项目背景: 此项目使用elk来展示分析k8s集群产生的日志。k8s集群是apache网站,将apache产生的日记信息通过filebeat传递给logstash -> elasticsearch -> kibana, 然后页面展示及分析。此项目将apache制作的网站以及elasticsearch集群和kibana发布至公网。
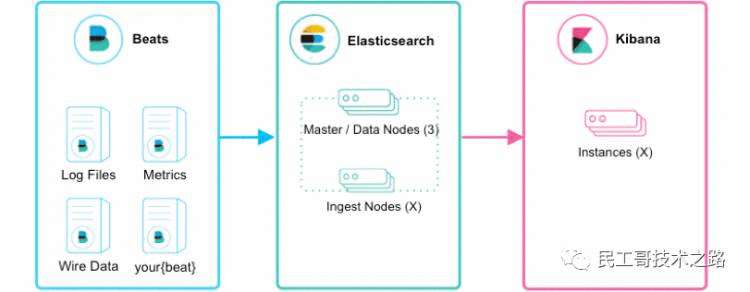
项目最终实现的架构图:

主机准备及配置:

Phase 1, 部署Harbor私有仓库
为了简洁,单独一个随笔:部署Harbor私有仓库 - 小白白bai - 博客园 (cnblogs.com)
Phase 2, K8S集群环境部署
K8S集群环境部署 - 小白白bai - 博客园 (cnblogs.com)
Phase 3, Elasticsearch集群环境部署并发布
Elasticsearch集群环境部署并发布 - 小白白bai - 博客园 (cnblogs.com)
Phase 4, Kibana服务部署
Kibana是一款开源的数据分析和可视化平台,它是Elastic Stack成员之一。可以使用Kibana对Elasticsearch索引中的数据进行搜索、查看、交互操作。可利用图表、表格等对数据进行多元化的分析和显现。
1,安装kibana软件包
[root@kibana ~]# yum -y install kibana
2,更改kibana服务配置文件
[root@kibana ~]# vim /etc/kibana/kibana.yml
server.port: 5601 #2行,提供服务的端口。
server.host: "192.168.1.74" #7行,服务器监听地址。
elasticsearch.hosts: ["http://192.168.1.71:9200"] #28行,用于查询es实例主机地址,集群里面任选一个
即可。
3,启动服务器并查看端口是否启用
[root@knbana ~]# systemctl enable --now kibana
[root@kibana ~]# netstat -antpu | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 8840/node
4,将kibana服务器的5601端口发布出来;访问kibana界面:http://公网IP:5601

Phase 5, 制作Apache和filebeat镜像,并上传至Harbor仓库
制作Apache和filebeat镜像,并上传至Harbor仓库 - 小白白bai - 博客园 (cnblogs.com)
Phase 6, 编写apachelog.yaml资源清单文件 (一个pod包括两个容器,并使用持久化存储,hostpath)
从私有仓库harbor中pull镜像的时候,k8s集群使用类型为docker-registry的Secret进行认证。
现在创建一个Secret,名称为regcred:
master主机认证,登录harbor
[root@master ~]# kubectl create secret docker-registry regcred --docker-server=192.168.1.100:80
--docker-username=admin --docker-password=Harbor12345
查看regcred的详细信息,其中.dockerconfigjson的值包含了登录harbor的用户名和密码等信息
[root@master ~]# kubectl get secret regcred --output=yaml
通过以下命令进行查看:
[root@master ~]# kubectl get secret regcred --output="jsOnpath={.data.\.dockerconfigjson}" | base64 -d
1,编写apachelog.yaml资源清单文件
[root@master ~]# vim apachelog.yaml
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: weblog
spec:
selector:
matchLabels:
myapp: weblog
replicas: 1
template:
metadata:
labels:
myapp: weblog
spec:
volumes:
#- name: empty-data
# emptyDir: {}
- name: log-data
hostPath:
path: /var/weblog
type: DirectoryOrCreate
containers:
- name: apache
image: 192.168.1.100:80/library/myos:httpd
volumeMounts:
#- name: empty-data
# mountPath: /var/cache
- name: log-data
mountPath: /var/log/httpd
ports:
- protocol: TCP
containerPort: 80
- name: filebeat-backend
image: 192.168.1.100:80/library/myos:filebeat
volumeMounts:
- name: log-data
mountPath: /var/weblog
restartPolicy: Always
imagePullSecrets:
- name: regcred
2,创建资源
[root@master ~]# kubectl apply -f apachelog.yaml
3,查看在哪台机器上面启动,就去哪台机器上面看日志
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
weblog-688dd9768c-vwkbs 1/1 Running 0 4m24s 10.244.3.4 node-0002
[root@node-0002 ~]# ls /var/weblog/
access_log error_log
[root@node-0002 ~]# cat /var/weblog/access_log
Phase 7, 安装部署logstash服务1.75并配置logstash配置文件
1,装包
[root@logstash ~]# yum -y install logstash
2,配置logstash
[root@logstash ~]# vim /etc/logstash/logstash.conf
input{
stdin{ codec => "json" }
beats{
port => 5044
}
}
filter{
if [type] == "apache_log" {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
}
output{
stdout{ codec => "rubydebug" }
if [type] == "apache_log" {
elasticsearch {
index => "apache"
hosts => ["es-0001:9200","es-0002:9200","es-0003:9200"]
}
}
}
3,启服务
[root@logstash ~]# /usr/share/logstash/bin/logstash -f /etc/logstash/logstash.conf
Phase 8, 验证



![Kubernetes 1.9.0 Alpha.1 发布公告 [Kubernetes 最新动态]](https://img1.php1.cn/3cd4a/25047/ae9/3397348f4961686e.png)


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有