目录
生成一个新的数组,将原数组的元素全都转移到新的数组上
/**
* 分析:resize(2 * table.length)
* 作用:当容量不足时(容量 > 阈值),则扩容(扩到2倍)
*/
void resize(int newCapacity) {
// 1. 保存旧数组(old table)
Entry[] oldTable = table;
// 2. 保存旧容量(old capacity ),即数组长度
int oldCapacity = oldTable.length;
// 3. 若旧容量已经是系统默认最大容量了,那么将阈值设置成整型的最大值,退出
if (oldCapacity == MAXIMUM_CAPACITY) {
// 修改扩容阀值
threshold = Integer.MAX_VALUE;
return;
}
// 4. 根据新容量(2倍容量)新建1个数组,即新table
Entry[] newTable = new Entry[newCapacity];
// 5. 将旧数组上的数据(键值对)转移到新table中,从而完成扩容。initHashSeedAsNeeded(newCapacity)这个方法用来根据新的数组长度来重新初始化Hash种子
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 6. 新数组table引用到HashMap的table属性上
table = newTable;
// 7. 重新设置阈值,如果阈值超过了HashMap最大容量大小,则直接将阈值设置为 MAXIMUM_CAPACITY + 1
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
这个方法在JDK1.7中inflateTable()初始化哈希表方法和resize()扩容方法中都有出现。这个方法作用是初始化Hash种子。在JDK1.7中计算hash值的方法需要使用Hash种子来参与运算,进而提高计算出来的hash值的散列性,最大限度减少哈希冲突。下面就来简单讲一下这个方法:
* 这个方法用来根据新的数组长度来重新初始化Hash种子,好的Hash种子能提高计算Hash时结果的散列性,最大限度减少哈希冲突。
* @param capacity 根据传入的容量大小来进行重新初始化Hash种子
* @return 返回true说明已经根据传入的容量大小重新初始化了Hash种子,此时以前根据旧的Hash种子计算出来的Hash值就需要进行rehash了。
* 返回false说明并没有根据传入的容量大小进行重新初始化Hash种子
*/
final boolean initHashSeedAsNeeded(int capacity) {
// 首先会判断hashSeed是否不等于0,因为hashSeed一开始是0,所以此处是false
boolean currentAltHashing = hashSeed != 0;
// 这行代码是判断vm是否启动 且 容量到达一个值ALTERNATIVE_HASHING_THRESHOLD,这个值是可以自己去设定,不设定的话是默认的Integer.MaxValue 。 假设我们初始化容量capacity = 16,设置ALTERNATIVE_HASHING_THRESHOLD值为 3,那么这行代码会为true
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
//亦或 ^ 的意思是 不相同则返回true,此时switching=true,那么hashSeed就会重新去计算hash种子,以便计算hash时增加散列性,
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
// 重新设置了Hash种子
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
final int hash(Object k) {
// 设置了哈希种子
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// Hash种子参与到了key的Hash值计算当中
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
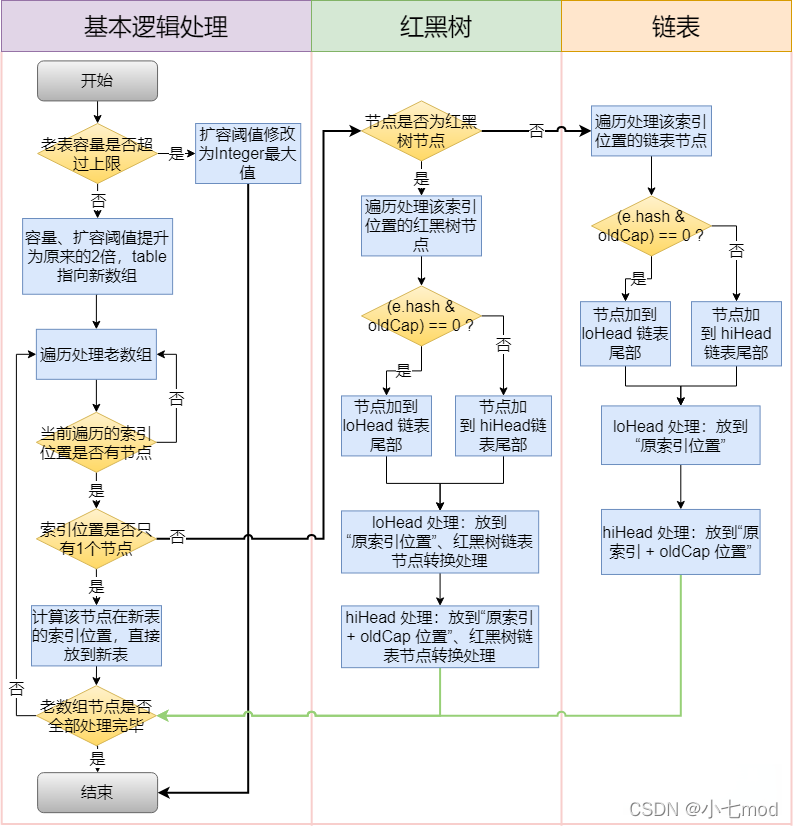
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
* 初始化或把table容量翻倍。如果table是空,则根据threshold属性的值去初始化HashMap的容
* 量。如果不为空,则进行扩容,因为我们使用2的次幂来给HashMap进行扩容,所以每个桶里的元素
* 必须保持在原来的位置或在新的table中以2的次幂作为偏移量进行移动
* @return 返回Node
*/
final Node
// 创建一个临时变量,用来存储当前的table
Node
