昨天晚上遇到一个奇葩的问题, 搞好的环境DataNode启动报错. 报错信息提示的模棱两可,没办法定位原因.
办法,开启远程调试…
注意 : 开启远程调试的代码,必须与本地idea的代码必须保持一致.
修改 服务器上的配置文件 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 增加 环境变量即可.
| 组件 | 环境变量设置 |
|---|---|
| NameNode | export HADOOP_NAMENODE_OPTS="-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=y" |
| DataNode | export HADOOP_DATANODE_OPTS="-agentlib:jdwp=transport=dt_socket,address=9888,server=y,suspend=y" |
| ResourceManager | export YARN_RESOURCEMANAGER_OPTS="-agentlib:jdwp=transport=dt_socket,address=10888,server=y,suspend=y" |
| NodeManager | export YARN_NODEMANAGER_OPTS="-agentlib:jdwp=transport=dt_socket,address=10888,server=y,suspend=y" |
1.编辑服务器上的配置文件[${HADOOP_HOME}/etc/hadoop/hadoop-env.sh`]
随便加上一行[记住端口!!!]:
export HADOOP_DATANODE_OPTS="-agentlib:jdwp=transport=dt_socket,address=9888,server=y,suspend=y"
启动服务即可 [启动完, JVM返现有jdwp的配置,会自动阻塞, 等到idea调试连接.].
因为我要调试的是DataNode .
所以启动命令为:
cd ${HADOOP_HOME}/sbin
# 启动datanode
sh hadoop-daemon.sh start datanode
查看日志
为了便于观察报错信息 . 打开datanode相关的 日志, 使用命令进行查看就可以了.
到这里,服务端配置就完成了.
将与服务器同步的代码导入到idea中, 导入完成, 不编译,不管报错信息…
只要导入到idea , 等idea自己构建完就可以了…
2021-03-27 22:47:51,949 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.lang.RuntimeException: Cannot start secure DataNode due to incorrect config. See https://cwiki.apache.org/confluence/display/HADOOP/Secure+DataNode for details.
at org.apache.hadoop.hdfs.server.datanode.DataNode.checkSecureConfig(DataNode.java:1523)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1376)
at org.apache.hadoop.hdfs.server.datanode.DataNode.(DataNode.java:501)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:2806)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:2714)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:2756)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:2900)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2924)
2021-03-27 22:47:51,959 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.lang.RuntimeException: Cannot start secure DataNode due to incorrect config. See https://cwiki.apache.org/confluence/display/HADOOP/Secure+DataNode for details.
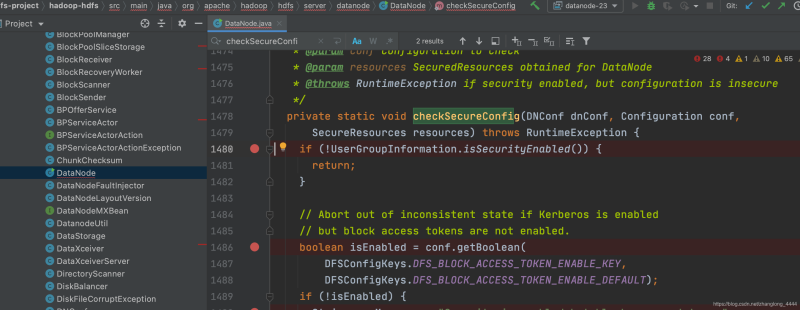
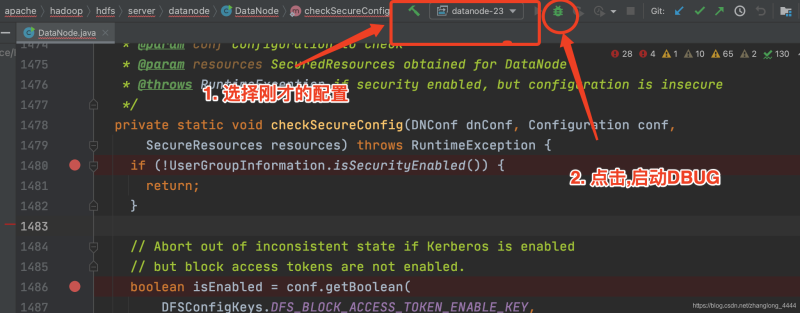
可以看到是 org.apache.hadoop.hdfs.server.datanode.DataNode.checkSecureConfig方法.
