简介
hbase是bigtable的开源java版本。是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。
主要用来存储结构化和半结构化的松散数据。
Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务)
Hbase中支持的数据类型:byte[]
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase中的表一般有这样的特点:
HBase的发展历程
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
结构:
功能:
结构:
功能:
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
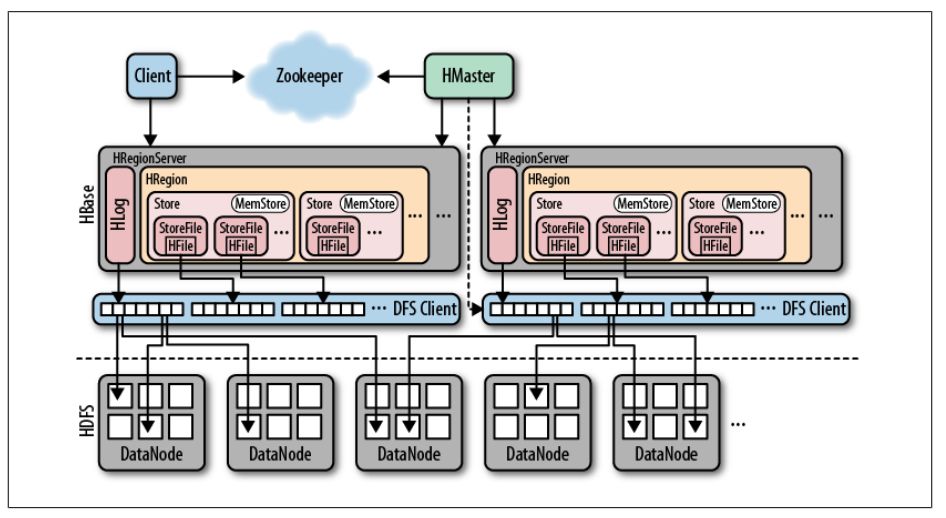
功能:
监控RegionServer
处理RegionServer故障转移
处理元数据的变更
处理region的分配或移除
在空闲时间进行数据的负载均衡
通过Zookeeper发布自己的位置给客户端
功能:
负责存储HBase的实际数据
处理分配给它的Region
刷新缓存到HDFS
维护HLog
执行压缩
负责处理Region分片
组件:
1) Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5) Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
注意事项:Hbase强依赖于HDFS以及zookeeper,所以安装Hbase之前一定要保证Hadoop和zookeeper正常启动
下载Hbase的安装包,下载地址如下:
http://archive.apache.org/dist/hbase/2.0.0/hbase-2.0.0-bin.tar.gz
将我们的压缩包上传到node01服务器的/export/softwares路径下并解压
cd /export/softwares/
tar -zxf hbase-2.0.0-bin.tar.gz -C /export/servers/
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
node01机器进行修改配置文件
注释掉HBase使用内部zk
cd /export/servers/hbase-2.0.0/conf
vim hbase-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
node01机器进行修改配置文件
修改hbase-site.xml
cd /export/servers/hbase-2.0.0/conf
vim hbase-site.xml
hbase.rootdir
hdfs://node01:8020/hbase
hbase.cluster.distributed
true
hbase.master.port
16000
hbase.zookeeper.quorum
node01:2181,node02:2181,node03:2181
hbase.zookeeper.property.dataDir
/export/servers/zookeeper-3.4.9/zkdatas
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
vim regionservers
node01
node02
node03
node01机器进行修改配置文件
cd /export/servers/hbase-2.0.0/conf
vim backup-masters
node02
将我们node01服务器的hbase的安装包拷贝到其他机器上面去
cd /export/servers/
scp -r hbase-2.0.0/ node02:$PWD
scp -r hbase-2.0.0/ node03:$PWD
因为hbase需要读取hadoop的core-site.xml以及hdfs-site.xml当中的配置文件信息,所以我们三台机器都要执行以下命令创建软连接
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /export/servers/hbase-2.0.0/conf/core-site.xml
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /export/servers/hbase-2.0.0/conf/hdfs-site.xml
三台机器执行以下命令,添加HBASE_HOME环境变量
vim /etc/profile
export HBASE_HOME=/export/servers/hbase-2.0.0
export PATH=:HBASEHOME/bin:HBASE_HOME/bin:HBASEHOME/bin:PATH
第一台机器执行以下命令进行启动
cd /export/servers/hbase-2.0.0
bin/start-hbase.sh
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告

我们可以只是掉所有机器的hbase-env.sh当中的
“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 来解决这个问题。不过警告不影响我们正常运行,可以不用解决
另外一种启动方式:
我们也可以执行以下命令单节点进行启动
启动HMaster命令
bin/hbase-daemon.sh start master
启动HRegionServer命令
bin/hbase-daemon.sh start regionserver
浏览器页面访问
http://node01:16010/master-status

node01服务器执行以下命令进入hbase的shell客户端
cd /export/servers/hbase-2.0.0
bin/hbase shell
hbase(main):001:0> help
hbase(main):002:0> list
创建user表,包含info、data两个列族
hbase(main):010:0> create ‘user’, ‘info’, ‘data’
或者
hbase(main):010:0> create ‘user’, {NAME => ‘info’, VERSIONS => ‘3’},{NAME => ‘data’}
向user表中插入信息,row key为rk0001,列族info中添加name列标示符,值为zhangsan
hbase(main):011:0> put ‘user’, ‘rk0001’, ‘info:name’, ‘zhangsan’
向user表中插入信息,row key为rk0001,列族info中添加gender列标示符,值为female
hbase(main):012:0> put ‘user’, ‘rk0001’, ‘info:gender’, ‘female’
向user表中插入信息,row key为rk0001,列族info中添加age列标示符,值为20
hbase(main):013:0> put ‘user’, ‘rk0001’, ‘info:age’, 20
向user表中插入信息,row key为rk0001,列族data中添加pic列标示符,值为picture
hbase(main):014:0> put ‘user’, ‘rk0001’, ‘data:pic’, ‘picture’
获取user表中row key为rk0001的所有信息
hbase(main):015:0> get ‘user’, ‘rk0001’
获取user表中row key为rk0001,info列族的所有信息
hbase(main):016:0> get ‘user’, ‘rk0001’, ‘info’
获取user表中row key为rk0001,info列族的name、age列标示符的信息
hbase(main):017:0> get ‘user’, ‘rk0001’, ‘info:name’, ‘info:age’
