小编给大家分享一下JVM上高性能数据格式库包ApacheArrow入门和架构的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!Apac
小编给大家分享一下JVM上高性能数据格式库包Apache Arrow入门和架构的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
Apache Arrow是是各种大数据工具(包括BigQuery)使用的一种流行格式,它是平面和分层数据的存储格式。它是一种加快应用程序内存密集型。
数据处理和数据科学领域中的常用库: Apache Arrow 。诸如Apache Parquet,Apache Spark,pandas之类的开放源代码项目以及许多商业或封闭源代码服务都使用Arrow。它提供以下功能:
让我们看一看在Arrow出现之前事物是如何工作的:
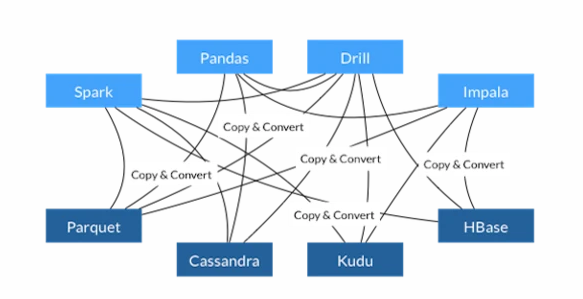
我们可以看到,为了使Spark从Parquet文件中读取数据,我们需要以Parquet格式读取和反序列化数据。这要求我们通过将数据加载到内存中来制作数据的完整副本。首先,我们将数据读入内存缓冲区,然后使用Parquet的转换方法将数据(例如字符串或数字)转换为我们的编程语言的表示形式。这是必需的,因为Parquet表示的数字与Python编程语言表示的数字不同。
由于许多原因,这对于性能来说是一个很大的问题:
现在,让我们看一下Apache Arrow如何改进这一点:
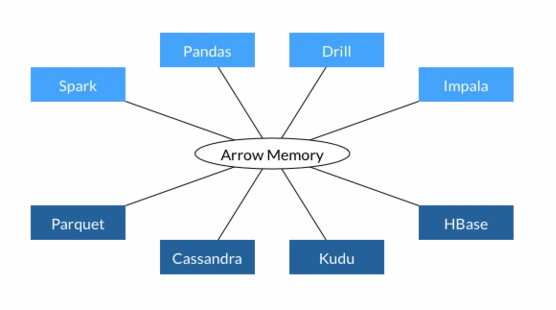
Arrow无需复制和转换数据,而是了解如何直接读取和操作数据。为此,Arrow社区定义了一种新的文件格式以及直接对序列化数据起作用的操作。可以直接从磁盘读取此数据格式,而无需将其加载到内存中并转换/反序列化数据。当然,部分数据仍将被加载到RAM中,但您的数据不必放入内存中。Arrow使用其文件的内存映射功能,仅在必要和可能的情况下将尽可能多的数据加载到内存中。
Apache Arrow支持以下语言:
C++
C#
Go
Java
Javascript
Rust
Python (through the C++ library)
Ruby (through the C++ library)
R (through the C++ library)
MATLAB (through the C++ library).
