hello,好久不见
最近在做公司的数仓,遇到一个问题,希望大家可以不吝赐教:
问题:hive 中count(*) 结果不准确? 场景:hive 中建表,
stored as parquet
从ods层导入数据,先进行全表检索。
select * from dwd_fact_order_info where dt = "2020-10-01"
结果:
接下来这个count(*)就比较神奇了,结果变为150了,count(*) 不统计空行这是知道的,但是通过可视化工具连接hive发现该表数据没有空行。
select count(*) from dwd_fact_order_info where dt = "2020-10-01"
结果:
同时对该份数据进行简单查询,结果没有问题
select order_id from dwd_fact_order_info where dt = "2020-10-01"
结果:
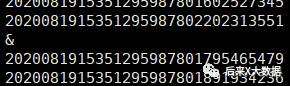
但是继续对当前结果group by,却出现了& 符号。
select order_id from dwd_fact_order_info where dt = "2020-10-01" group by order_id
结果:
这个问题实在是有点迷,还在解决中。
--------------我是分割线-----------
「要对hive 进行调优,首先要对症下药,那么这一章先讲环境调优,下一次讲HQL调优。」
1、关于Hive的计算引擎 hadoop 的基本架构中的计算框架是map-reduce,简称MR,而Hive是基于hadoop的,所以Hive的默认引擎也是MR。MR的速度确实非常感人的慢,随着计算引擎的更新,目前主要是Tez和Spark。那么这3个计算引擎的区别是什么
因为都运行在yarn 之上,所以这3个引擎可以随意切换。
Map:
关于tez的部署我也写过一篇文章Hive3.1.2+大数据引擎Tez0.9.2安装部署到使用测试(踩坑详情)
该引擎核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output,Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
Spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。 Spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。同时Spark也提供了更丰富的计算API,例如filter,flatMap,count,distinct等。 过程间耦合度低,单个过程的失败后可以重新计算,而不会导致整体失败; 2、hive的哪些查询不会走MR? 这个问题就涉及到一个hive的配置,fetch的抓取。
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算,配置在hive-default.xml.template中,默认就是more
<property > <name > hive.fetch.task.conversionname ><value > morevalue ><description > description >property >
在这种情况下,一些简单查询都不会走MR,所以如果是老版本的hive,可以把该配置改为more
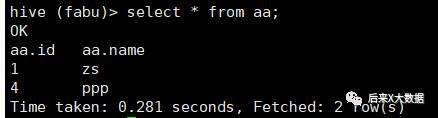
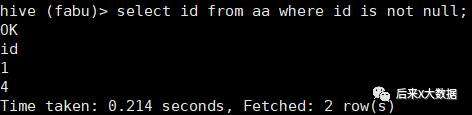
select * from 表名;
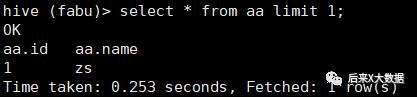
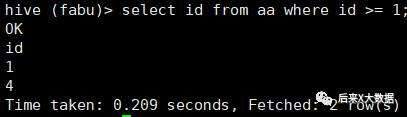
select * from 表名 limit 2 ;
注意:在MYSQL中limit是取前几条记录,但是在Hive中,limit是抽样,「会随机返回对应的记录数」 。
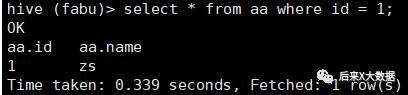