获取user表中row key为rk0001,info、data列族的信息
hbase(main):018:0> get ‘user’, ‘rk0001’, ‘info’, ‘data’
或者你也可以这样写
hbase(main):019:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info’, ‘data’]}
或者你也可以这样写,也行
hbase(main):020:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info:name’, ‘data:pic’]}
获取user表中row key为rk0001,cell的值为zhangsan的信息
hbase(main):030:0> get ‘user’, ‘rk0001’, {FILTER => “ValueFilter(=, ‘binary:zhangsan’)”}
获取user表中row key为rk0001,列标示符中含有a的信息
hbase(main):031:0> get ‘user’, ‘rk0001’, {FILTER => “(QualifierFilter(=,‘substring:a’))”}
继续插入一批数据
hbase(main):032:0> put ‘user’, ‘rk0002’, ‘info:name’, ‘fanbingbing’
hbase(main):033:0> put ‘user’, ‘rk0002’, ‘info:gender’, ‘female’
hbase(main):034:0> put ‘user’, ‘rk0002’, ‘info:nationality’, ‘中国’
hbase(main):035:0> get ‘user’, ‘rk0002’, {FILTER => “ValueFilter(=, ‘binary:中国’)”}
查询user表中的所有信息
scan ‘user’
查询user表中列族为info的信息
scan ‘user’, {COLUMNS => ‘info’}
scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 5}
scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 3}
查询user表中列族为info和data的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’]}
scan ‘user’, {COLUMNS => [‘info:name’, ‘data:pic’]}
查询user表中列族为info、列标示符为name的信息
scan ‘user’, {COLUMNS => ‘info:name’}
查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan ‘user’, {COLUMNS => ‘info:name’, VERSIONS => 5}
查询user表中列族为info和data且列标示符中含有a字符的信息
scan ‘user’, {COLUMNS => [‘info’, ‘data’], FILTER => “(QualifierFilter(=,‘substring:a’))”}
查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan ‘user’, {COLUMNS => ‘info’, STARTROW => ‘rk0001’, ENDROW => ‘rk0003’}
查询user表中row key以rk字符开头的
scan ‘user’,{FILTER=>“PrefixFilter(‘rk’)”}
查询user表中指定范围的数据
scan ‘user’, {TIMERANGE => [1392368783980, 1392380169184]}
更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
将user表的f1列族版本号改为5
hbase(main):050:0> alter ‘user’, NAME => ‘info’, VERSIONS => 5
删除user表row key为rk0001,列标示符为info:name的数据
hbase(main):045:0> delete ‘user’, ‘rk0001’, ‘info:name’
删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete ‘user’, ‘rk0001’, ‘info:name’, 1392383705316
删除一个列族:
alter ‘user’, NAME => ‘info’, METHOD => ‘delete’
或 alter ‘user’, ‘delete’ => ‘info’
hbase(main):017:0> truncate ‘user’
首先需要先让该表为disable状态,使用命令:
hbase(main):049:0> disable ‘user’
然后才能drop这个表,使用命令:
hbase(main):050:0> drop ‘user’
(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
hbase(main):053:0> count ‘user’
例如:显示服务器状态
hbase(main):058:0> status ‘node01’
显示HBase当前用户,例如:
hbase> whoami
显示当前所有的表
统计指定表的记录数,例如:
hbase> count ‘user’
展示表结构信息
检查表是否存在,适用于表量特别多的情况
检查表是否启用或禁用
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
hbase> alter ‘user’, NAME => ‘CF2’, VERSIONS => 2
为当前表删除列族:
hbase(main):002:0> alter ‘user’, ‘delete’ => ‘CF2’
禁用一张表/启用一张表
删除一张表,记得在删除表之前必须先禁用
禁用表-删除表-创建表
熟练掌握通过使用java代码实现HBase数据库当中的数据增删改查的操作,特别是各种查询,熟练运用
org.apache.hbase
hbase-client
2.0.0
org.apache.hbase
hbase-server
2.0.0
junit
junit
4.12
test
org.testng
testng
6.14.3
test
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.81.8
UTF-8
@Test
public void createTable() throws IOException {
//创建配置文件对象,并指定zookeeper的连接地址
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.property.clientPort”, “2181”);
configuration.set(“hbase.zookeeper.quorum”, “node01,node02,node03”);
//集群配置↓
//configuration.set(“hbase.zookeeper.quorum”, “101.236.39.141,101.236.46.114,101.236.46.113”);
configuration.set(“hbase.master”, “node01:60000”);
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
//通过HTableDescriptor来实现我们表的参数设置,包括表名,列族等等
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(“myuser”));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor(“f1”));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor(“f2”));