所以直接找到代码, 加上断点即可…
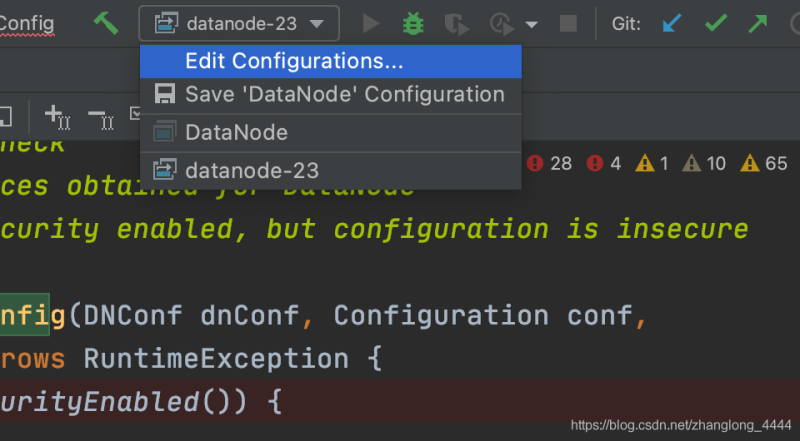
-点击 Edit Configurations....
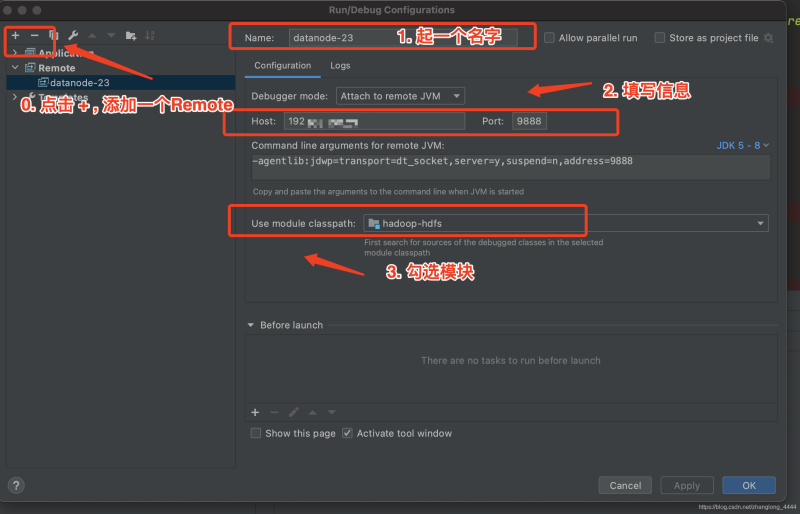
建立远程debug就可以了
主要是端口一定要跟服务端配置的端口要匹配.
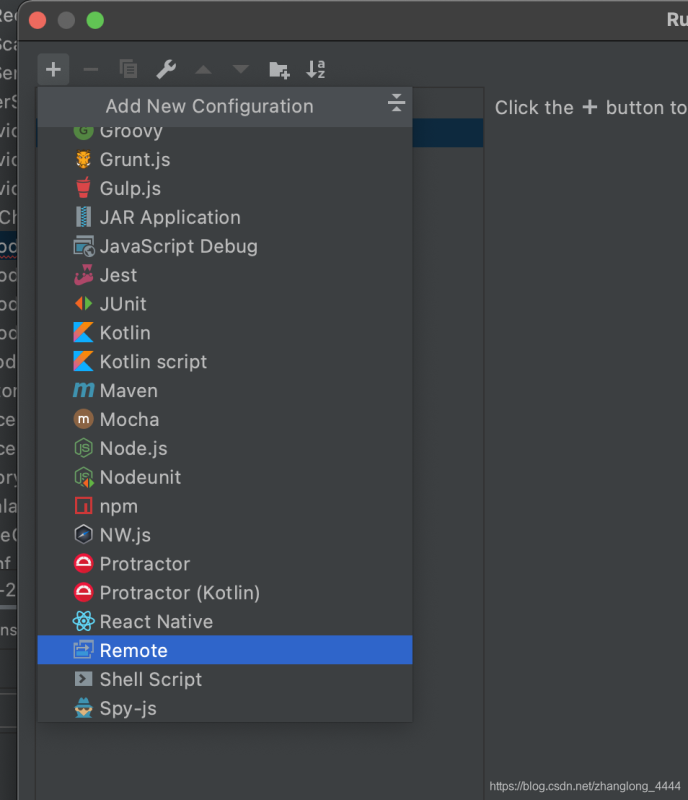
第0步, 选择Remote 的截图.
-选择刚才的配置,启动debug调试即可. 然后就可以等待连接到服务器,进行DEBUG操作了…
参考文章:
https://www.jianshu.com/p/f33fe9bbca17
到此这篇关于Hadoop 使用IntelliJ IDEA 进行远程调试代码的配置方法的文章就介绍到这了,更多相关IDEA 远程调试内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有