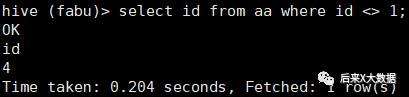
select * from 表名 where id=1;
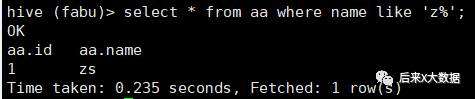
select * from 表名 where name like '%试' ;
表数据格式生成数据的时候,会将一些聚合计算结果(如 count avg)和少量索引等存到数据里面,所以你直接count(*) 这个表会从数据的元信息里面直接获取
对于集合统计函数都会走MR,排除已经在元数据中存储的聚合运算结果
MR 实质上是对数据进行map 和reduce 两阶段的处理,那么我们在上述 不走MR的SQL中都是对元数据的查询和直接对hdfs 上单个文件的抓取和判断,并没有涉及到聚合。
3、日志处理 对于我们程序员来说,终于写好一个HQL准备测试一下,结果各种报错,此时最需要的莫过于记录详细执行情况的日志。
Hive使用log4j进行日志记录。默认情况下,客户端不会将日志发送到控制台。从Hive 0.13.0开始,默认日志记录级别为INFO。
hive.log.dir在$ HIVE_HOME conf hive-log4j.properties中进行设置。
目前版本的hive 连接,需要开启hiveServer2和metastore
hive的日志分为好几种
运行日志,也可以说是系统日志,记录了hive的运行情况,错误状况。 执行日志,记录了Hive 中job的执行的历史过程。 一般前2种看的比较多,那么如何设置呢?Hive运行日志
//修改获得hive-log4j.properties文件
hive任务执行日志
//修改获得hive-exec-log4j.properties文件
当然以上设置是全局生效,也可以在进入hive的时候,使用
hive --hiveconf hive.root.logger=DEBUG,console (hive启动时用该命令替代)
或者在${HIVE_HOME}/conf/hive-log4j.properties文件中找到hive.root.logger属性,并将其修改为下面的设置
设定Log的参数读取会在会话建立以前完成。这也就是说,我们不能通过下面的方法来修改log4j的日志输出级别:
hive> set hiveconf:hive.root.logger=DEBUG,console;(错误使用X)
4、本地模式 一般情况下,Hive编译器会为大多数查询生成多个MR job,然后把这些job提交到集群中执行。但是每次执行都要在集群中创建container,造成时间比较慢。所以对于小型数据集,可以直接在本地模式运行,本地模式执行通常比将作业提交到集群要快得多。注意:本地模式仅使用一个job运行,所以处理大型数据集的速度可能非常慢。
这其中时间只是节省在了每次提交到集群以及创建容器时间上了。
SET mapreduce.framework.name = local ;(这是默认的)
所以一般在配置hadoop集群时,会在 mapred-site.xml的配置文件中配置。
mapreduce.framework.name yarn 指定mr框架为yarn方式
除此之外,我们还可以利用本地模式帮助我们快速处理少量数据:
SET hive.exec.mode.local.auto = true ;(默认是false )
如果启用了这个配置,Hive会分析查询中每个map-reduce作业的大小,如果满足以下阈值,才可以在本地运行它
job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB) job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4) job的reduce数必须为0或者1 「(因为本地模式本身就仅使用一个map-reduce 运行)」 本地模式运行在Hive Client上一个独立的子JVM上,可以通过hive.mapred.local.mem