//创建表
boolean myuser = admin.tableExists(TableName.valueOf(“myuser”));
if(!myuser){
admin.createTable(hTableDescriptor);
}
//关闭客户端连接
admin.close();
}
/**
@Test
public void addDatas() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”, “node01:2181,node02:2181”);
Connection connection = ConnectionFactory.createConnection(configuration);
//获取表
Table myuser = connection.getTable(TableName.valueOf(“myuser”));
//创建put对象,并指定rowkey
Put put = new Put(“0001”.getBytes());
put.addColumn(“f1”.getBytes(),“id”.getBytes(), Bytes.toBytes(1));
put.addColumn(“f1”.getBytes(),“name”.getBytes(), Bytes.toBytes(“张三”));
put.addColumn(“f1”.getBytes(),“age”.getBytes(), Bytes.toBytes(18));
put.addColumn(“f2”.getBytes(),“address”.getBytes(), Bytes.toBytes(“地球人”));
put.addColumn(“f2”.getBytes(),“phone”.getBytes(), Bytes.toBytes(“15874102589”));
//插入数据
myuser.put(put);
//关闭表
myuser.close();
}
@Test
public void insertBatchData() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”, “node01:2181,node02:2181”);
Connection connection = ConnectionFactory.createConnection(configuration);
//获取表
Table myuser = connection.getTable(TableName.valueOf(“myuser”));
//创建put对象,并指定rowkey
Put put = new Put(“0002”.getBytes());
put.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(1));
put.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“曹操”));
put.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(30));
put.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“沛国谯县”));
put.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“16888888888”));
put.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“helloworld”));
Put put2 = new Put(“0003”.getBytes());
put2.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(2));
put2.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“刘备”));
put2.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(32));
put2.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put2.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“幽州涿郡涿县”));
put2.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“17888888888”));
put2.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“talk is cheap , show me the code”));
Put put3 = new Put(“0004”.getBytes());
put3.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(3));
put3.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“孙权”));
put3.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(35));
put3.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put3.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“下邳”));
put3.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“12888888888”));
put3.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“what are you 弄啥嘞!”));
Put put4 = new Put(“0005”.getBytes());
put4.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(4));
put4.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“诸葛亮”));
put4.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(28));
put4.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put4.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“四川隆中”));
put4.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“14888888888”));
put4.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“出师表你背了嘛”));
Put put5 = new Put(“0005”.getBytes());
put5.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(5));
put5.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“司马懿”));
put5.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(27));
put5.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put5.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“哪里人有待考究”));
put5.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“15888888888”));
