在处理文本文件时,经常需要对比两个文件中的特定字段并提取出相同的内容。本文将介绍如何使用 Java 和集算器(SPL)来实现这一功能。
假设我们有两个文件 Old.txt 和 New.txt,第一行是列名,我们需要提取出 Name 字段相同的内容。部分数据如下:
Old.txt | New.txt |
Name Dept Rachel Sales Ashley R&D Matthew Sales Alexis Sales Megan Marketing | Name Dept Emily HR Ashley R&D Matthew Sales Alexis Sales Megan Marketing |
期望的运算结果如下:
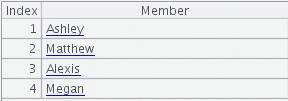
在 Java 中,由于缺乏内置的集合操作支持,通常需要使用大量的循环和条件判断来实现文件对比。例如,以下是一个简单的 Java 实现:
... while ((String lineText = comparedReader.readLine()) != null) { String comparedLine = lineText.trim(); if (searchText.equals(comparedLine)) { lineStr = "###=Equal:" + lineNum + "=###\n"; break; } lineNum++; } rbw.write(lineStr); comparedReader.reset(); ... |
相比之下,使用集算器(SPL)可以大大简化这一过程。SPL 提供了一套丰富的集合运算函数库,使得代码更加简洁。例如,上述问题可以用两行 SPL 代码解决:
1 | =Old=file("Old.txt").import@t(), New=file("New.txt").import@t() |
2 | =Old.(Name)^ New.(Name) |
除了文件对比,SPL 还可以轻松处理大文件的对比、关联计算、数据入库等复杂需求。对于希望在 Java 应用程序中集成这些功能的开发者,SPL 提供了简便的调用方法。
关于集算器的安装使用、免费授权获取及相关技术资料,可以参考 如何使用集算器。




 京公网安备 11010802041100号
京公网安备 11010802041100号