Arrow特点
Arrow首先是提供用于内存计算的列式数据结构的库,可以将任何数据解压缩并解码为Arrow柱状数据结构,以便随后可以对解码后的数据进行内存内分析。Arrow列格式具有一些不错的属性:随机访问为O(1),每个值单元格在内存中的前一个和后一个相邻,因此进行迭代非常有效。
Apache Arrow定义了一种二进制“序列化”协议,用于安排Arrow列数组的集合(称为“记录批处理”),该数组可用于消息传递和进程间通信。您可以将协议放在任何地方,包括磁盘上,以后可以对其进行内存映射或读入内存并发送到其他地方。
Arrow协议的设计目的是使您可以“映射”一个Arrow数据块而不进行任何反序列化,因此对磁盘上的Arrow协议数据执行分析可以使用内存映射并有效地支付零成本。该协议用于很多事情,例如Spark SQL和Python之间的流数据,用于针对Spark SQL数据块运行pandas函数,这些被称为“ pandas udfs”。
Arrow是为内存而设计的(但是您可以将其放在磁盘上,然后再进行内存映射)。它们旨在相互兼容,并在应用程序中一起使用,而其竞争对手Apache Parquet文件是为磁盘存储而设计的。
优点:Apache Arrow为平面和分层数据定义了一种独立于语言的列式存储格式,该格式组织为在CPU和GPU等现代硬件上进行高效的分析操作而组织。Arrow存储器格式还支持零拷贝读取,以实现闪电般的数据访问,而无需序列化开销。
Java的Apache Arrow
导入库:
org.apache.arrow
arrow-memory-netty
${arrow.version}
org.apache.arrow
arrow-vector
${arrow.version}
在开始之前,必须了解对于Arrow的读/写操作,使用了字节缓冲区。诸如读取和写入之类的操作是字节的连续交换。为了提高效率,Arrow附带了一个缓冲区分配器,该缓冲区分配器可以具有一定的大小,也可以具有自动扩展功能。支持分配管理的库是arrow-memory-netty和arrow-memory-unsafe。我们这里使用netty。
用Arrow存储数据需要一个模式,模式可以通过编程定义:
package com.gkatzioura.arrow;
import java.io.IOException;
import java.util.List;
import org.apache.arrow.vector.types.pojo.ArrowType;
import org.apache.arrow.vector.types.pojo.Field;
import org.apache.arrow.vector.types.pojo.FieldType;
import org.apache.arrow.vector.types.pojo.Schema;
public class SchemaFactory {
public static Schema DEFAULT_SCHEMA = createDefault();
public static Schema createDefault() {
var strField = new Field("col1", FieldType.nullable(new ArrowType.Utf8()), null);
var intField = new Field("col2", FieldType.nullable(new ArrowType.Int(32, true)), null);
return new Schema(List.of(strField, intField));
}
public static Schema schemaWithChildren() {
var amount = new Field("amount", FieldType.nullable(new ArrowType.Decimal(19,4,128)), null);
var currency = new Field("currency",FieldType.nullable(new ArrowType.Utf8()), null);
var itemField = new Field("item", FieldType.nullable(new ArrowType.Utf8()), List.of(amount,currency));
return new Schema(List.of(itemField));
}
public static Schema fromJson(String jsonString) {
try {
return Schema.fromJSON(jsonString);
} catch (IOException e) {
throw new ArrowExampleException(e);
}
}
}他们也有一个可解析的json表示形式:
{
"fields" : [ {
"name" : "col1",
"nullable" : true,
"type" : {
"name" : "utf8"
},
"children" : [ ]
}, {
"name" : "col2",
"nullable" : true,
"type" : {
"name" : "int",
"bitWidth" : 32,
"isSigned" : true
},
"children" : [ ]
} ]
}另外,就像Avro一样,您可以在字段上设计复杂的架构和嵌入式值:
public static Schema schemaWithChildren() {
var amount = new Field("amount", FieldType.nullable(new ArrowType.Decimal(19,4,128)), null);
var currency = new Field("currency",FieldType.nullable(new ArrowType.Utf8()), null);
var itemField = new Field("item", FieldType.nullable(new ArrowType.Utf8()), List.of(amount,currency));
return new Schema(List.of(itemField));
}基于上面的的Schema,我们将为我们的类创建一个DTO:
package com.gkatzioura.arrow;
import lombok.Builder;
import lombok.Data;
@Data
@Builder
public class DefaultArrowEntry {
private String col1;
private Integer col2;
}我们的目标是将这些Java对象转换为Arrow字节流。
1. 使用分配器创建 DirectByteBuffer
这些缓冲区是 堆外的 。您确实需要释放所使用的内存,但是对于库用户而言,这是通过在分配器上执行 close() 操作来完成的。在我们的例子中,我们的类将实现 Closeable 接口,该接口将执行分配器关闭操作。
通过使用流api,数据将被流传输到使用Arrow格式提交的OutPutStream:
package com.gkatzioura.arrow;
import java.io.Closeable;