put5.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“跟诸葛亮死掐”));
Put put6 = new Put(“0006”.getBytes());
put6.addColumn(“f1”.getBytes(),“id”.getBytes(),Bytes.toBytes(5));
put6.addColumn(“f1”.getBytes(),“name”.getBytes(),Bytes.toBytes(“xiaobubu—吕布”));
put6.addColumn(“f1”.getBytes(),“age”.getBytes(),Bytes.toBytes(28));
put6.addColumn(“f2”.getBytes(),“sex”.getBytes(),Bytes.toBytes(“1”));
put6.addColumn(“f2”.getBytes(),“address”.getBytes(),Bytes.toBytes(“内蒙人”));
put6.addColumn(“f2”.getBytes(),“phone”.getBytes(),Bytes.toBytes(“15788888888”));
put6.addColumn(“f2”.getBytes(),“say”.getBytes(),Bytes.toBytes(“貂蝉去哪了”));
List listPut = new ArrayList();
listPut.add(put);
listPut.add(put2);
listPut.add(put3);
listPut.add(put4);
listPut.add(put5);
listPut.add(put6);
myuser.put(listPut);
myuser.close();
}
查询主键rowkey为0003的人
/**
@Test
public void searchData() throws IOException {
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf(“myuser”));
Get get = new Get(Bytes.toBytes(“0003”));
Result result = myuser.get(get);
Cell[] cells = result.rawCells();
//获取所有的列名称以及列的值
for (Cell cell : cells) {
//注意,如果列属性是int类型,那么这里就不会显示
System.out.println(Bytes.toString(cell.getQualifierArray(),cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println(Bytes.toString(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength()));
}
myuser.close();
}
需求一:查询f1列族下面所有列的值
需求二:查询f1列族下面id列的值
//通过rowKey进行查询
Get get = new Get(“0003”.getBytes());
//get.addFamily(“f1”.getBytes());
get.addColumn(“f1”.getBytes(),“id”.getBytes());
/**
@Test
public void scanRowKey() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf(“myuser”));
Scan scan = new Scan();
scan.setStartRow(“0004”.getBytes());
scan.setStopRow(“0006”.getBytes());
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//获取rowkey
System.out.println(Bytes.toString(result.getRow()));
//遍历获取得到所有的列族以及所有的列的名称
KeyValue[] raw = result.raw();
for (KeyValue keyValue : raw) {
//获取所属列族
System.out.println(Bytes.toString(keyValue.getFamilyArray(),keyValue.getFamilyOffset(),keyValue.getFamilyLength()));
System.out.println(Bytes.toString(keyValue.getQualifierArray(),keyValue.getQualifierOffset(),keyValue.getQualifierLength()));
}
//指定列族以及列打印列当中的数据出来
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “id”.getBytes())));
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “age”.getBytes())));
System.out.println(Bytes.toString(result.getValue(“f1”.getBytes(), “name”.getBytes())));
}
myuser.close();
}
/**
@Test
public void scanAllData() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection = ConnectionFactory.createConnection(configuration);
Table myuser = connection.getTable(TableName.valueOf(“myuser”));
Scan scan = new Scan();
ResultScanner resultScanner = myuser.getScanner(scan);
for (Result result : resultScanner) {
//获取rowkey
System.out.println(Bytes.toString(result.getRow()));
//指定列族以及列打印列当中的数据出来
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “id”.getBytes())));
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “age”.getBytes())));
System.out.println(Bytes.toString(result.getValue(“f1”.getBytes(), “name”.getBytes())));
}
myuser.close();
}
过滤器的类型很多,但是可以分为两大类——比较过滤器,专用过滤器
过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端;
hbase过滤器的比较运算符:
LESS <
LESS_OR_EQUAL <&#61;
EQUAL &#61;
NOT_EQUAL <>
GREATER_OR_EQUAL >&#61;
GREATER >
NO_OP 排除所有
Hbase过滤器的比较器&#xff08;指定比较机制&#xff09;&#xff1a;
BinaryComparator 按字节索引顺序比较指定字节数组&#xff0c;采用Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同&#xff0c;只是比较左端的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器&#xff0c;仅支持 EQUAL 和非EQUAL
SubstringComparator 判断提供的子串是否出现在value中。