// 获取原来的table的长度(大小),判断当前的table是否为空,如果为空,则把0赋值给新定义的oldCap,否则以table的长度作为oldCap的大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 创建临时变量用来存储旧的阈值,把旧table的阈值赋值给oldThr变量
int oldThr = threshold;
// 定义变量newCap和newThr来存放新的table的容量和阈值,默认都是0
int newCap, newThr = 0;
// 判断旧容量是否大于0
if (oldCap > 0) {
// 判断旧容量是否大于等于 允许的最大值,2^30
if (oldCap >= MAXIMUM_CAPACITY) {
// 以int的最大值作为原来HashMap的阈值,这样永远达不到阈值就不会扩容了
threshold = Integer.MAX_VALUE;
// 因为旧容量已经达到了最大的HashMap容量,不可以再扩容了,将阈值变成最大值之后,将原table返回
return oldTab;
}
// 如果原table容量不超过HashMap的最大容量,将原容量*2 赋值给变量newCap,如果newCap不大于HashMap的最大容量,并且原容量大于HashMap的默认容量
else if ((newCap = oldCap <<1)
// 将newThr的值设置为原HashMap的阈值*2
newThr = oldThr <<1; // double threshold
}
// 如果原容量不大于0,即原table为null,则判断旧阈值是否大于0
else if (oldThr > 0) // 如果原table为Null且原阈值大于0,说明当前是使用了构造方法指定了容量大小,只是声明了HashMap但是还没有真正的初始化HashMap(创建table数组),只有在向里面插入数据才会触发扩容操作进而进行初始化
// 将原阈值作为容量赋值给newCap当做newCap的值。由之前的源码分析可知,此时原阈值存储的大小就是调用构造函数时指定的容量大小,所以直接将原阈值赋值给新容量
newCap = oldThr;
// 如果原容量不大于0,并且原阈值也不大于0。这种情况说明调用的是无参构造方法,还没有真正初始化HashMap,只有put()数据的时候才会触发扩容操作进而进行初始化
else { // zero initial threshold signifies using defaults
// 则以默认容量作为newCap的值
newCap = DEFAULT_INITIAL_CAPACITY;
// 以初始容量*默认负载因子的结果作为newThr值
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 经过上面的处理过程,如果newThr值为0,说明上面是进入到了原容量不大于0,旧阈值大于0的判断分支。需要单独给newThr进行赋值
if (newThr == 0) {
// 临时阈值 = 新容量 * 负载因子
float ft = (float)newCap * loadFactor;
// 设置新的阈值 保证新容量小于最大总量 阈值要小于最大容量,否则阈值就设置为int最大值
newThr = (newCap
}
// 将新的阈值newThr赋值给threshold,为新初始化的HashMap来使用
threshold = newThr;
// 初始化一个新的容量大小为newCap的Node数组
@SuppressWarnings({"rawtypes","unchecked"})
Node
// 将新创建的数组赋值给table,完成扩容后的新数组创建
table = newTab;
// 如果旧table不为null,说明旧HashMap中有值
if (oldTab != null) {
// 如果原来的HashMap中有值,则遍历oldTab,取出每一个键值对,存入到新table
for (int j = 0; j
Node
// 将oldTab[j]赋值给e并且判断原来table数组中第j个位置是否不为空
if ((e = oldTab[j]) != null) {
// 如果不为空,则将oldTab[j]置为null,释放内存,方便gc
oldTab[j] = null;
// 如果e.next = null,说明该位置的数组桶上没有连着额外的数组
if (e.next == null)
// 此时以e.hash&(newCap-1)的结果作为e在newTab中的位置,将e直接放置在新数组的新位置即可
newTab[e.hash & (newCap - 1)] = e;
// 否则说明e的后面连接着链表或者红黑树,判断e的类型是TreeNode还是Node,即链表和红黑树判断
else if (e instanceof TreeNode)
// 如果是红黑树,则进行红黑树的处理。将Node类型的e强制转为TreeNode,之所以能转换是因为TreeNode 是Node的子类
// 拆分树,具体源码解析会在后面的TreeNode章节中讲解
((TreeNode
// 当前节不是红黑树,不是null,并且还有下一个元素。那么此时为链表
else { // preserve order
/*
这里定义了五个Node变量,其中lo和hi是,lower和higher的缩写,也就是高位和低位,