import java.io.IOException;
import java.nio.channels.WritableByteChannel;
import java.util.List;
import org.apache.arrow.memory.RootAllocator;
import org.apache.arrow.vector.IntVector;
import org.apache.arrow.vector.VarCharVector;
import org.apache.arrow.vector.VectorSchemaRoot;
import org.apache.arrow.vector.dictionary.DictionaryProvider;
import org.apache.arrow.vector.ipc.ArrowStreamWriter;
import org.apache.arrow.vector.util.Text;
import static com.gkatzioura.arrow.SchemaFactory.DEFAULT_SCHEMA;
public class DefaultEntriesWriter implements Closeable {
private final RootAllocator rootAllocator;
private final VectorSchemaRoot vectorSchemaRoot;//向量分配器创建:
public DefaultEntriesWriter() {
rootAllocator = new RootAllocator();
vectorSchemaRoot = VectorSchemaRoot.create(DEFAULT_SCHEMA, rootAllocator);
}
public void write(List defaultArrowEntries, int batchSize, WritableByteChannel out) {
if (batchSize <= 0) {
batchSize = defaultArrowEntries.size();
}
DictionaryProvider.MapDictionaryProvider dictProvider = new DictionaryProvider.MapDictionaryProvider();
try(ArrowStreamWriter writer = new ArrowStreamWriter(vectorSchemaRoot, dictProvider, out)) {
writer.start();
VarCharVector childVector1 = (VarCharVector) vectorSchemaRoot.getVector(0);
IntVector childVector2 = (IntVector) vectorSchemaRoot.getVector(1);
childVector1.reset();
childVector2.reset();
boolean exactBatches = defaultArrowEntries.size()%batchSize == 0;
int batchCounter = 0;
for(int i=0; i < defaultArrowEntries.size(); i++) {
childVector1.setSafe(batchCounter, new Text(defaultArrowEntries.get(i).getCol1()));
childVector2.setSafe(batchCounter, defaultArrowEntries.get(i).getCol2());
batchCounter++;
if(batchCounter == batchSize) {
vectorSchemaRoot.setRowCount(batchSize);
writer.writeBatch();
batchCounter = 0;
}
}
if(!exactBatches) {
vectorSchemaRoot.setRowCount(batchCounter);
writer.writeBatch();
}
writer.end();
} catch (IOException e) {
throw new ArrowExampleException(e);
}
}
@Override
public void close() throws IOException {
vectorSchemaRoot.close();
rootAllocator.close();
}
}为了在Arrow上显示批处理的支持,已在函数中实现了简单的批处理算法。对于我们的示例,只需考虑将数据分批写入。
让我们深入了解上面代码功能:
向量分配器创建:
public DefaultEntriesToBytesConverter() {
rootAllocator = new RootAllocator();
vectorSchemaRoot = VectorSchemaRoot.create(DEFAULT_SCHEMA, rootAllocator);
}然后在写入流时,实现并启动了Arrow流编写器
ArrowStreamWriter writer = new ArrowStreamWriter(vectorSchemaRoot, dictProvider, Channels.newChannel(out));
writer.start();
我们将数据填充向量,然后还重置它们,但让预分配的缓冲区 存在 :
VarCharVector childVector1 = (VarCharVector) vectorSchemaRoot.getVector(0);
IntVector childVector2 = (IntVector) vectorSchemaRoot.getVector(1);
childVector1.reset();
childVector2.reset();
写入数据时,我们使用 setSafe 操作。如果需要分配更多的缓冲区,应采用这种方式。对于此示例,此操作在每次写入时都完成,但是在考虑了所需的操作和缓冲区大小后可以避免:
childVector1.setSafe(i, new Text(defaultArrowEntries.get(i).getCol1()));
childVector2.setSafe(i, defaultArrowEntries.get(i).getCol2());
然后,将批处理写入流中:
vectorSchemaRoot.setRowCount(batchSize);
writer.writeBatch();
最后但并非最不重要的一点是,我们关闭了writer:
@Override
public void close() throws IOException {
vectorSchemaRoot.close();
rootAllocator.close();
}看完了这篇文章,相信你对“JVM上高性能数据格式库包Apache Arrow入门和架构的示例分析”有了一定的了解,如果想了解更多相关知识,欢迎关注编程笔记行业资讯频道,感谢各位的阅读!








 京公网安备 11010802041100号
京公网安备 11010802041100号