5、JVM重用 JVM 重用只对MR引擎是有效的,因为MR任务中的mapTask 和ReduceTask都各自运行在一个独立的JVM进程中,同时「每个MapTask/ReduceTask都要经历申请资源 -> 运行task -> 释放资源的过程」 。强调一点:每个MapTask/ReduceTask运行完毕所占用的资源必须释放,并且这些释放的资源不能够为该任务中其他task所使用。
所以开启JVM重用在一定程度上能缓解MapReduce让每个task动态申请资源且运行完后马上释放资源带来的性能开销
但是JVM重用并不是多个task可以并行运行在一个JVM进程中,而是「对于同一个job,一个JVM上最多可以顺序执行的task数目」 ,这个需要配置参数mapred.job.reuse.jvm.num.tasks,默认1。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
<property > <name > mapreduce.job.jvm.numtasksname ><value > 10value ><description > How many tasks to run per jvm. If set to -1, there isdescription >property >
这个功能的缺点是,开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job中有某几个reduce task执行的时间要比其他Reduce task消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的job使用,直到所有的task都结束了才会释放。
对于Spark 引擎来说,每次 MapReduce 操作是基于线程的,只在启动 Executor 时启动一次 JVM,内存的 Task 操作是在线程复用的。每次启动 JVM 的时间可能就需要几秒甚至十几秒。
6、严格模式 严格模式:防止用户执行一些影响比较大的sql
1、分区表的查询必须where 分区,也就是说不允许扫描所有的分区。
2、使用了order by 语句的查询,必须使用limit 语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间。
3、限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
7、并行模式 针对于不同业务场景SQL语句的执行情况,有些场景下SQL的执行是需要分割成几段去执行的,而且期间并不全是存在依赖关系。默认情况下,hive只会一段一段的执行mapreduce任务。使用并行的好处在于可以让服务器可以同时去执行那些不相关的业务场景
// 开启任务并行执行set hive.exec.parallel=true ;set hive.exec.parallel.thread.number=8;
以下sql 中union all前后的2个查询操作并无直接关联,因此没有必要顺序执行,因此优化的思路是让这2个查询操作并行执行。
select a.id,b.nameform union b
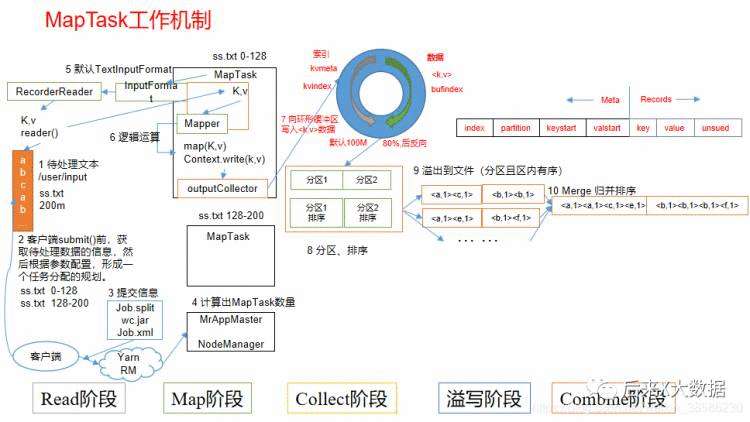 Reduce:
Reduce: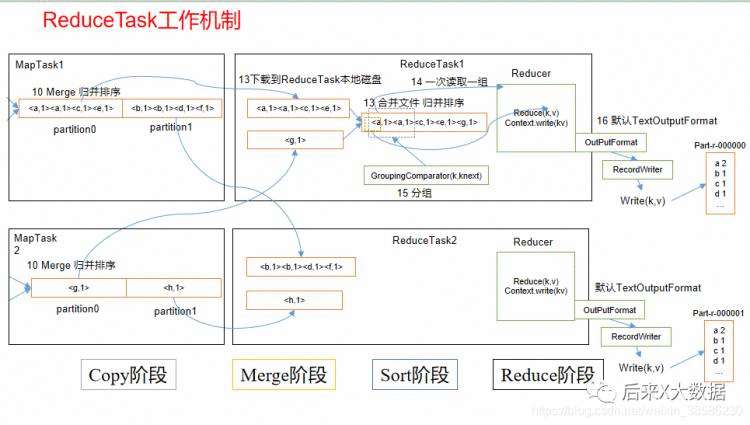 MR将一个算法抽象成Map和Reduce两个阶段进行处理,如果一个HQL经过转化可能有多个job,那么在这中间文件就有多次落盘,速度较慢。
MR将一个算法抽象成Map和Reduce两个阶段进行处理,如果一个HQL经过转化可能有多个job,那么在这中间文件就有多次落盘,速度较慢。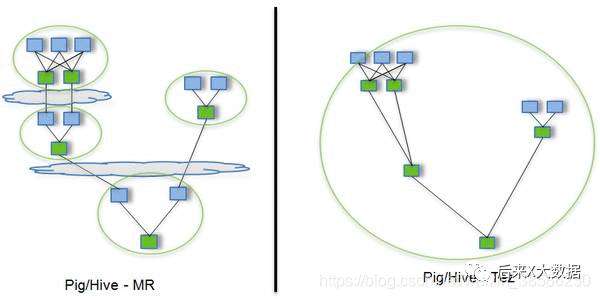 Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能
Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能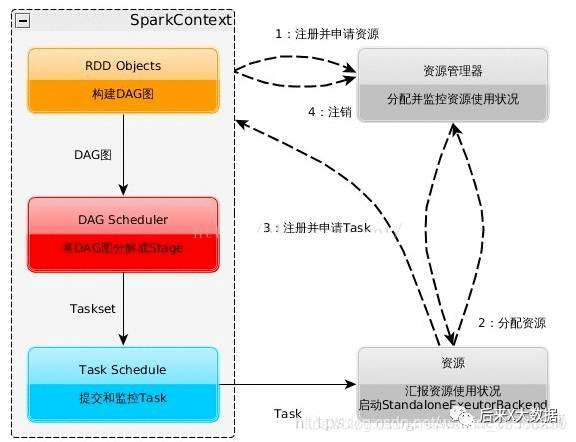






![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号
京公网安备 11010802041100号