作者:手机用户2502881375 | 来源:互联网 | 2023-09-01 13:18
hbase是bigtable的开源java版本。是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统。本文讲述在三台主机上安装Hbase集群的
hbase是bigtable的开源java版本。是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统。本文讲述在三台主机上安装Hbase集群的主要步骤
主要内容:
- 1.Hbase架构图
- 2.Hbase安装
- 3.基本操作
1.Hbase构架图

2.Hbase安装
下载地址:传送门
| 用户 | 主机名 | ip | 安装的软件 | 进程 |
|---|
| hadoop | hadoop1 | 192.168.2.111 | jdk、hadoop、zk、hbase | namenode、QuorumPeerMain、HMaster |
| hadoop | hadoop2 | 192.168.2.112 | jdk、hadoop、zk、hbase | datanode、secondnamenode、QuorumPeerMain、HRegionServer |
| hadoop | hadoop3 | 192.168.2.113 | jdk、hadoop、zk、hbase | datanade、QuorumPeerMain、HRegionServer |
2.1.上传解压
tar -zxvf hbase-1.2.6-bin.tar.gz -C /opt/soft
2.2.拷贝配置文件
要把hadoop/conf下的hdfs-site.xml和core-site.xml拷贝到hbase/conf下
cp /opt/soft/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /opt/soft/hbase-1.2.6/conf/
cp /opt/soft/hadoop-2.7.3/etc/hadoop/core-site.xml /opt/soft/hbase-1.2.6/conf/
2.3.修改配置文件(3个)
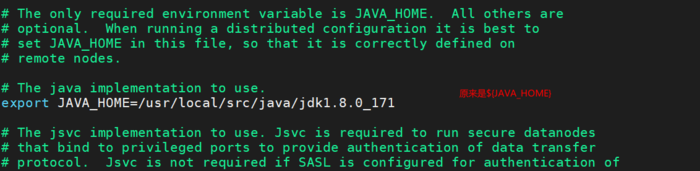
hbase-env.sh
export JAVA_HOME=/opt/soft/jdk1.8.0_91
//使用外部的zookeeper
export HBASE_MANAGES_ZK=false
hbase-site.xml
hbase.rootdir
hdfs://hadoop1:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181
hbase.master.info.port
60010
regionservers
hadoop2
hadoop3
并拷贝到其它主机
scp -r hbase-1.2.6/ hadoop@hadoop2:/opt/soft
scp -r hbase-1.2.6/ hadoop@hadoop3:/opt/soft
2.4.启动
1.启动zookeeper集群
2.启动hdfs集群
3.启动hbase(hadoop1)
bin/start-hbase.sh
访问hadoop1:60010

3.基本操作
3.1.进入hbase shell
./bin/hbase shell
3.2.显示hbase中的所有表
list
3.3.创建表
create 'user','base_info'
3.4.插入数据
put 'user','rowkey_10','base_info:username','张三'
put 'user','rowkey_10','base_info:birthday','2014-07-10'
put 'user','rowkey_10','base_info:sex','1'
put 'user','rowkey_10','base_info:address','北京市'
put 'user','rowkey_16','base_info:username','张小明'
put 'user','rowkey_16','base_info:birthday','2014-07-10'
put 'user','rowkey_16','base_info:sex','1'
put 'user','rowkey_16','base_info:address','北京'
put 'user','rowkey_22','base_info:username','陈小明'
put 'user','rowkey_22','base_info:birthday','2014-07-10'
put 'user','rowkey_22','base_info:sex','1'
put 'user','rowkey_22','base_info:address','上海'
put 'user','rowkey_24','base_info:username','张三丰'
put 'user','rowkey_24','base_info:birthday','2014-07-10'
put 'user','rowkey_24','base_info:sex','1'
put 'user','rowkey_24','base_info:address','河南'
put 'user','rowkey_25','base_info:username','陈大明'
put 'user','rowkey_25','base_info:birthday','2014-07-10'
put 'user','rowkey_25','base_info:sex','1'
put 'user','rowkey_25','base_info:address','西安'
3.5.查询表中的所有数据
scan 'user'
3.6.查询某个rowkey的数据
get 'user','rowkey_16'
3.7.查询某个列簇的数据
get 'user','rowkey_16','base_info'
get 'user','rowkey_16','base_info:username'
get 'user', 'rowkey_16', {COLUMN => ['base_info:username','base_info:sex']}
3.8.删除表中的数据
delete 'user', 'rowkey_16', 'base_info:username'
3.9.清空数据
truncate 'user'
3.10.操作列簇
alter 'user', NAME => 'f2'
alter 'user', 'delete' => 'f2'
3.11.删除表
disable 'user'
drop 'user'
3.12.其它










 京公网安备 11010802041100号
京公网安备 11010802041100号