=================== MapTask ===================
context.write(k, NullWritable.get()); //自定义的map方法的写出,进入
output.write(key, value);
//MapTask727行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082行 map端所有的kv全部写出后会走下面的close方法
close() //MapTask732行
collector.flush() // 溢出刷写方法,MapTask735行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625行,进入
mergeParts(); //合并文件,MapTask1527行,进入
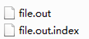
collector.close(); //MapTask739行,收集器关闭,即将进入ReduceTask








 京公网安备 11010802041100号
京公网安备 11010802041100号