通过RowFilter过滤比rowKey 0003小的所有值出来
/**
&#64;Test
public void rowKeyFilter() throws IOException {
//获取连接
Configuration configuration &#61; HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection &#61; ConnectionFactory.createConnection(configuration);
Table myuser &#61; connection.getTable(TableName.valueOf(“myuser”));
Scan scan &#61; new Scan();
RowFilter rowFilter &#61; new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes(“0003”)));
scan.setFilter(rowFilter);
ResultScanner resultScanner &#61; myuser.getScanner(scan);
for (Result result : resultScanner) {
//获取rowkey
System.out.println(Bytes.toString(result.getRow()));
//指定列族以及列打印列当中的数据出来
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “id”.getBytes())));
System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “age”.getBytes())));
System.out.println(Bytes.toString(result.getValue(“f1”.getBytes(), “name”.getBytes())));
}
myuser.close();
}
查询比f2列族小的所有的列族内的数据
FamilyFilter familyFilter &#61; new FamilyFilter(CompareFilter.CompareOp.LESS, new SubstringComparator(“f2”));
scan.setFilter(familyFilter);
只查询name列的值
QualifierFilter qualifierFilter &#61; new QualifierFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(“name”));
scan.setFilter(qualifierFilter);
查询所有列当中包含8的数据
ValueFilter valueFilter &#61; new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(“8”));
scan.setFilter(valueFilter);
SingleColumnValueFilter会返回满足条件数据的所有字段
需求&#xff1a;查询name值为 刘备 的数据
SingleColumnValueFilter singleColumnValueFilter &#61; new SingleColumnValueFilter(“f1”.getBytes(), “name”.getBytes(), CompareOperator.EQUAL, “刘备”.getBytes());
scan.setFilter(singleColumnValueFilter);
与SingleColumnValueFilter相反&#xff0c;会排除掉指定的列&#xff0c;其他的列全部返回
需求&#xff1a;查询以00开头的所有前缀的rowkey
PrefixFilter prefixFilter &#61; new PrefixFilter(“00”.getBytes());
scan.setFilter(prefixFilter);
通过pageFilter实现分页过滤器
&#64;Test
public void pageFilter2() throws IOException {
//获取连接
Configuration configuration &#61; HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”, “node01:2181,node02:2181,node03:2181”);
Connection connection &#61; ConnectionFactory.createConnection(configuration);
Table myuser &#61; connection.getTable(TableName.valueOf(“myuser”));
int pageNum &#61; 3;
int pageSize &#61; 2;
Scan scan &#61; new Scan();
if (pageNum &#61;&#61; 1) {
PageFilter filter &#61; new PageFilter(pageSize);
scan.setStartRow(Bytes.toBytes(""));
scan.setFilter(filter);
scan.setMaxResultSize(pageSize);
ResultScanner scanner &#61; myuser.getScanner(scan);
for (Result result : scanner) {
//获取rowkey
System.out.println(Bytes.toString(result.getRow()));
//指定列族以及列打印列当中的数据出来
// System.out.println(Bytes.toInt(result.getValue(“f1”.getBytes(), “id”.getBytes())));
System.out.println(Bytes.toString(result.getValue(“f1”.getBytes(), “name”.getBytes())));
//System.out.println(Bytes.toString(result.getValue(“f2”.getBytes(), “phone”.getBytes())));
}
}else{
String startRowKey &#61;"";
PageFilter filter &#61; new PageFilter((pageNum - 1) * pageSize &#43; 1 );
scan.setStartRow(startRowKey.getBytes());
scan.setMaxResultSize((pageNum - 1) * pageSize &#43; 1);
scan.setFilter(filter);
ResultScanner scanner &#61; myuser.getScanner(scan);
for (Result result : scanner) {
byte[] row &#61; result.getRow();
startRowKey &#61; new String(row);
}
Scan scan2 &#61; new Scan();
scan2.setStartRow(startRowKey.getBytes());
scan2.setMaxResultSize(Long.valueOf(pageSize));
PageFilter filter2 &#61; new PageFilter(pageSize);
scan2.setFilter(filter2);
ResultScanner scanner1 &#61; myuser.getScanner(scan2);
for (Result result : scanner1) {
byte[] row &#61; result.getRow();
System.out.println(new String(row));
}
}
