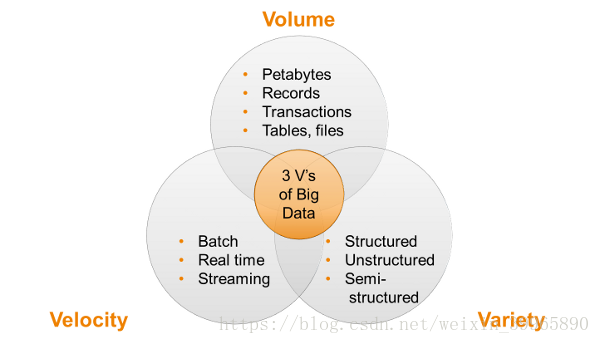
如果你问人们,大数据是什么?比较样板化的答案通常是三个 V:数量(volume),效率(velocity)和广阔性(variety)。接下来他们会开始讨论,他们的数据到底有多大才能被定义为“大数据”。当你开始看到实际技术的时候,事情开始变得比较复杂。这些主要的挑战使事情发展到,今天已经没有单一的一种科技可以一次性处理有关于大数据的三个 V 的所有问题——数量。效率和广阔性。
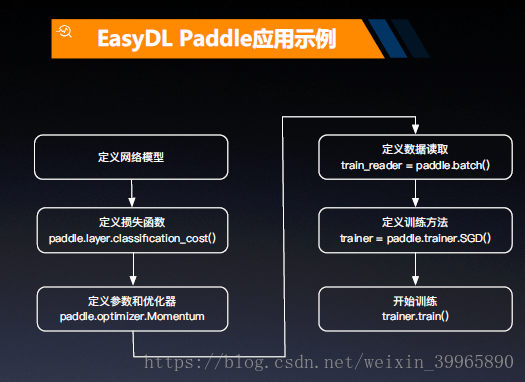
刚才提到了的核心技术除去AI workflow, 还有百度自创PaddlePaddle深度学习框架。PaddlePaddle全名叫做PArallel Distributed Deep Learning, “是一个深度学习框架/语言”。在EasyDL中,Paddle有如下应用示例:
此外,EasyDL还使用了Auto Model Search 和 Early stopping机制,让少两样本就能有用高精度。Auto Model Search就是对模型结构和超参数做自动搜索,更好匹配不同类型数据,做最佳模型。而early stopping呢,能够降低过拟合风险。做过DL的同学应该都有体会,DL是能分分钟过拟合的,对于这种风险,early stopping能很好抑制过拟合和欠拟合。目前EasyDL的模型绝大多数准确率都在80%以上。









 京公网安备 11010802041100号
京公网安备 11010802041100号