因为我们知道HashMap扩容时,容量会扩到原容量的2倍,
也就是放在链表中的Node的位置可能保持不变或位置变成 原位置+oldCap,在原位置基础上又加了一个数,位置变高了,
这里的高低位就是这个意思,低位指向的是保持原位置不变的节点,高位指向的是需要更新位置的节点
*/
// Head指向的是链表的头节点,Tail指向的是链表的尾节点
Node
Node
// 指向当前遍历到的节点的下一个节点
Node
// 循环遍历链表中的Node
do {
next = e.next;
/*
如果e.hash & oldCap == 0,注意这里是oldCap,而不是oldCap-1。
我们知道oldCap是2的次幂,也就是1、2、4、8、16...转化为二进制之后,
都是最高位为1,其它位为0。所以oldCap & e.hash 也是只有e.hash值在oldCap二进制不为0的位对应的位也不为0时,
才会得到一个不为0的结果。举个例子,我们知道10010 和00010 与1111的&运算结果都是 0010 ,
但是110010和010010与10000的运算结果是不一样的,所以HashMap就是利用这一点,
来判断当前在链表中的数据,在扩容时位置是保持不变还是位置移动oldCap。
*/
// 如果结果为0,即位置保持不变
if ((e.hash & oldCap) == 0) {
// 如果是第一次遍历
if (loTail == null)
// 让loHead = e,设置头节点
loHead = e;
else
// 否则,让loTail的next = e
loTail.next = e;
// 最后让loTail = e
loTail = e;
}
/*
其实if 和else 中做的事情是一样的,本质上就是将不需要更新位置的节点加入到loHead为头节点的低位链表中,将需要更新位置的节点加入到hiHead为头结点的高位链表中。
我们看到有loHead和loTail两个Node,loHead为头节点,然后loTail是尾节点,在遍历的时候用来维护loHead,即每次循环,
更新loHead的next。我们来举个例子,比如原来的链表是A->B->C->D->E。
我们这里把->假设成next关系,这五个Node中,只有C的hash & oldCap != 0 ,
然后这个代码执行过程就是:
第一次循环: 先拿到A,把A赋给loHead,然后loTail也是A
第二次循环: 此时e的为B,而且loTail != null,也就是进入上面的else分支,把loTail.next =
B,此时loTail中即A->B,同样反应在loHead中也是A->B,然后把loTail = B
第三次循环: 此时e = C,由于C不满足 (e.hash & oldCap) == 0,进入到了我们下面的else分支,其
实做的事情和当前分支的意思一样,只不过维护的是hiHead和hiTail。
第四次循环: 此时e的为D,loTail != null,进入上面的else分支,把loTail.next =
D,此时loTail中即B->D,同样反应在loHead中也是A->B->D,然后把loTail = D
*/
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 遍历结束,即把table[j]中所有的Node处理完
// 如果loTail不为空,也保证了loHead不为空
if (loTail != null) {
// 此时把loTail的next置空,将低位链表构造完成
loTail.next = null;
// 把loHead放在newTab数组的第j个位置上,也就是这些节点保持在数组中的原位置不变
newTab[j] = loHead;
}
// 同理,只不过hiHead中节点放的位置是j+oldCap
if (hiTail != null) {
hiTail.next = null;
// hiHead链表中的节点都是需要更新位置的节点
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 最后返回newTab
return newTab;
}

(1)最基本的区别HashTable是线程安全的,HashMap是线程不安全的,因为HashTable的每一个方法都使用synchronized关键字修饰。HashTable效率低下,现已不常使用,多使用CurrentHashMap.
(2)HashMap允许key和value为null,而HashTable不允许
jdk8开始链表高度到8、数组长度超过64,链表转换为红黑树,元素以内部类Node结点存在
计算key的hash值,二次hash然后对数组长度取模,对应到数组下标
如果没有产生hash冲突(下标位置没有元素),则直接创建Node数组
如果产生hash冲突,先进行equal比较,相同则取代元素,不同,则判断链表高度插入链表,链表高度达到8,并且数组长度到64则转变为红黑树,长度低于6则将红黑树转回链表
key为null,存在下标0的位置





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有