myuser.close();
}
需求&#xff1a;使用SingleColumnValueFilter查询f1列族&#xff0c;name为刘备的数据&#xff0c;并且同时满足rowkey的前缀以00开头的数据&#xff08;PrefixFilter&#xff09;
FilterList filterList &#61; new FilterList();
SingleColumnValueFilter singleColumnValueFilter &#61; new SingleColumnValueFilter(“f1”.getBytes(), “name”.getBytes(), CompareFilter.CompareOp.EQUAL, “刘备”.getBytes());
PrefixFilter prefixFilter &#61; new PrefixFilter(“00”.getBytes());
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(prefixFilter);
scan.setFilter(filterList);
/**
&#64;Test
public void deleteByRowKey() throws IOException {
//获取连接
Configuration configuration &#61; HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection &#61; ConnectionFactory.createConnection(configuration);
Table myuser &#61; connection.getTable(TableName.valueOf(“myuser”));
Delete delete &#61; new Delete(“0001”.getBytes());
myuser.delete(delete);
myuser.close();
}
&#64;Test
public void deleteTable() throws IOException {
//获取连接
Configuration configuration &#61; HBaseConfiguration.create();
configuration.set(“hbase.zookeeper.quorum”,“node01:2181,node02:2181,node03:2181”);
Connection connection &#61; ConnectionFactory.createConnection(configuration);
Admin admin &#61; connection.getAdmin();
admin.disableTable(TableName.valueOf(“myuser”));
admin.deleteTable(TableName.valueOf(“myuser”));
admin.close();
}
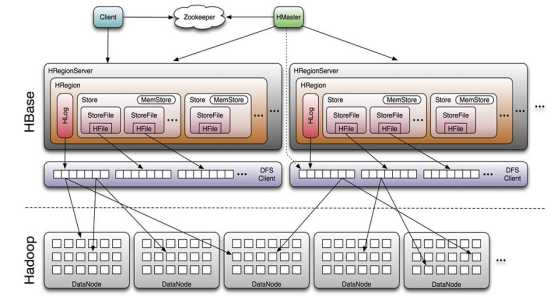
Client
1 包含访问hbase的接口&#xff0c;client维护着一些cache来加快对hbase的访问&#xff0c;比如regione的位置信息。
Zookeeper
1 保证任何时候&#xff0c;集群中只有一个master
2 存贮所有Region的寻址入口
3 实时监控Region Server的状态&#xff0c;将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table&#xff0c;每个table有哪些column family
Master职责
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 HDFS上的垃圾文件回收
5 处理schema更新请求
Region Server职责
1 Region server维护Master分配给它的region&#xff0c;处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
可以看到&#xff0c;client访问hbase上数据的过程并不需要master参与&#xff08;寻址访问zookeeper和region server&#xff0c;数据读写访问regione server&#xff09;&#xff0c;master仅仅维护者table和region的元数据信息&#xff0c;负载很低。

与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行&#xff0c;只有三种方式&#xff1a;
1 通过单个row key访问
2 通过row key的range
3 全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB&#xff0c;实际应用中长度一般为 10-100bytes)&#xff0c;在hbase内部&#xff0c;row key保存为字节数组。
Hbase会对表中的数据按照rowkey排序(字典顺序)
存储时&#xff0c;数据按照Row key的字典序(byte order)排序存储。设计key时&#xff0c;要充分排序存储这个特性&#xff0c;将经常一起读取的行存储放到一起。(位置相关性)
注意&#xff1a;
字典序对int排序的结果是
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序&#xff0c;行键必须用0作左填充。
行的一次读写是原子操作 (不论一次读写多少列)。这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
hbase表中的每个列&#xff0c;都归属与某个列族。列族是表的schema的一部分(而列不是)&#xff0c;必须在使用表之前定义。
列名都以列族作为前缀。例如courses:history &#xff0c; courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。
列族越多&#xff0c;在取一行数据时所要参与IO、搜寻的文件就越多&#xff0c;所以&#xff0c;如果没有必要&#xff0c;不要设置太多的列族
列族下面的具体列&#xff0c;属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
列是插入数据的时候动态指定的
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值&#xff0c;此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突&#xff0c;就必须自己生成具有唯一性的时间戳。每个 cell中&#xff0c;不同版本的数据按照时间倒序排序&#xff0c;即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担&#xff0c;hbase提供了两种数据版本回收方式&#xff1a;
用户可以针对每个列族进行设置。
由{row key, column( &#61; &#43;
cell中的数据是没有类型的&#xff0c;全部是字节码形式存贮。
数据的版本号&#xff0c;每条数据可以有多个版本号&#xff0c;默认值为系统时间戳&#xff0c;类型为Long
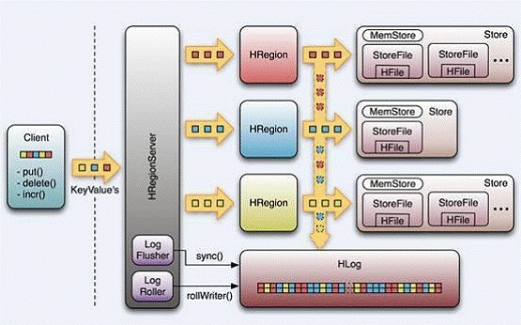
1 Table中的所有行都按照row key的字典序排列。
2 Table 在行的方向上分割为多个Hregion。
3 region按大小分割的(默认10G)&#xff0c;每个表一开始只有一个region&#xff0c;随着数据不断插入表&#xff0c;region不断增大&#xff0c;当增大到一个阀值的时候&#xff0c;Hregion就会等分会两个新的Hregion。当table中的行不断增多&#xff0c;就会有越来越多的Hregion。
4 Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
