_image(file):im = Image.open(file).convert('L')im = im.resize((28, 28), Image.ANTIALIAS)im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)im = im / 255.0 * 2.0 - 1.0return im

送入网络测试
files = os.listdir('testpic')for file in files:img = load_image('testpic/' + file)plt.imshow(img[0][0], cmap=plt.cm.gray)plt.show()from Mnist_paddlepaddle import LeNetmodel = paddle.Model(LeNet())model.load('mnist_checkpoint/test')result = model.predict_batch(img)print("Inference result of image is:{}".format(np.argmax(result)), end=' ')print("The real label is:{}".format(file[4]))
结果:


可见错了很多,观察Mnist数据集发现,应该是截图中数字比例太小
重新截了一组图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5seZ14rH-1634528724508)(https://i.loli.net/2021/10/12/k9hDOrHtP3Cgoa8.png)]
测试结果:

本次只错了一个。
图片平移、旋转和伸缩处理后
以数字2为例。
原始图片:


结果:
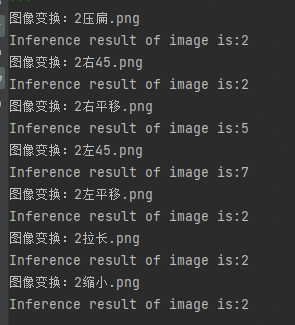
数字5:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pFxQwCd3-1634528724512)(https://i.loli.net/2021/10/12/631miPgd5WZlMew.png)]
结果:
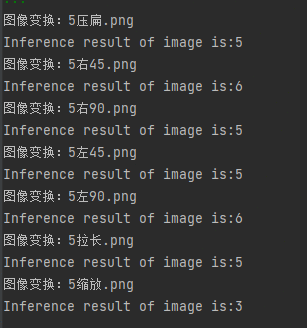
可见:

所以,需要data augmentation与Spatial Transformer Layer来解决此类问题。








 京公网安备 11010802041100号
京公网安备 11010802041100号