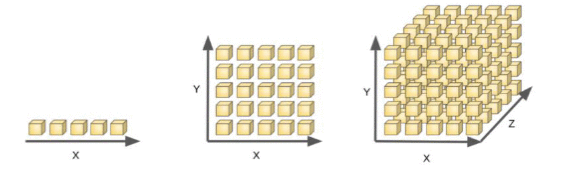
维数灾难:通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。在很多机器学习问题中,训练集中的每条数据经常伴随着上千、甚至上万个特征。要处理这所有的特征的话,不仅会让训练非常缓慢,还会极大增加搜寻良好解决方案的困难。这个问题就是我们常说的维数灾难。
维数灾难涉及数字分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。在机器学习的建模过程中,通常指的是随着特征数量的增多,计算量会变得很大,如特征达到上亿维的话,在进行计算的时候是算不出来的。有的时候,维度太大也会导致机器学习性能的下降,并不是特征维度越大越好,模型的性能会随着特征的增加先上升后下降。
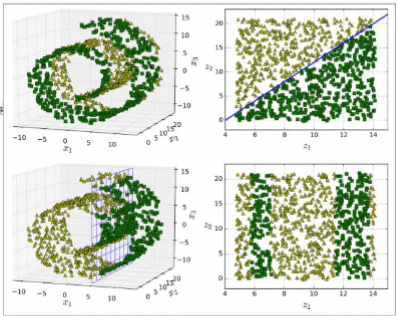
降维是将训练数据中的样本(实例)从高维空间转换到低维空间,该过程与信息论中有损压缩概念密切相关。同时要明白的,不存在完全无损的降维。
如果矩阵过大,就会导致训练时间过长,所以需要降低特征矩阵维度。降维是指通过保留重要的特征,减少数据特征的维度。而特征的重要性取决于该特征能够表达多少数据集的信息,也取决于使用什么方法进行降维。特征降维方法包括:PCA、LDA、奇异值分解SVD和局部线性嵌入LLE。而降维的好处可以节省存储空间,加快计算速度,避免模型过拟合等。在这些方法中,降维是通过对原始数据的线性变换实现的。
降维原因:
- 高维数据增加了运算的难度。
- 高维使得学习算法的泛化能力变弱(例如,在最近邻分类器中,样本复杂度随着维度成指数增长),维度越高,算法的搜索难度和成本就越大。
- 降维能够增加数据的可读性,利于发掘数据的有意义的结构。
降维的主要作用:减少冗余特征,降低数据维度,数据可视化。
减少冗余特征:假设我们有两个特征:
现在我们的矩阵𝐴 只需要黄色的部分的三个小矩阵就可以近似描述了。
【案例】
机器学习:概念_燕双嘤-CSDN博客1,机器学习概述1.1,机器学习概念机器学习即Machine Learning,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。目的是让计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。简单来讲,机器学习就是人们通过提供大量的相关数据来训练机器。DataAnalysis:基本概念,环境介绍,环境搭建,大数据问题_燕双嘤-CSDN博客1,概述1.1,数据的性质所谓数据就是描述事物的符号,是对客观事物的性质、状态和相互关系等进行记载的
优点:
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素。
- 计算方法简单,主要运算时特征值分解,易于实现。
- 它是无监督学习,完全无参数限制的。
缺点:
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
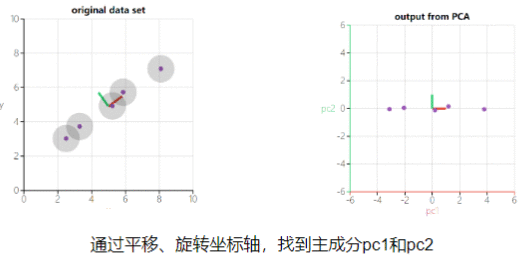
PCA 的原理是通过坐标轴转换,寻找数据分布的最优子空间。PCA是一个将数据变换到新坐标系统中的线性变换,使得任何数据投影的第一大方差在第一个坐标(第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
PCA主要目的是为让映射后得到的向量具有最大的不相关性。详细地讲就是PCA追求的是在降维之后能够最大化保持数据的内在信息,并通过衡量在投影方向上的数据方差的大小来衡量该方法的重要性。
PCA 减少
对于矩阵
LDA是一种有监督的降维方法,主要是将高维的模式样本投影到最佳鉴别的空间。其目的是投影后保证模式样本在新的子空间有最大的类间距和最小的类内间距,即同类的数据点尽可能地接近而不同的类的数据点尽可能地分开。
LDA和PCA的区别:
- LDA是有监督的降维方法,而PCA是无监督的。
- LDA降维最多降到类别数 k-1 的维数,而PCA没有限制。
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
换句话就是PCA是为了让映射后的样本发散性最大;而LDA是为了让映射后的样本分类性能最好。
局部线性嵌入(LLE)
局部线性嵌入算法认为每个数据点可以由其临近点的线性加权组合构造得到,能够使降维后的数据较好地保持原有流形结构。主要步骤是寻找每个样本点的 k 个临近点,由每个样本点计算出该样本点的局部重建权值矩阵,由该样本点的局部重建权值矩阵和其临近点计算出该样本点的输出值。在实际应用中,使用较少。











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有