5 HRegion虽然是负载均衡的最小单元&#xff0c;但并不是物理存储的最小单元。
事实上&#xff0c;HRegion由一个或者多个Store组成&#xff0c;每个store保存一个column family。
每个Strore又由一个memStore和0至多个StoreFile组成。如上图
StoreFile以HFile格式保存在HDFS上。
附&#xff1a;HFile的格式为&#xff1a;
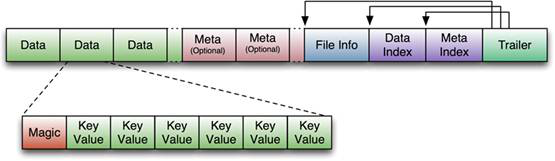
首先HFile文件是不定长的&#xff0c;长度固定的只有其中的两块&#xff1a;Trailer和FileInfo。正如图中所示的&#xff0c;Trailer中有指针指向其他数 据块的起始点。
File Info中记录了文件的一些Meta信息&#xff0c;例如&#xff1a;AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元&#xff0c;为了提高效率&#xff0c;HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定&#xff0c;大号的Block有利于顺序Scan&#xff0c;小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字&#xff0c;目的是防止数据损坏。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项&#xff0c;并且有固定的结构。我们来看看里面的具体结构&#xff1a;

开始是两个固定长度的数值&#xff0c;分别表示Key的长度和Value的长度。紧接着是Key&#xff0c;开始是固定长度的数值&#xff0c;表示RowKey的长度&#xff0c;紧接着是 RowKey&#xff0c;然后是固定长度的数值&#xff0c;表示Family的长度&#xff0c;然后是Family&#xff0c;接着是Qualifier&#xff0c;然后是两个固定长度的数值&#xff0c;表示Time Stamp和Key Type&#xff08;Put/Delete&#xff09;。Value部分没有这么复杂的结构&#xff0c;就是纯粹的二进制数据了。
HFile分为六个部分&#xff1a;
Data Block 段–保存表中的数据&#xff0c;这部分可以被压缩
Meta Block 段 (可选的)–保存用户自定义的kv对&#xff0c;可以被压缩。
File Info 段–Hfile的元信息&#xff0c;不被压缩&#xff0c;用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer–这一段是定长的。保存了每一段的偏移量&#xff0c;读取一个HFile时&#xff0c;会首先 读取Trailer&#xff0c;Trailer保存了每个段的起始位置(段的Magic Number用来做安全check)&#xff0c;然后&#xff0c;DataBlock Index会被读取到内存中&#xff0c;这样&#xff0c;当检索某个key时&#xff0c;不需要扫描整个HFile&#xff0c;而只需从内存中找到key所在的block&#xff0c;通过一次磁盘io将整个 block读取到内存中&#xff0c;再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block&#xff0c;Meta Block通常采用压缩方式存储&#xff0c;压缩之后可以大大减少网络IO和磁盘IO&#xff0c;随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式&#xff1a;Gzip&#xff0c;Lzo。
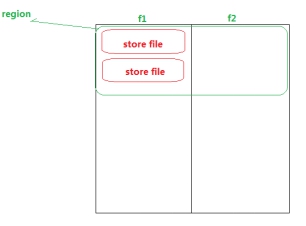
一个region由多个store组成&#xff0c;每个store包含一个列族的所有数据
Store包括位于内存的memstore和位于硬盘的storefile
写操作先写入memstore,当memstore中的数据量达到某个阈值&#xff0c;Hregionserver启动flashcache进程写入storefile,每次写入形成单独一个storefile
当storefile大小超过一定阈值后&#xff0c;会把当前的region分割成两个&#xff0c;并由Hmaster分配给相应的region服务器&#xff0c;实现负载均衡
客户端检索数据时&#xff0c;先在memstore找&#xff0c;找不到再找storefile
WAL 意为Write ahead log(http://en.wikipedia.org/wiki/Write-ahead_logging)&#xff0c;类似mysql中的binlog,用来 做灾难恢复时用&#xff0c;Hlog记录数据的所有变更,一旦数据修改&#xff0c;就可以从log中进行恢复。
每个Region Server维护一个Hlog,而不是每个Region一个。这样不同region(来自不同table)的日志会混在一起&#xff0c;这样做的目的是不断追加单个文件相对于同时写多个文件而言&#xff0c;可以减少磁盘寻址次数&#xff0c;因此可以提高对table的写性能。带来的麻烦是&#xff0c;如果一台region server下线&#xff0c;为了恢复其上的region&#xff0c;需要将region server上的log进行拆分&#xff0c;然后分发到其它region server上进行恢复。
HLog文件就是一个普通的Hadoop Sequence File&#xff1a;
HRegionServer保存着meta表以及表数据&#xff0c;要访问表数据&#xff0c;首先Client先去访问zookeeper&#xff0c;从zookeeper里面获取meta表所在的位置信息&#xff0c;即找到这个meta表在哪个HRegionServer上保存着。
接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer&#xff0c;从而读取到Meta&#xff0c;进而获取到Meta表中存放的元数据。
Client通过元数据中存储的信息&#xff0c;访问对应的HRegionServer&#xff0c;然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
最后HRegionServer把查询到的数据响应给Client。
查看meta表信息
hbase(main):011:0> scan ‘hbase:meta’
Client也是先访问zookeeper&#xff0c;找到Meta表&#xff0c;并获取Meta表元数据。
确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
Client向该HRegionServer服务器发起写入数据请求&#xff0c;然后HRegionServer收到请求并响应。
Client先把数据写入到HLog&#xff0c;以防止数据丢失。
然后将数据写入到Memstore。
如果HLog和Memstore均写入成功&#xff0c;则这条数据写入成功
如果Memstore达到阈值&#xff0c;会把Memstore中的数据flush到Storefile中。
当Storefile越来越多&#xff0c;会触发Compact合并操作&#xff0c;把过多的Storefile合并成一个大的HFile。
当HFile越来越大&#xff0c;Region也会越来越大&#xff0c;达到阈值后&#xff0c;会触发Split操作&#xff0c;将Region一分为二。
细节描述&#xff1a;
hbase使用MemStore和StoreFile存储对表的更新。
数据在更新时首先写入Log(WAL log)和内存(MemStore)中&#xff0c;MemStore中的数据是排序的&#xff0c;当MemStore累计到一定阈值时&#xff0c;就会创建一个新的MemStore&#xff0c;并 且将老的MemStore添加到flush队列&#xff0c;由单独的线程flush到磁盘上&#xff0c;成为一个StoreFile。于此同时&#xff0c;系统会在zookeeper中记录一个redo point&#xff0c;表示这个时刻之前的变更已经持久化了。
当系统出现意外时&#xff0c;可能导致内存(MemStore)中的数据丢失&#xff0c;此时使用Log(WAL log)来恢复checkpoint之后的数据。
StoreFile是只读的&#xff0c;一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后&#xff0c;就会进行一次合并(minor_compact, major_compact),将对同一个key的修改合并到一起&#xff0c;形成一个大的StoreFile&#xff0c;当StoreFile的大小达到一定阈值后&#xff0c;又会对 StoreFile进行split&#xff0c;等分为两个StoreFile。
由于对表的更新是不断追加的&#xff0c;compact时&#xff0c;需要访问Store中全部的 StoreFile和MemStore&#xff0c;将他们按row key进行合并&#xff0c;由于StoreFile和MemStore都是经过排序的&#xff0c;并且StoreFile带有内存中索引&#xff0c;合并的过程还是比较快。
(1) region分配
任何时刻&#xff0c;一个region只能分配给一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server&#xff0c;哪些region还没有分配。当需要分配的新的region&#xff0c;并且有一个region server上有可用空间时&#xff0c;master就给这个region server发送一个装载请求&#xff0c;把region分配给这个region server。region server得到请求后&#xff0c;就开始对此region提供服务。
(2) region server上线
master使用zookeeper来跟踪region server状态。当某个region server启动时&#xff0c;会首先在zookeeper上的server目录下建立代表自己的znode。由于master订阅了server目录上的变更消息&#xff0c;当server目录下的文件出现新增或删除操作时&#xff0c;master可以得到来自zookeeper的实时通知。因此一旦region server上线&#xff0c;master能马上得到消息。
(3) region server下线
当region server下线时&#xff0c;它和zookeeper的会话断开&#xff0c;zookeeper而自动释放代表这台server的文件上的独占锁。master就可以确定&#xff1a;
1 region server和zookeeper之间的网络断开了。
2 region server挂了。
无论哪种情况&#xff0c;region server都无法继续为它的region提供服务了&#xff0c;此时master会删除server目录下代表这台region server的znode数据&#xff0c;并将这台region server的region分配给其它还活着的同志。
master启动进行以下步骤:
1 从zookeeper上获取唯一一个代表active master的锁&#xff0c;用来阻止其它master成为master。
2 扫描zookeeper上的server父节点&#xff0c;获得当前可用的region server列表。
3 和每个region server通信&#xff0c;获得当前已分配的region和region server的对应关系。
4 扫描.META.region的集合&#xff0c;计算得到当前还未分配的region&#xff0c;将他们放入待分配region列表。
由于master只维护表和region的元数据&#xff0c;而不参与表数据IO的过程&#xff0c;master下线仅导致所有元数据的修改被冻结(无法创建删除表&#xff0c;无法修改表的schema&#xff0c;无法进行region的负载均衡&#xff0c;无法处理region 上下线&#xff0c;无法进行region的合并&#xff0c;唯一例外的是region的split可以正常进行&#xff0c;因为只有region server参与)&#xff0c;表的数据读写还可以正常进行。因此master下线短时间内对整个hbase集群没有影响。
从上线过程可以看到&#xff0c;master保存的信息全是可以冗余信息&#xff08;都可以从系统其它地方收集到或者计算出来&#xff09;
因此&#xff0c;一般hbase集群中总是有一个master在提供服务&#xff0c;还有一个以上的‘master’在等待时机抢占它的位置。
1.&#xff08;hbase.regionserver.global.memstore.size&#xff09;默认;堆大小的40%
regionServer的全局memstore的大小&#xff0c;超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写
2.&#xff08;hbase.hregion.memstore.flush.size&#xff09;默认&#xff1a;128M
单个region里memstore的缓存大小&#xff0c;超过那么整个HRegion就会flush,
3.&#xff08;hbase.regionserver.optionalcacheflushinterval&#xff09;默认&#xff1a;1h
内存中的文件在自动刷新之前能够存活的最长时间
4.&#xff08;hbase.regionserver.global.memstore.size.lower.limit&#xff09;默认&#xff1a;堆大小 * 0.4 * 0.95
有时候集群的“写负载”非常高&#xff0c;写入量一直超过flush的量&#xff0c;这时&#xff0c;我们就希望memstore不要超过一定的安全设置。在这种情况下&#xff0c;写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小, 这个大小就是默认值是堆大小 * 0.4 * 0.95&#xff0c;也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止
5.&#xff08;hbase.hregion.preclose.flush.size&#xff09;默认为&#xff1a;5M
当一个 region 中的 memstore 的大小大于这个值的时候&#xff0c;我们又触发 了 close.会先运行“pre-flush”操作&#xff0c;清理这个需要关闭的memstore&#xff0c;然后 将这个 region 下线。当一个 region 下线了&#xff0c;我们无法再进行任何写操作。 如果一个 memstore 很大的时候&#xff0c;flush 操作会消耗很多时间。“pre-flush” 操作意味着在 region 下线之前&#xff0c;会先把 memstore 清空。这样在最终执行 close 操作的时候&#xff0c;flush 操作会很快。
6.&#xff08;hbase.hstore.compactionThreshold&#xff09;默认&#xff1a;超过3个
一个store里面允许存的hfile的个数&#xff0c;超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候&#xff0c;默认情况下当超过3个hfile的时候就会 对这些文件进行合并重写为一个新文件&#xff0c;设置个数越大可以减少触发合并的时间&#xff0c;但是每次合并的时间就会越长
把小的storeFile文件合并成大的Storefile文件。
清理过期的数据&#xff0c;包括删除的数据
将数据的版本号保存为3个
当Region达到阈值&#xff0c;会把过大的Region一分为二。
默认一个HFile达到10Gb的时候就会进行切分






![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有